

An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment
- PMID: 20844132
- PMCID: PMC2945906
- DOI: 10.1523/JNEUROSCI.0822-10.2010
An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment
Abstract
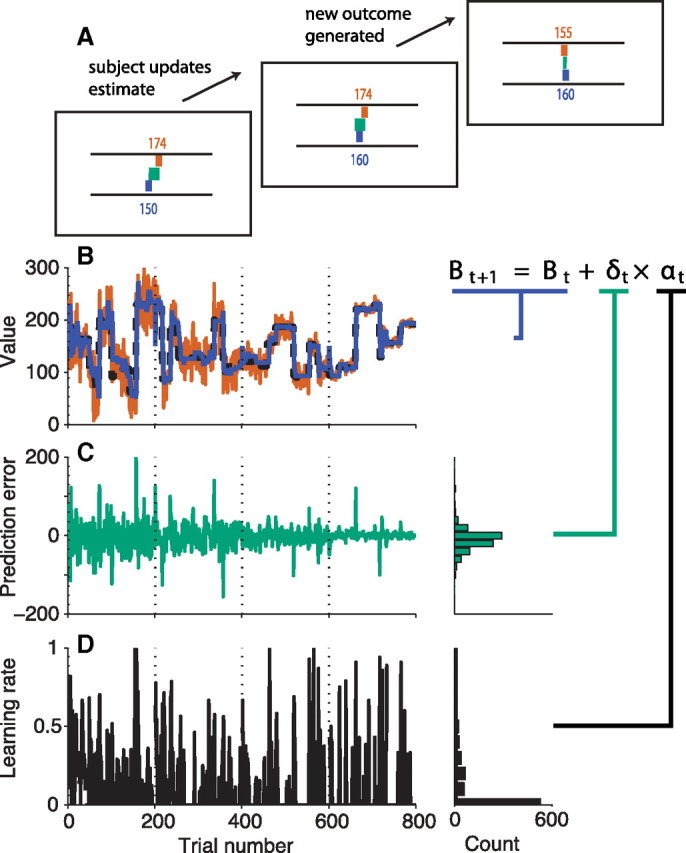
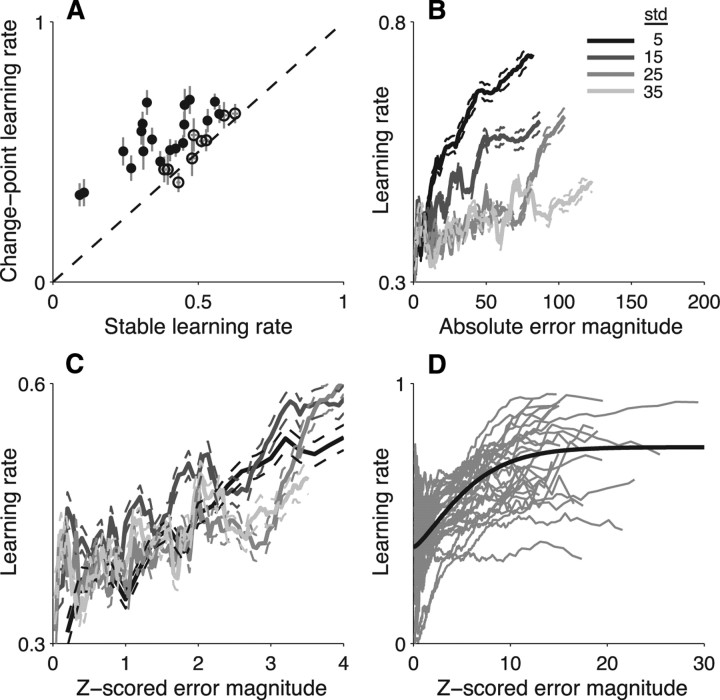
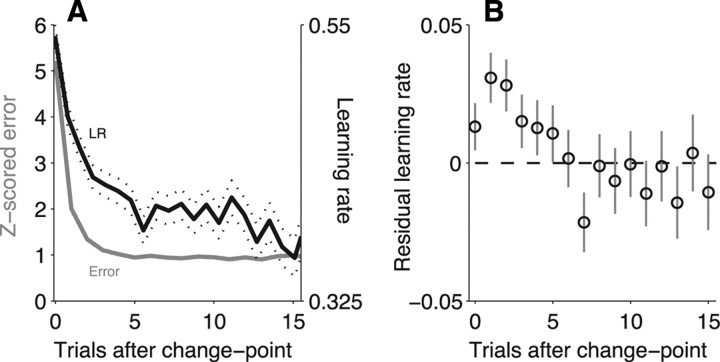
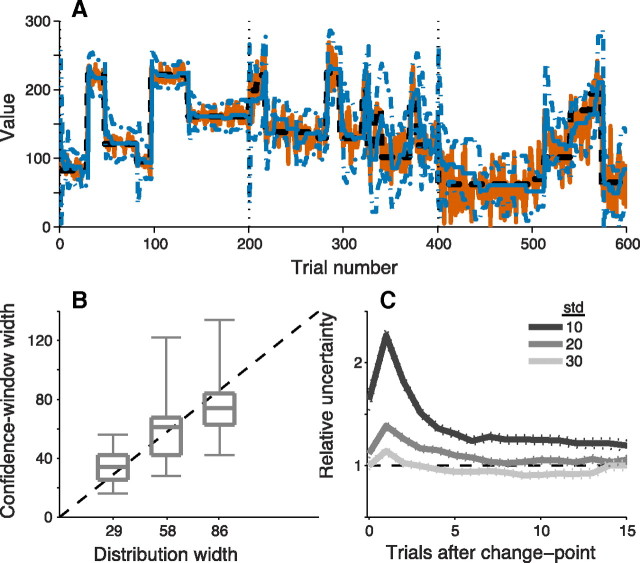
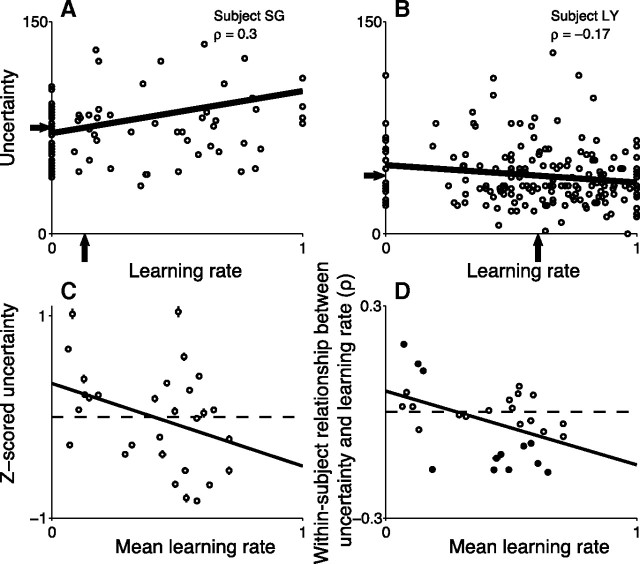
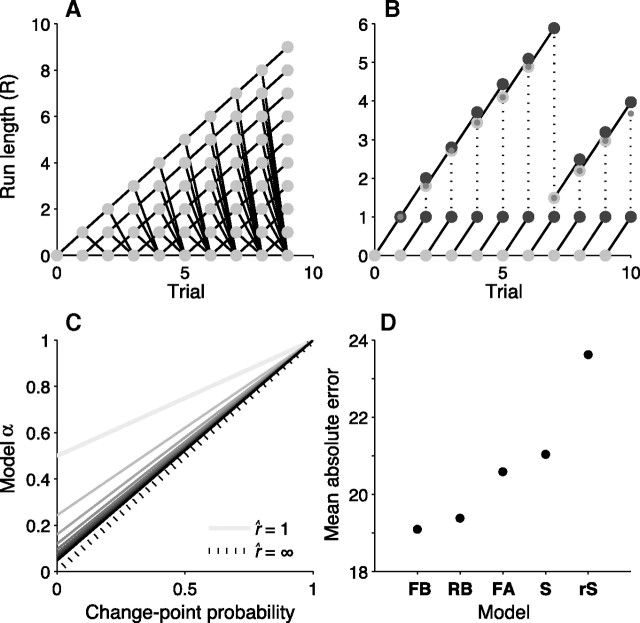
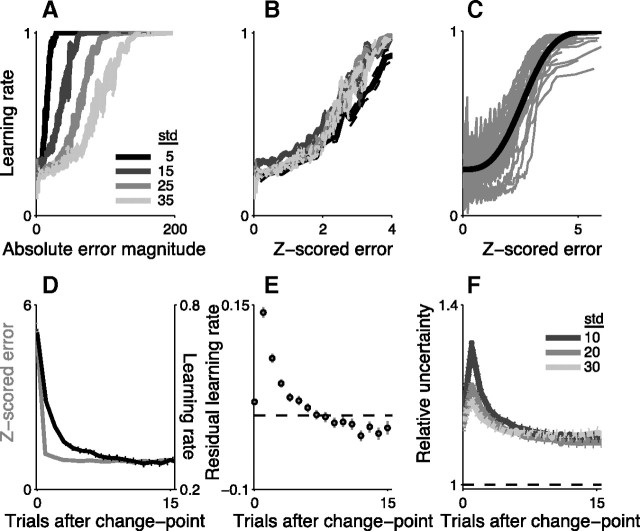
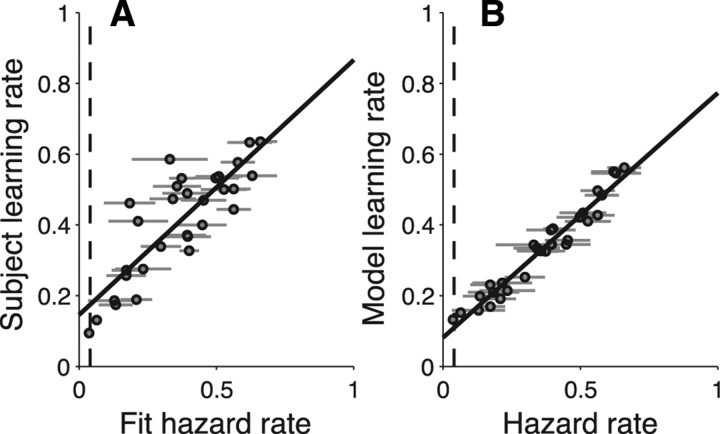
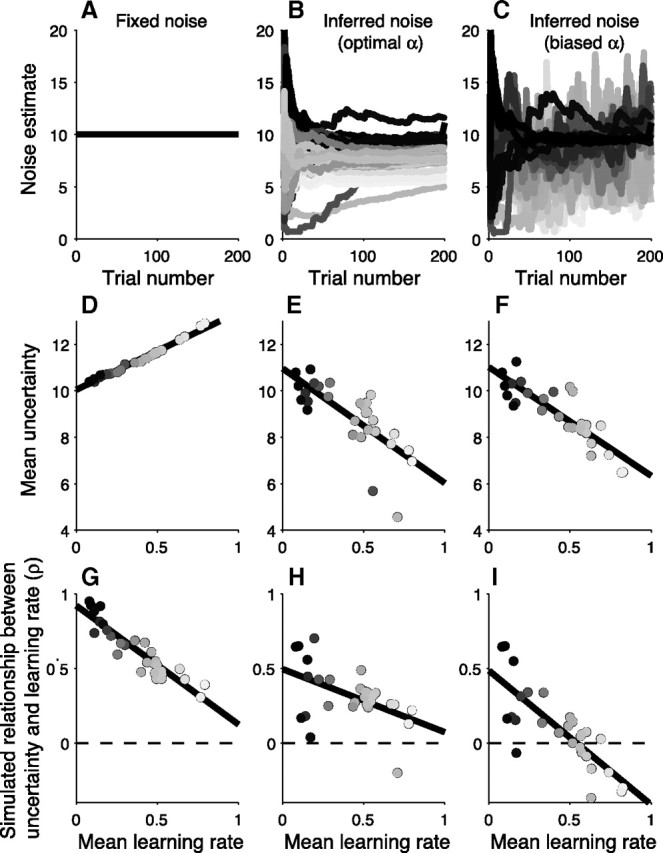
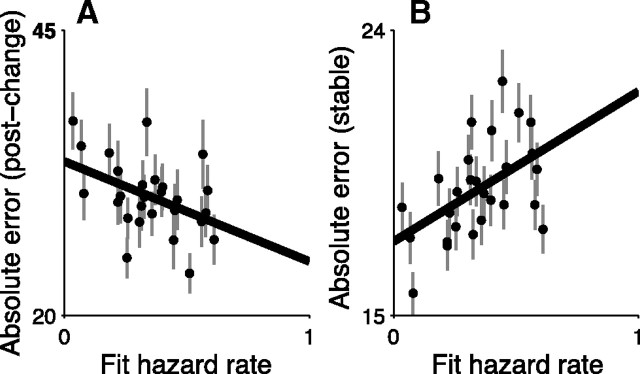
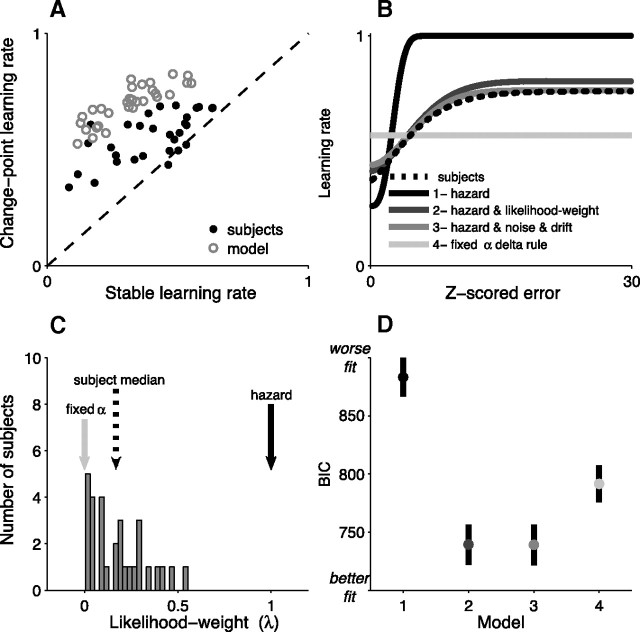
Maintaining appropriate beliefs about variables needed for effective decision making can be difficult in a dynamic environment. One key issue is the amount of influence that unexpected outcomes should have on existing beliefs. In general, outcomes that are unexpected because of a fundamental change in the environment should carry more influence than outcomes that are unexpected because of persistent environmental stochasticity. Here we use a novel task to characterize how well human subjects follow these principles under a range of conditions. We show that the influence of an outcome depends on both the error made in predicting that outcome and the number of similar outcomes experienced previously. We also show that the exact nature of these tendencies varies considerably across subjects. Finally, we show that these patterns of behavior are consistent with a computationally simple reduction of an ideal-observer model. The model adjusts the influence of newly experienced outcomes according to ongoing estimates of uncertainty and the probability of a fundamental change in the process by which outcomes are generated. A prior that quantifies the expected frequency of such environmental changes accounts for individual variability, including a positive relationship between subjective certainty and the degree to which new information influences existing beliefs. The results suggest that the brain adaptively regulates the influence of decision outcomes on existing beliefs using straightforward updating rules that take into account both recent outcomes and prior expectations about higher-order environmental structure.
Figures
References
-
- Adams RP, MacKay DJ. Cambridge, UK: University of Cambridge Technical Report; 2007. Bayesian online changepoint detection.
-
- Behrens TE, Woolrich MW, Walton ME, Rushworth MF. Learning the value of information in an uncertain world. Nat Neurosci. 2007;10:1214–1221. - PubMed
-
- Bruder GE, Keilp JG, Xu H, Shikhman M, Schori E, Gorman JM, Gilliam TC. Catechol-O-methyltransferase (COMT) genotypes and working memory: associations with differing cognitive operations. Biol Psychiatry. 2005;58:901–907. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources