

Selectivity and tolerance ("invariance") both increase as visual information propagates from cortical area V4 to IT
- PMID: 20881116
- PMCID: PMC2975390
- DOI: 10.1523/JNEUROSCI.0179-10.2010
Selectivity and tolerance ("invariance") both increase as visual information propagates from cortical area V4 to IT
Abstract
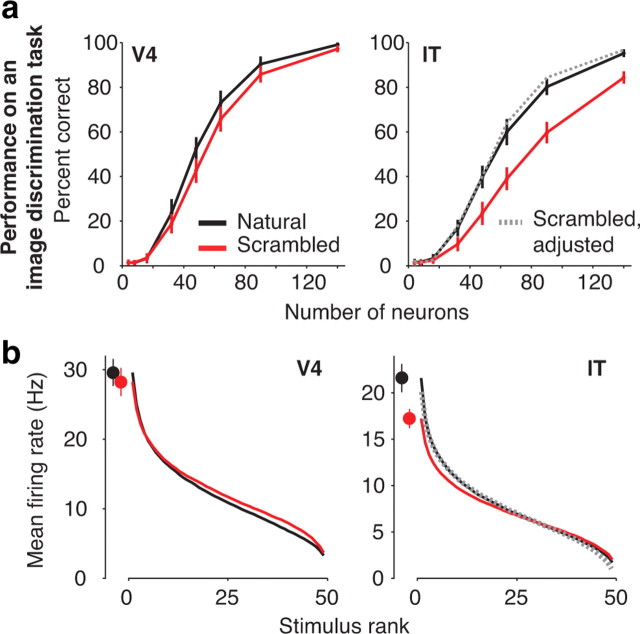
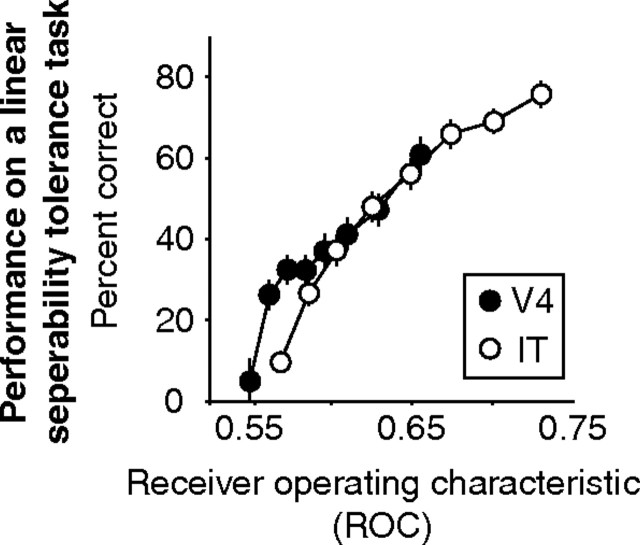
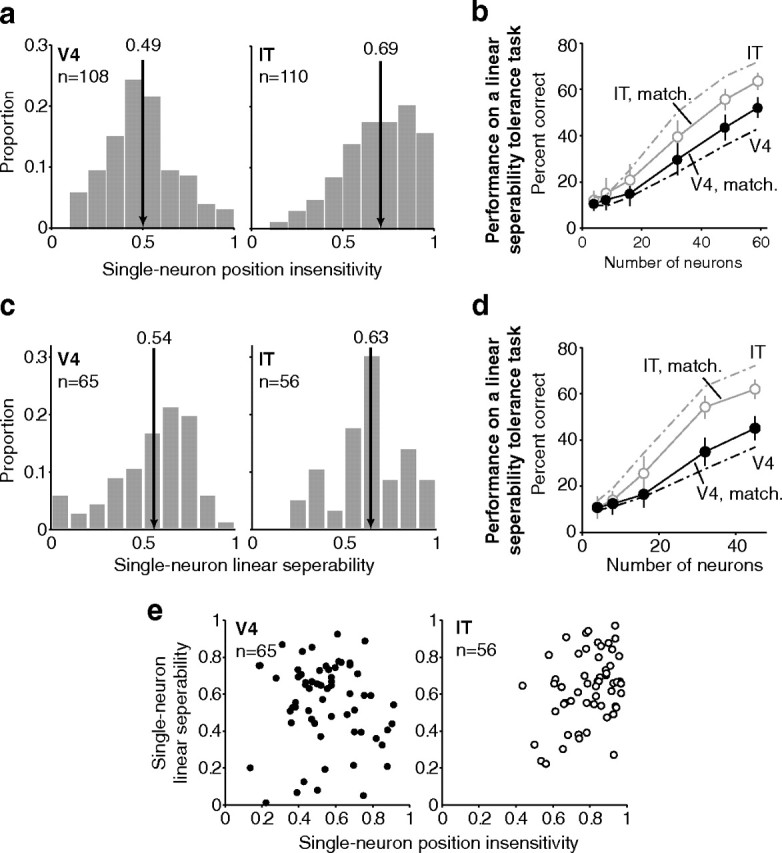
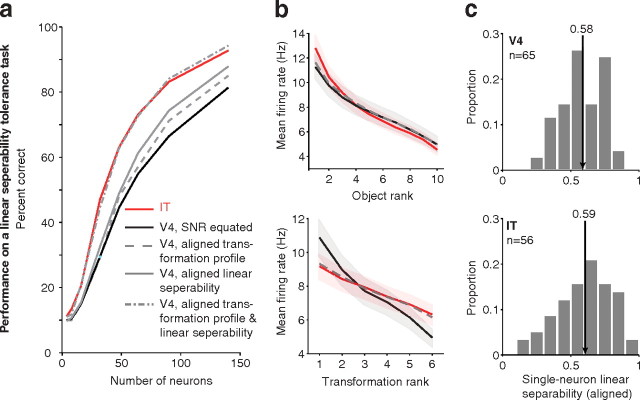
Our ability to recognize objects despite large changes in position, size, and context is achieved through computations that are thought to increase both the shape selectivity and the tolerance ("invariance") of the visual representation at successive stages of the ventral pathway [visual cortical areas V1, V2, and V4 and inferior temporal cortex (IT)]. However, these ideas have proven difficult to test. Here, we consider how well population activity patterns at two stages of the ventral stream (V4 and IT) discriminate between, and generalize across, different images. We found that both V4 and IT encode natural images with similar fidelity, whereas the IT population is much more sensitive to controlled, statistical scrambling of those images. Scrambling sensitivity was proportional to receptive field (RF) size in both V4 and IT, suggesting that, on average, the number of visual feature conjunctions implemented by a V4 or IT neuron is directly related to its RF size. We also found that the IT population could better discriminate between objects across changes in position, scale, and context, thus directly demonstrating a V4-to-IT gain in tolerance. This tolerance gain could be accounted for by both a decrease in single-unit sensitivity to identity-preserving transformations (e.g., an increase in RF size) and an increase in the maintenance of rank-order object selectivity within the RF. These results demonstrate that, as visual information travels from V4 to IT, the population representation is reformatted to become more selective for feature conjunctions and more tolerant to identity preserving transformations, and they reveal the single-unit response properties that underlie that reformatting.
Figures
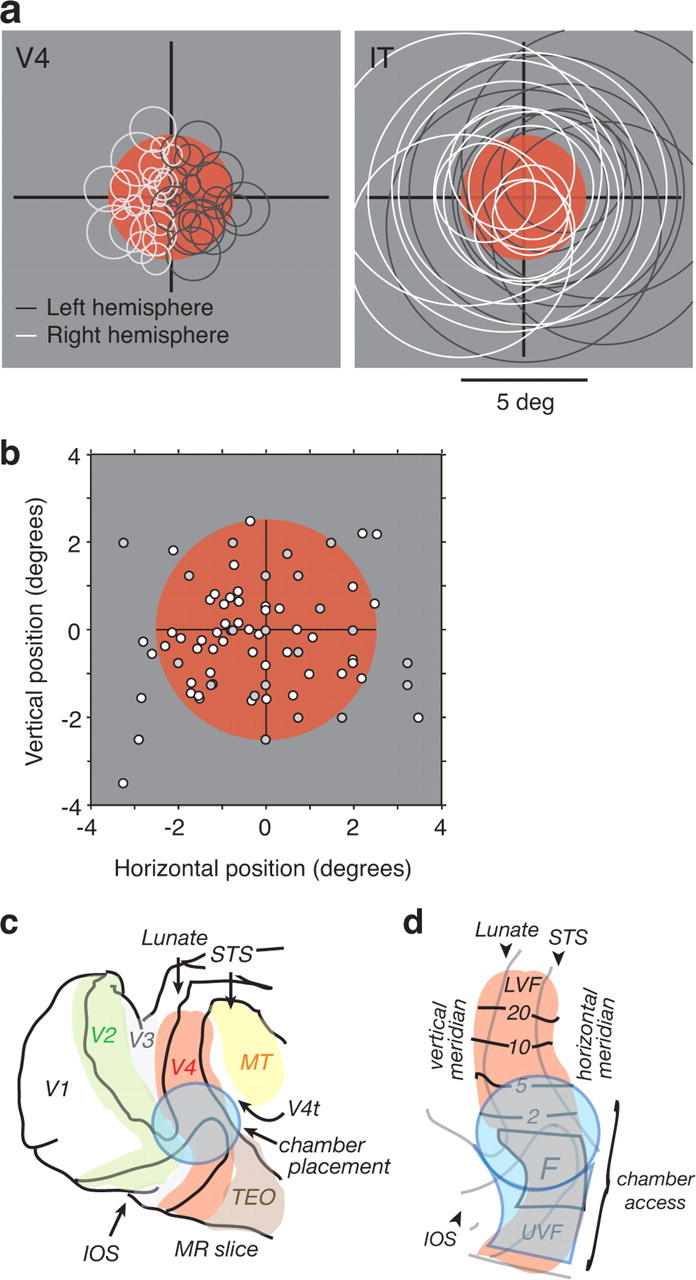
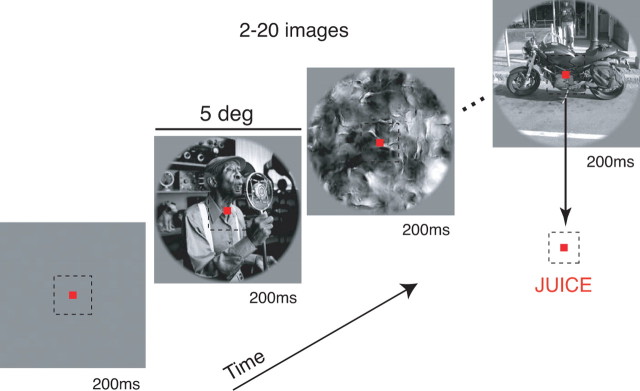

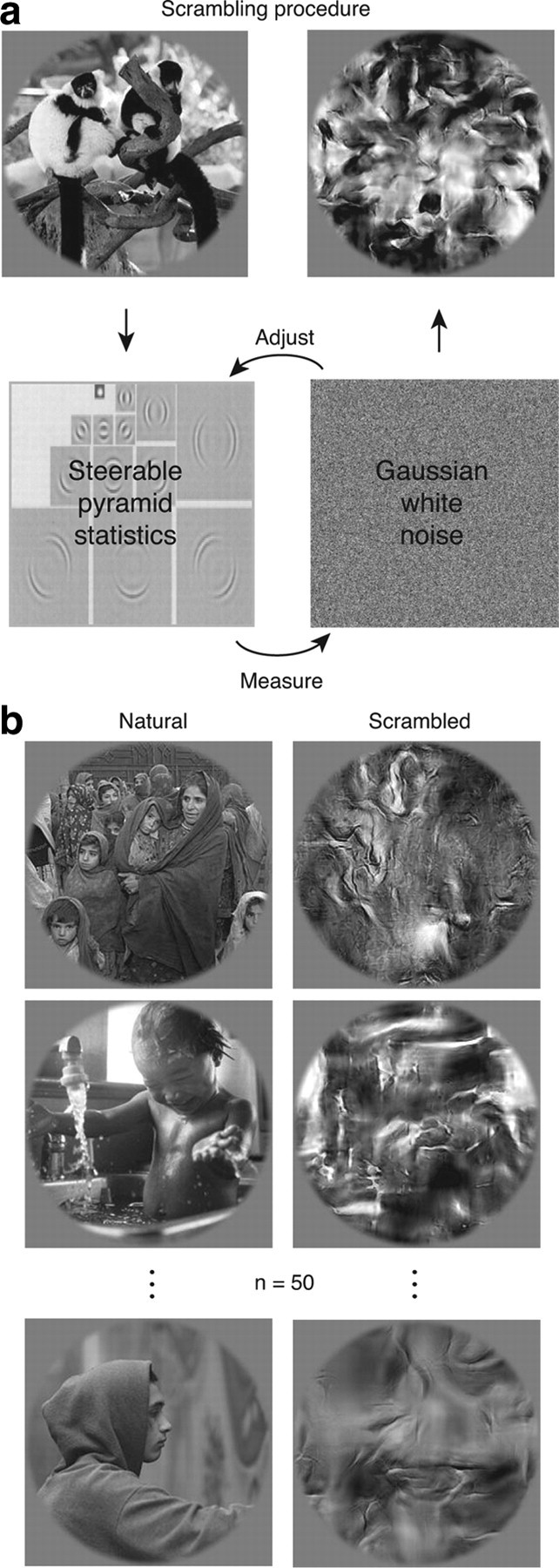
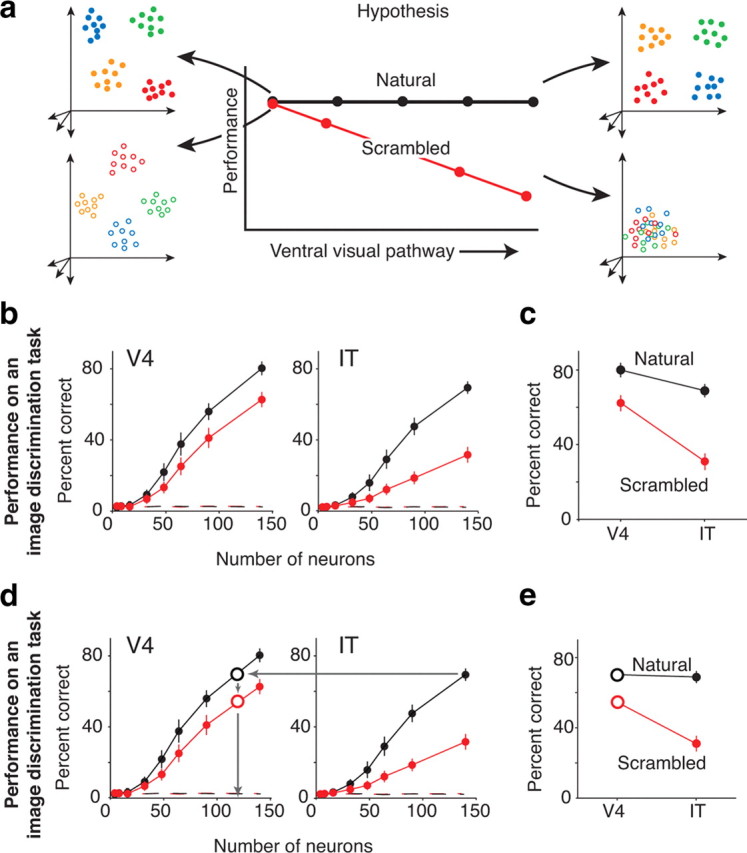
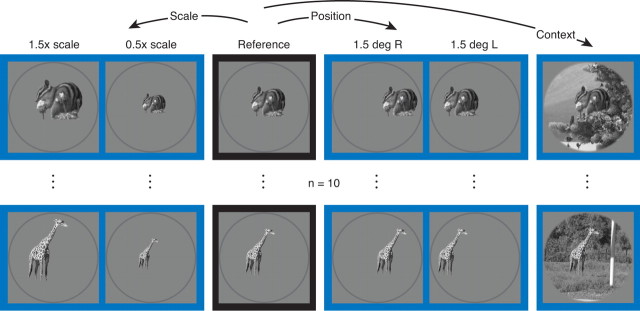
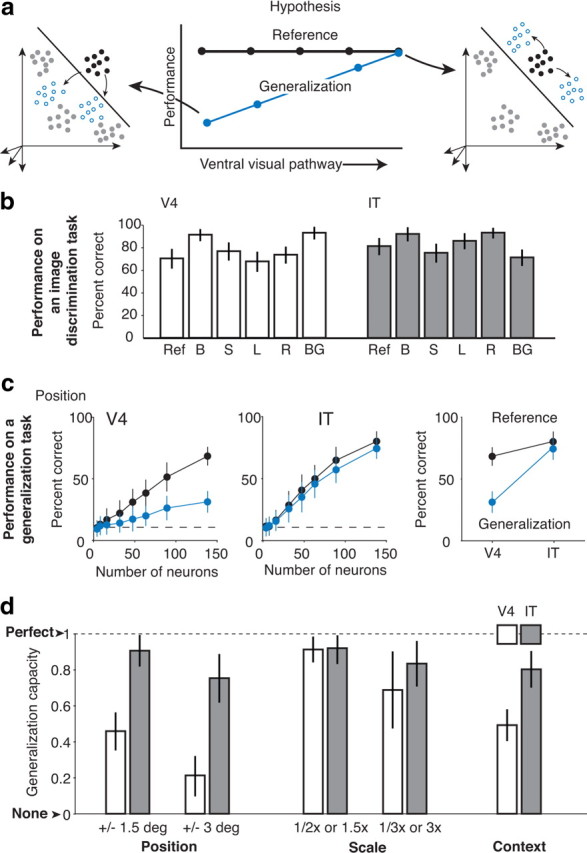
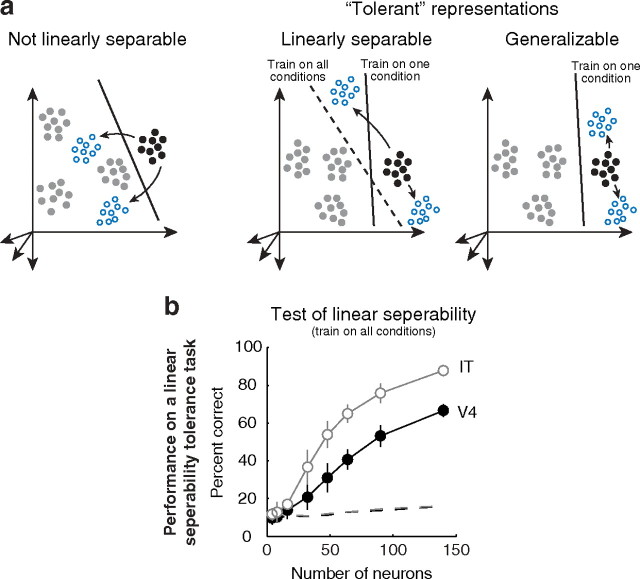
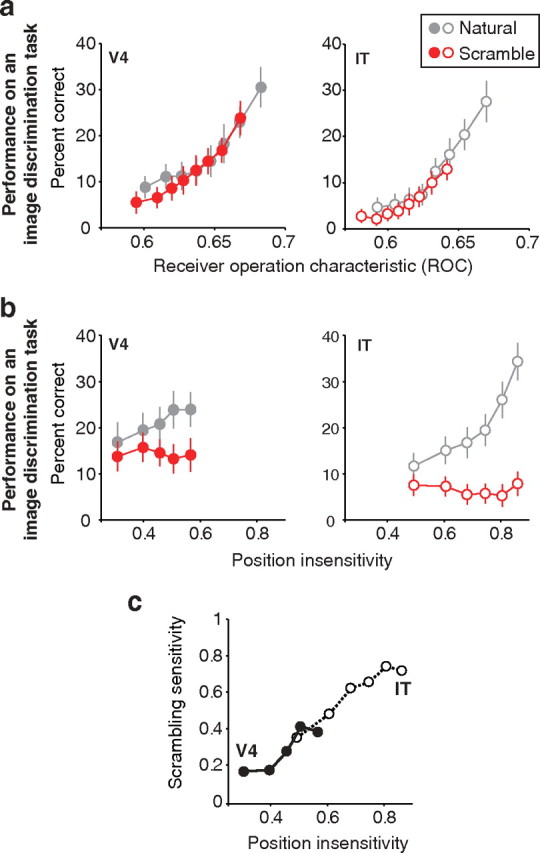
Comment in
-
Unwrapping the ventral stream.J Neurosci. 2011 Feb 16;31(7):2349-51. doi: 10.1523/JNEUROSCI.6191-10.2011. J Neurosci. 2011. PMID: 21325501 Free PMC article. No abstract available.
References
-
- Anzai A, Peng X, Van Essen DC. Neurons in monkey visual area V2 encode combinations of orientations. Nat Neurosci. 2007;10:1313–1321. - PubMed
-
- Baker CI, Behrmann M, Olson CR. Impact of learning on representation of parts and wholes in monkey inferotemporal cortex. Nat Neurosci. 2002;5:1210–1216. - PubMed
-
- Brincat SL, Connor CE. Underlying principles of visual shape selectivity in posterior inferotemporal cortex. Nat Neurosci. 2004;7:880–886. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources