

Relative contribution of off- and on-frequency spectral components of background noise to the masking of unprocessed and vocoded speech
- PMID: 20968378
- PMCID: PMC2981119
- DOI: 10.1121/1.3478845
Relative contribution of off- and on-frequency spectral components of background noise to the masking of unprocessed and vocoded speech
Abstract
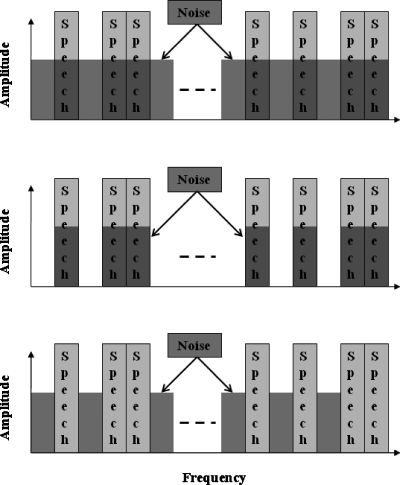
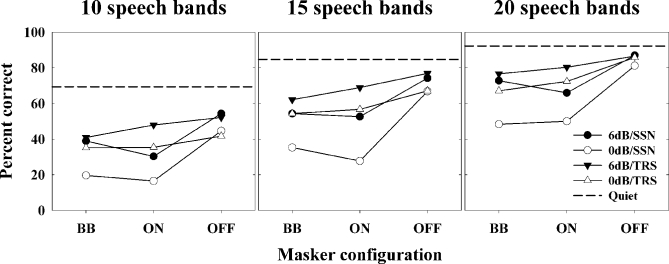
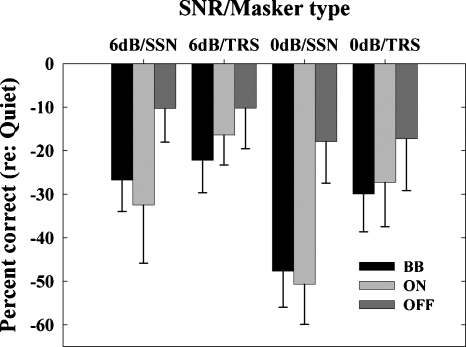
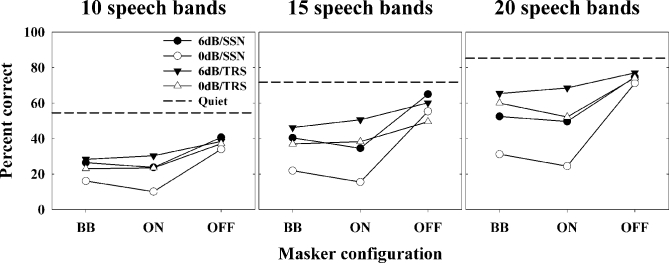
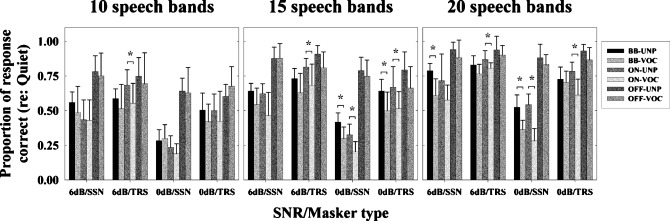
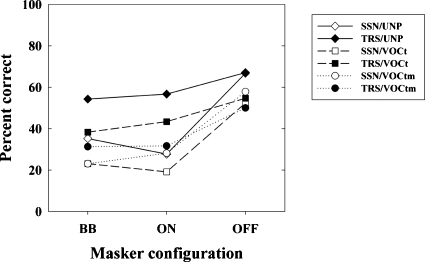
The present study examined the relative influence of the off- and on-frequency spectral components of modulated and unmodulated maskers on consonant recognition. Stimuli were divided into 30 contiguous equivalent rectangular bandwidths. The temporal fine structure (TFS) in each "target" band was either left intact or replaced with tones using vocoder processing. Recognition scores for 10, 15 and 20 target bands randomly located in frequency were obtained in quiet and in the presence of all 30 masker bands, only the off-frequency masker bands, or only the on-frequency masker bands. The amount of masking produced by the on-frequency bands was generally comparable to that produced by the broadband masker. However, the difference between these two conditions was often significant, indicating an influence of the off-frequency masker bands, likely through modulation interference or spectral restoration. Although vocoder processing systematically lead to poorer consonant recognition scores, the deficit observed in noise could often be attributed to that observed in quiet. These data indicate that (i) speech recognition is affected by the off-frequency components of the background and (ii) the nature of the target TFS does not systematically affect speech recognition in noise, especially when energetic masking and/or the number of target bands is limited.
Figures
References
-
- ANSI S3.6-2004 (2004). Specifications for Audiometers (American National Standards Institute, New York: ).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical