

Alignment-free sequence comparison (II): theoretical power of comparison statistics
- PMID: 20973742
- PMCID: PMC3123933
- DOI: 10.1089/cmb.2010.0056
Alignment-free sequence comparison (II): theoretical power of comparison statistics
Abstract
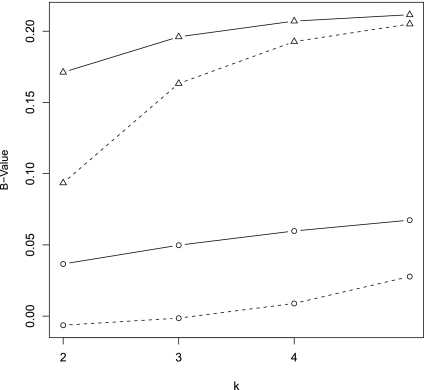
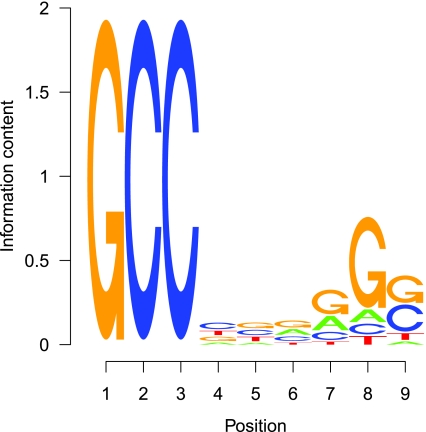
Rapid methods for alignment-free sequence comparison make large-scale comparisons between sequences increasingly feasible. Here we study the power of the statistic D2, which counts the number of matching k-tuples between two sequences, as well as D2*, which uses centralized counts, and D2S, which is a self-standardized version, both from a theoretical viewpoint and numerically, providing an easy to use program. The power is assessed under two alternative hidden Markov models; the first one assumes that the two sequences share a common motif, whereas the second model is a pattern transfer model; the null model is that the two sequences are composed of independent and identically distributed letters and they are independent. Under the first alternative model, the means of the tuple counts in the individual sequences change, whereas under the second alternative model, the marginal means are the same as under the null model. Using the limit distributions of the count statistics under the null and the alternative models, we find that generally, asymptotically D2S has the largest power, followed by D2*, whereas the power of D2 can even be zero in some cases. In contrast, even for sequences of length 140,000 bp, in simulations D2* generally has the largest power. Under the first alternative model of a shared motif, the power of D2*approaches 100% when sufficiently many motifs are shared, and we recommend the use of D2* for such practical applications. Under the second alternative model of pattern transfer,the power for all three count statistics does not increase with sequence length when the sequence is sufficiently long, and hence none of the three statistics under consideration canbe recommended in such a situation. We illustrate the approach on 323 transcription factor binding motifs with length at most 10 from JASPAR CORE (October 12, 2009 version),verifying that D2* is generally more powerful than D2. The program to calculate the power of D2, D2* and D2S can be downloaded from http://meta.cmb.usc.edu/d2. Supplementary Material is available at www.liebertonline.com/cmb.
Figures


References
-
- Burden C.J. Kantorovitz M.R. Wilson S.R. Approximate word matches between two random sequences. Ann. Appl. Probab. 2006;18:1–21.
-
- Forêt S. Wilson S.R. Burden C.J. Empirical distribution of k-word matches in biological sequences. Pattern Recogn. 2009a;42:539–548.
-
- Forêt S. Wilson S.R. Burden C.J. Characterizing the D2 statistic: word matches in biological sequences. Stat. Appl. Genet. Mol. Biol. 2009b;8:43. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
