

Optimal habits can develop spontaneously through sensitivity to local cost
- PMID: 20974967
- PMCID: PMC2996716
- DOI: 10.1073/pnas.1013470107
Optimal habits can develop spontaneously through sensitivity to local cost
Abstract
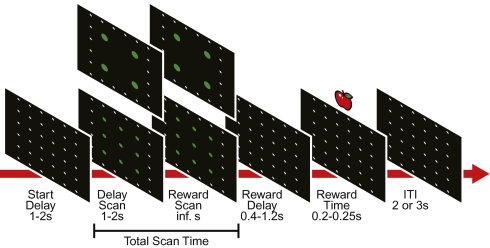
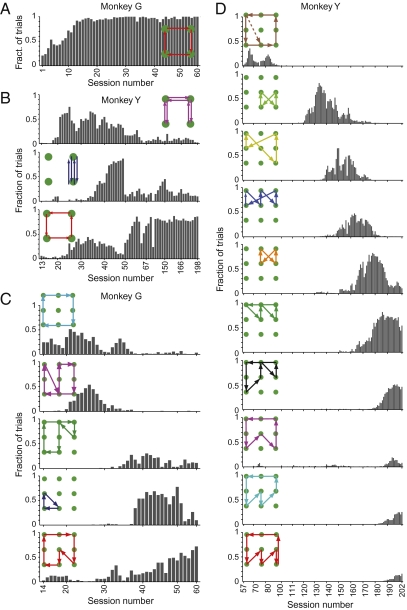
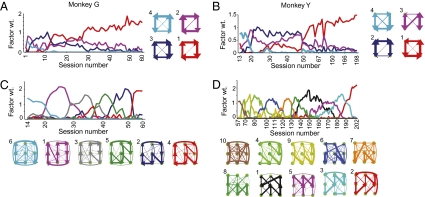
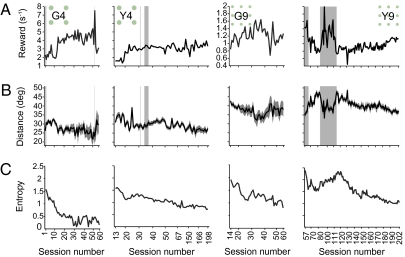
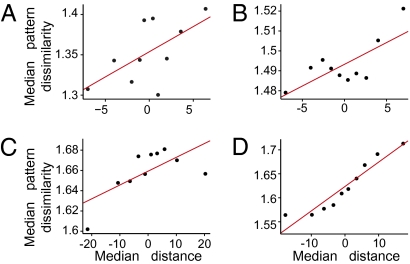
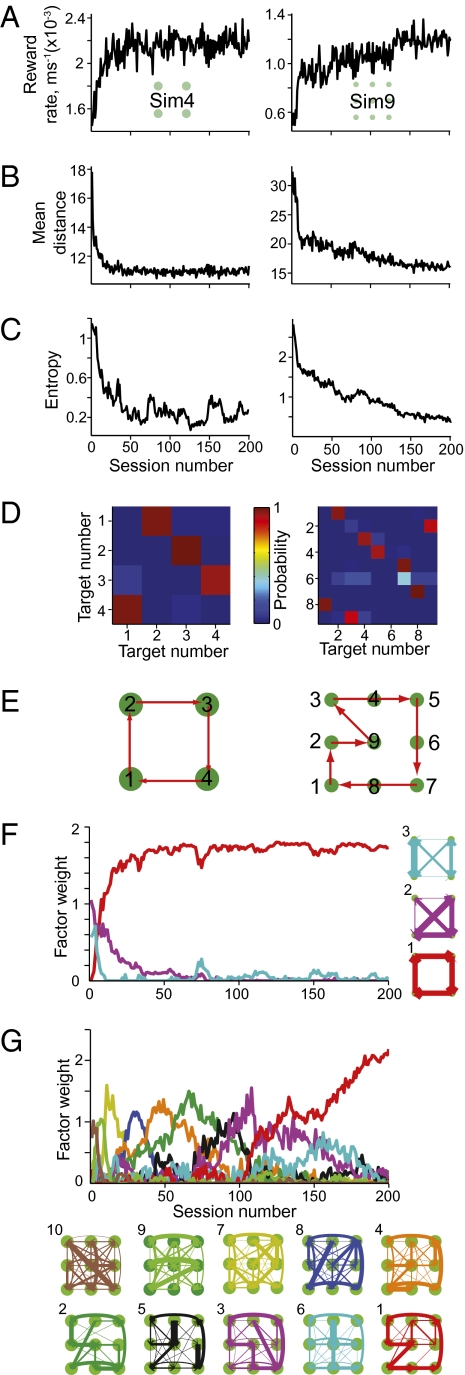
Habits and rituals are expressed universally across animal species. These behaviors are advantageous in allowing sequential behaviors to be performed without cognitive overload, and appear to rely on neural circuits that are relatively benign but vulnerable to takeover by extreme contexts, neuropsychiatric sequelae, and processes leading to addiction. Reinforcement learning (RL) is thought to underlie the formation of optimal habits. However, this theoretic formulation has principally been tested experimentally in simple stimulus-response tasks with relatively few available responses. We asked whether RL could also account for the emergence of habitual action sequences in realistically complex situations in which no repetitive stimulus-response links were present and in which many response options were present. We exposed naïve macaque monkeys to such experimental conditions by introducing a unique free saccade scan task. Despite the highly uncertain conditions and no instruction, the monkeys developed a succession of stereotypical, self-chosen saccade sequence patterns. Remarkably, these continued to morph for months, long after session-averaged reward and cost (eye movement distance) reached asymptote. Prima facie, these continued behavioral changes appeared to challenge RL. However, trial-by-trial analysis showed that pattern changes on adjacent trials were predicted by lowered cost, and RL simulations that reduced the cost reproduced the monkeys' behavior. Ultimately, the patterns settled into stereotypical saccade sequences that minimized the cost of obtaining the reward on average. These findings suggest that brain mechanisms underlying the emergence of habits, and perhaps unwanted repetitive behaviors in clinical disorders, could follow RL algorithms capturing extremely local explore/exploit tradeoffs.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
Comment in
-
Learning optimal strategies in complex environments.Proc Natl Acad Sci U S A. 2010 Nov 23;107(47):20151-2. doi: 10.1073/pnas.1014954107. Epub 2010 Nov 15. Proc Natl Acad Sci U S A. 2010. PMID: 21078996 Free PMC article. No abstract available.
Similar articles
-
Habit Learning by Naive Macaques Is Marked by Response Sharpening of Striatal Neurons Representing the Cost and Outcome of Acquired Action Sequences.Neuron. 2015 Aug 19;87(4):853-68. doi: 10.1016/j.neuron.2015.07.019. Neuron. 2015. PMID: 26291166 Free PMC article.
-
Entropy-based metrics for predicting choice behavior based on local response to reward.Nat Commun. 2021 Nov 12;12(1):6567. doi: 10.1038/s41467-021-26784-w. Nat Commun. 2021. PMID: 34772943 Free PMC article.
-
Habits, action sequences and reinforcement learning.Eur J Neurosci. 2012 Apr;35(7):1036-51. doi: 10.1111/j.1460-9568.2012.08050.x. Eur J Neurosci. 2012. PMID: 22487034 Free PMC article. Review.
-
Motor System-Dependent Effects of Amygdala and Ventral Striatum Lesions on Explore-Exploit Behaviors.J Neurosci. 2024 Jan 31;44(5):e1206232023. doi: 10.1523/JNEUROSCI.1206-23.2023. J Neurosci. 2024. PMID: 38296647 Free PMC article.
-
Substance use is associated with reduced devaluation sensitivity.Cogn Affect Behav Neurosci. 2019 Feb;19(1):40-55. doi: 10.3758/s13415-018-0638-9. Cogn Affect Behav Neurosci. 2019. PMID: 30377929 Free PMC article. Review.
Cited by
-
Embodied and embedded ecological rationality: A common vertebrate mechanism for action selection underlies cognition and heuristic decision-making in humans.Front Psychol. 2022 Nov 17;13:841972. doi: 10.3389/fpsyg.2022.841972. eCollection 2022. Front Psychol. 2022. PMID: 36467131 Free PMC article. Review.
-
Habit Learning by Naive Macaques Is Marked by Response Sharpening of Striatal Neurons Representing the Cost and Outcome of Acquired Action Sequences.Neuron. 2015 Aug 19;87(4):853-68. doi: 10.1016/j.neuron.2015.07.019. Neuron. 2015. PMID: 26291166 Free PMC article.
-
Goal-oriented searching mediated by ventral hippocampus early in trial-and-error learning.Nat Neurosci. 2012 Nov;15(11):1563-71. doi: 10.1038/nn.3224. Epub 2012 Sep 23. Nat Neurosci. 2012. PMID: 23001061
-
Hierarchical Reinforcement Learning, Sequential Behavior, and the Dorsal Frontostriatal System.J Cogn Neurosci. 2022 Jul 1;34(8):1307-1325. doi: 10.1162/jocn_a_01869. J Cogn Neurosci. 2022. PMID: 35579977 Free PMC article. Review.
-
Striosomes control dopamine via dual pathways paralleling canonical basal ganglia circuits.Curr Biol. 2024 Nov 18;34(22):5263-5283.e8. doi: 10.1016/j.cub.2024.09.070. Epub 2024 Oct 23. Curr Biol. 2024. PMID: 39447573
References
-
- Sutton RS, Barto AG. Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press; 1998.
-
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. - PubMed
-
- Samejima K, Ueda Y, Doya K, Kimura M. Representation of action-specific reward values in the striatum. Science. 2005;310:1337–1340. - PubMed
-
- Morris G, Nevet A, Arkadir D, Vaadia E, Bergman H. Midbrain dopamine neurons encode decisions for future action. Nat Neurosci. 2006;9:1057–1063. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
