

Use of structural DNA properties for the prediction of transcription-factor binding sites in Escherichia coli
- PMID: 21051340
- PMCID: PMC3025552
- DOI: 10.1093/nar/gkq1071
Use of structural DNA properties for the prediction of transcription-factor binding sites in Escherichia coli
Abstract
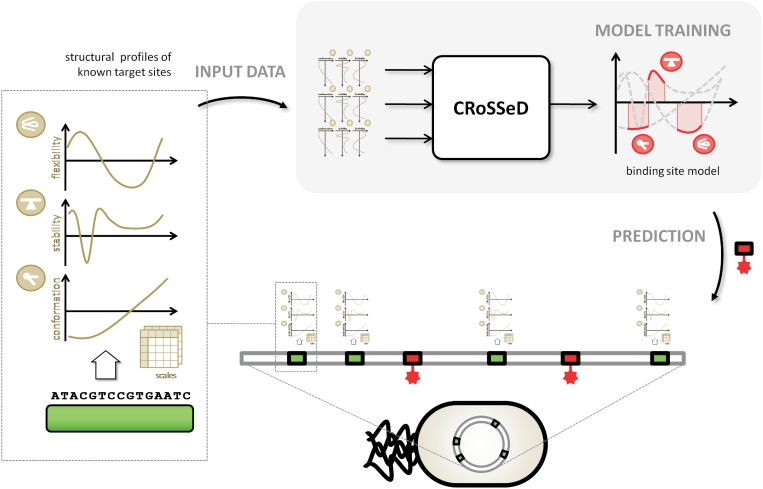
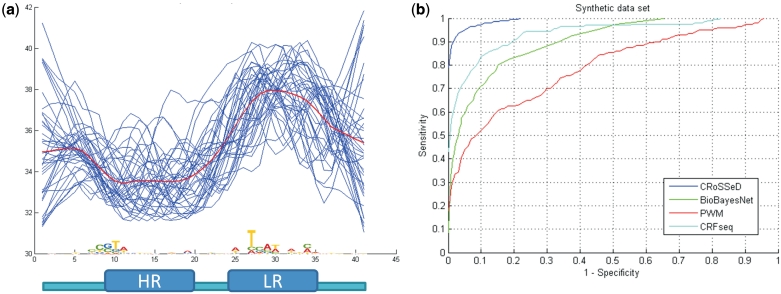
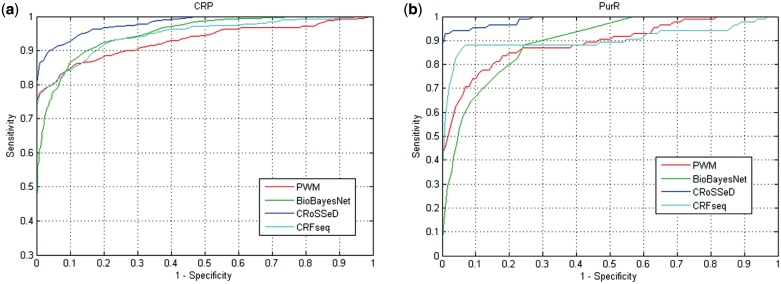
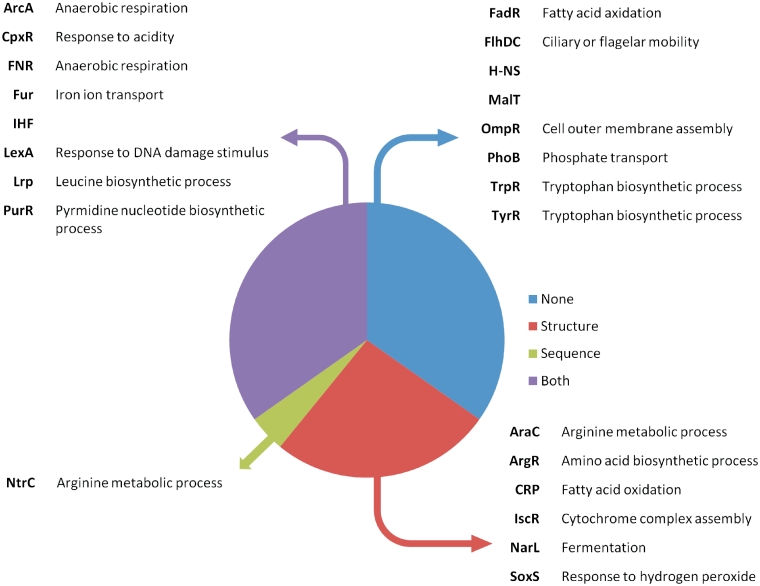
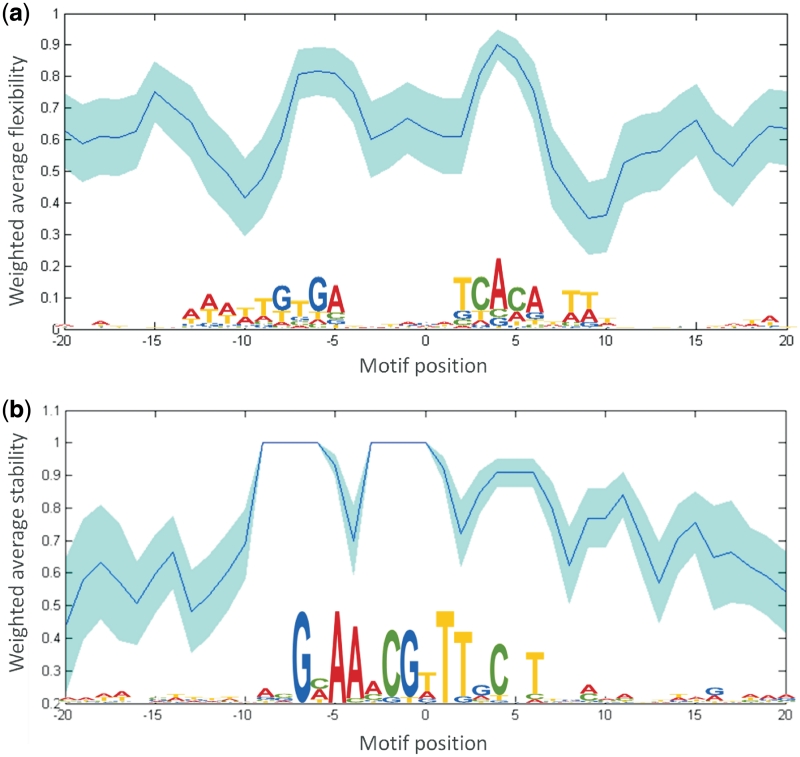
Recognition of genomic binding sites by transcription factors can occur through base-specific recognition, or by recognition of variations within the structure of the DNA macromolecule. In this article, we investigate what information can be retrieved from local DNA structural properties that is relevant to transcription factor binding and that cannot be captured by the nucleotide sequence alone. More specifically, we explore the benefit of employing the structural characteristics of DNA to create binding-site models that encompass indirect recognition for the Escherichia coli model organism. We developed a novel methodology [Conditional Random fields of Smoothed Structural Data (CRoSSeD)], based on structural scales and conditional random fields to model and predict regulator binding sites. The value of relying on local structural-DNA properties is demonstrated by improved classifier performance on a large number of biological datasets, and by the detection of novel binding sites which could be validated by independent data sources, and which could not be identified using sequence data alone. We further show that the CRoSSeD-binding-site models can be related to the actual molecular mechanisms of the transcription factor DNA binding, and thus cannot only be used for prediction of novel sites, but might also give valuable insights into unknown binding mechanisms of transcription factors.
Figures
Similar articles
-
SoxS, an activator of superoxide stress genes in Escherichia coli. Purification and interaction with DNA.J Biol Chem. 1994 Jul 15;269(28):18371-7. J Biol Chem. 1994. PMID: 8034583
-
Using sequence-specific chemical and structural properties of DNA to predict transcription factor binding sites.PLoS Comput Biol. 2010 Nov 18;6(11):e1001007. doi: 10.1371/journal.pcbi.1001007. PLoS Comput Biol. 2010. PMID: 21124945 Free PMC article.
-
Systematic mutagenesis of the DNA binding sites for SoxS in the Escherichia coli zwf and fpr promoters: identifying nucleotides required for DNA binding and transcription activation.Mol Microbiol. 2001 Jun;40(5):1141-54. doi: 10.1046/j.1365-2958.2001.02456.x. Mol Microbiol. 2001. PMID: 11401718
-
The hierarchic network of metal-response transcription factors in Escherichia coli.Biosci Biotechnol Biochem. 2014;78(5):737-47. doi: 10.1080/09168451.2014.915731. Epub 2014 Jun 17. Biosci Biotechnol Biochem. 2014. PMID: 25035972 Review.
-
Leucine-responsive regulatory protein: a global regulator of gene expression in E. coli.Annu Rev Microbiol. 1995;49:747-75. doi: 10.1146/annurev.mi.49.100195.003531. Annu Rev Microbiol. 1995. PMID: 8561478 Review.
Cited by
-
A flexible integrative approach based on random forest improves prediction of transcription factor binding sites.Nucleic Acids Res. 2012 Aug;40(14):e106. doi: 10.1093/nar/gks283. Epub 2012 Apr 5. Nucleic Acids Res. 2012. PMID: 22492513 Free PMC article.
-
Deconvolving the recognition of DNA shape from sequence.Cell. 2015 Apr 9;161(2):307-18. doi: 10.1016/j.cell.2015.02.008. Epub 2015 Apr 2. Cell. 2015. PMID: 25843630 Free PMC article.
-
Improved predictions of transcription factor binding sites using physicochemical features of DNA.Nucleic Acids Res. 2012 Dec;40(22):e175. doi: 10.1093/nar/gks771. Epub 2012 Aug 25. Nucleic Acids Res. 2012. PMID: 22923524 Free PMC article.
-
Expression divergence between Escherichia coli and Salmonella enterica serovar Typhimurium reflects their lifestyles.Mol Biol Evol. 2013 Jun;30(6):1302-14. doi: 10.1093/molbev/mst029. Epub 2013 Feb 20. Mol Biol Evol. 2013. PMID: 23427276 Free PMC article.
-
An improved systematic approach to predicting transcription factor target genes using support vector machine.PLoS One. 2014 Apr 17;9(4):e94519. doi: 10.1371/journal.pone.0094519. eCollection 2014. PLoS One. 2014. PMID: 24743548 Free PMC article.
References
-
- Stormo GD. DNA binding sites: representation and discovery. Bioinformatics. 2000;16:16–23. - PubMed
-
- Gromiha MM, Siebers JG, Selvaraj S, Kono H, Sarai A. Role of inter and intramolecular interactions in protein-DNA recognition. Gene. 2005;364:108–113. - PubMed
-
- Kono H, Sarai A. Structure-based prediction of DNA target sites by regulatory proteins. Proteins. 1999;35:114–131. - PubMed
