

The Text-mining based PubChem Bioassay neighboring analysis
- PMID: 21059237
- PMCID: PMC3098095
- DOI: 10.1186/1471-2105-11-549
The Text-mining based PubChem Bioassay neighboring analysis
Abstract
Background: In recent years, the number of High Throughput Screening (HTS) assays deposited in PubChem has grown quickly. As a result, the volume of both the structured information (i.e. molecular structure, bioactivities) and the unstructured information (such as descriptions of bioassay experiments), has been increasing exponentially. As a result, it has become even more demanding and challenging to efficiently assemble the bioactivity data by mining the huge amount of information to identify and interpret the relationships among the diversified bioassay experiments. In this work, we propose a text-mining based approach for bioassay neighboring analysis from the unstructured text descriptions contained in the PubChem BioAssay database.
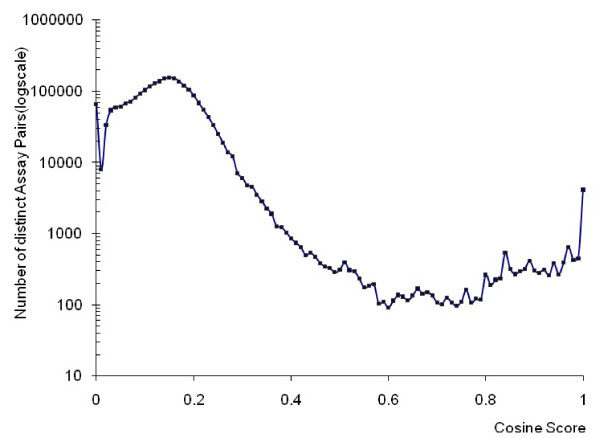
Results: The neighboring analysis is achieved by evaluating the cosine scores of each bioassay pair and fraction of overlaps among the human-curated neighbors. Our results from the cosine score distribution analysis and assay neighbor clustering analysis on all PubChem bioassays suggest that strong correlations among the bioassays can be identified from their conceptual relevance. A comparison with other existing assay neighboring methods suggests that the text-mining based bioassay neighboring approach provides meaningful linkages among the PubChem bioassays, and complements the existing methods by identifying additional relationships among the bioassay entries.
Conclusions: The text-mining based bioassay neighboring analysis is efficient for correlating bioassays and studying different aspects of a biological process, which are otherwise difficult to achieve by existing neighboring procedures due to the lack of specific annotations and structured information. It is suggested that the text-mining based bioassay neighboring analysis can be used as a standalone or as a complementary tool for the PubChem bioassay neighboring process to enable efficient integration of assay results and generate hypotheses for the discovery of bioactivities of the tested reagents.
Figures
Similar articles
-
Classification and analysis of a large collection of in vivo bioassay descriptions.PLoS Comput Biol. 2017 Jul 5;13(7):e1005641. doi: 10.1371/journal.pcbi.1005641. eCollection 2017 Jul. PLoS Comput Biol. 2017. PMID: 28678787 Free PMC article.
-
PubChem's BioAssay Database.Nucleic Acids Res. 2012 Jan;40(Database issue):D400-12. doi: 10.1093/nar/gkr1132. Epub 2011 Dec 2. Nucleic Acids Res. 2012. PMID: 22140110 Free PMC article.
-
Using the BioAssay Ontology for analyzing high-throughput screening data.J Biomol Screen. 2015 Mar;20(3):402-15. doi: 10.1177/1087057114563493. Epub 2014 Dec 15. J Biomol Screen. 2015. PMID: 25512330
-
Big data in chemical toxicity research: the use of high-throughput screening assays to identify potential toxicants.Chem Res Toxicol. 2014 Oct 20;27(10):1643-51. doi: 10.1021/tx500145h. Epub 2014 Sep 16. Chem Res Toxicol. 2014. PMID: 25195622 Free PMC article. Review.
-
Computational polypharmacology with text mining and ontologies.Curr Pharm Biotechnol. 2011 Mar 1;12(3):449-57. doi: 10.2174/138920111794480624. Curr Pharm Biotechnol. 2011. PMID: 21133848 Review.
Cited by
-
Sequence based prediction of DNA-binding proteins based on hybrid feature selection using random forest and Gaussian naïve Bayes.PLoS One. 2014 Jan 24;9(1):e86703. doi: 10.1371/journal.pone.0086703. eCollection 2014. PLoS One. 2014. PMID: 24475169 Free PMC article.
-
ACTG1 and TLR3 are biomarkers for alcohol-associated hepatocellular carcinoma.Oncol Lett. 2019 Feb;17(2):1714-1722. doi: 10.3892/ol.2018.9757. Epub 2018 Nov 26. Oncol Lett. 2019. PMID: 30675230 Free PMC article.
-
Differential protein-coding gene and long noncoding RNA expression in smoking-related lung squamous cell carcinoma.Thorac Cancer. 2017 Nov;8(6):672-681. doi: 10.1111/1759-7714.12510. Epub 2017 Sep 26. Thorac Cancer. 2017. PMID: 28949095 Free PMC article.
-
Cheminformatics and artificial intelligence for accelerating agrochemical discovery.Front Chem. 2023 Nov 29;11:1292027. doi: 10.3389/fchem.2023.1292027. eCollection 2023. Front Chem. 2023. PMID: 38093816 Free PMC article. Review.
-
An efficient algorithm coupled with synthetic minority over-sampling technique to classify imbalanced PubChem BioAssay data.Anal Chim Acta. 2014 Jan 2;806:117-27. doi: 10.1016/j.aca.2013.10.050. Epub 2013 Nov 6. Anal Chim Acta. 2014. PMID: 24331047 Free PMC article.
References
-
- Shatkay H, Edwards S, Wilbur WJ, Boguski M. Genes, Themes and Microarrays: Using information retrieval for large-scale gene analysis. Proc of the Int Conf on Intelligent Systems for Molecular Biology: 2000. 2000. pp. 317–328. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
