

Semi-automatic semantic annotation of PubMed queries: a study on quality, efficiency, satisfaction
- PMID: 21094696
- PMCID: PMC3063330
- DOI: 10.1016/j.jbi.2010.11.001
Semi-automatic semantic annotation of PubMed queries: a study on quality, efficiency, satisfaction
Abstract
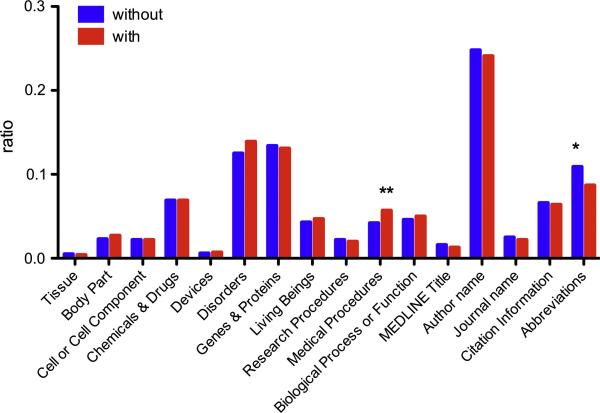
Information processing algorithms require significant amounts of annotated data for training and testing. The availability of such data is often hindered by the complexity and high cost of production. In this paper, we investigate the benefits of a state-of-the-art tool to help with the semantic annotation of a large set of biomedical queries. Seven annotators were recruited to annotate a set of 10,000 PubMed® queries with 16 biomedical and bibliographic categories. About half of the queries were annotated from scratch, while the other half were automatically pre-annotated and manually corrected. The impact of the automatic pre-annotations was assessed on several aspects of the task: time, number of actions, annotator satisfaction, inter-annotator agreement, quality and number of the resulting annotations. The analysis of annotation results showed that the number of required hand annotations is 28.9% less when using pre-annotated results from automatic tools. As a result, the overall annotation time was substantially lower when pre-annotations were used, while inter-annotator agreement was significantly higher. In addition, there was no statistically significant difference in the semantic distribution or number of annotations produced when pre-annotations were used. The annotated query corpus is freely available to the research community. This study shows that automatic pre-annotations are found helpful by most annotators. Our experience suggests using an automatic tool to assist large-scale manual annotation projects. This helps speed-up the annotation time and improve annotation consistency while maintaining high quality of the final annotations.
Published by Elsevier Inc.
Figures
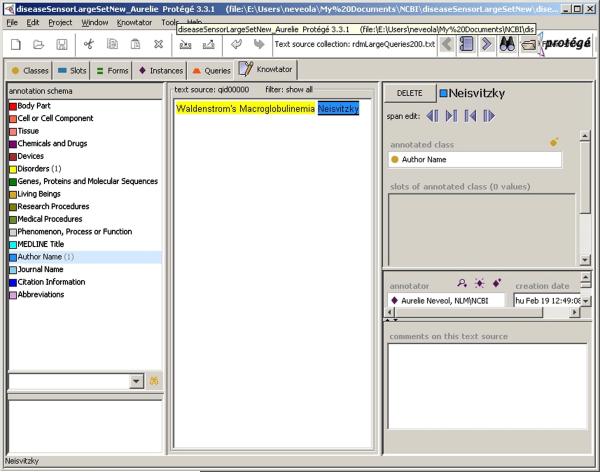
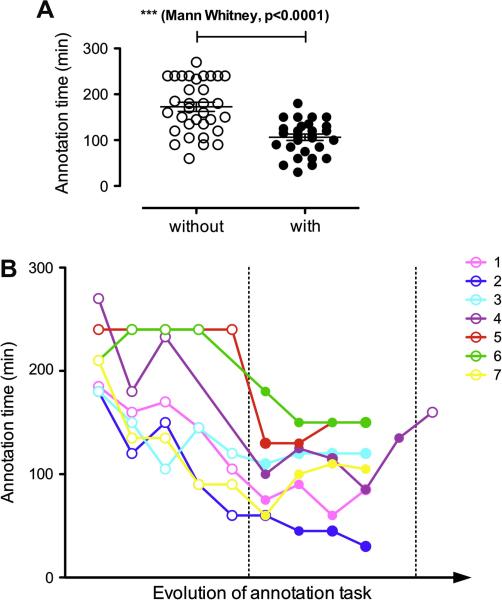
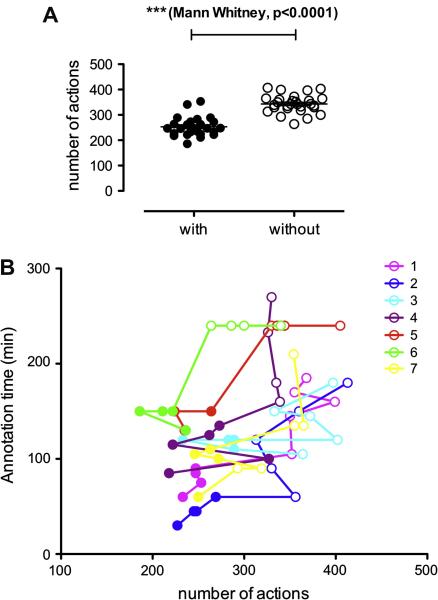
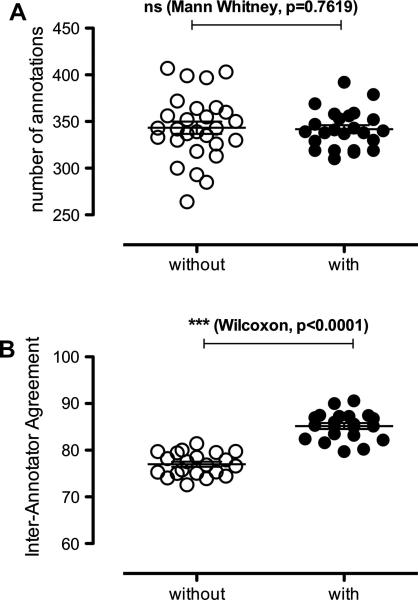
References
-
- Srinivasan P, Libbus B. Mining MEDLINE for implicit links between dietary substances and diseases. Bioinformatics. 2004 Aug 4;20(Suppl 1):i290–6. - PubMed
-
- Smith L, Tanabe LK, Ando RJ, Kuo CJ, Chung IF, Hsu CN, Lin YS, Klinger R, Friedrich CM, Ganchev K, Torii M, Liu H, Haddow B, Struble CA, Povinelli RJ, Vlachos A, Baumgartner WA, Jr, Hunter L, Carpenter B, Tsai RT, Dai HJ, Liu F, Chen Y, Sun C, Katrenko S, Adriaans P, Blaschke C, Torres R, Neves M, Nakov P, Divoli A, Maña-López M, Mata J, Wilbur WJ. Overview of BioCreative II gene mention recognition. Genome Biol. 2008;9(Suppl 2):S2. - PMC - PubMed
-
- Alex B, Grover C, Haddow B, Kabadjov M, Klein E, Matthews M, Roebuck S, Tobin R, Wang X. The ITI TXM Corpus: Tissue Expression and Protein-protein interactions. Proceedings of the LREC Workshop on Building and Evaluating Resources for Biomedical Text Mining; [Retrieved 08/18/09]. 2008b. from [ http://www.ltg.ed.ac.uk/np/publications/ltg/papers/Alex2008Corpora.pdf]
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
