

Structure learning in human sequential decision-making
- PMID: 21151963
- PMCID: PMC2996460
- DOI: 10.1371/journal.pcbi.1001003
Structure learning in human sequential decision-making
Abstract
Studies of sequential decision-making in humans frequently find suboptimal performance relative to an ideal actor that has perfect knowledge of the model of how rewards and events are generated in the environment. Rather than being suboptimal, we argue that the learning problem humans face is more complex, in that it also involves learning the structure of reward generation in the environment. We formulate the problem of structure learning in sequential decision tasks using Bayesian reinforcement learning, and show that learning the generative model for rewards qualitatively changes the behavior of an optimal learning agent. To test whether people exhibit structure learning, we performed experiments involving a mixture of one-armed and two-armed bandit reward models, where structure learning produces many of the qualitative behaviors deemed suboptimal in previous studies. Our results demonstrate humans can perform structure learning in a near-optimal manner.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
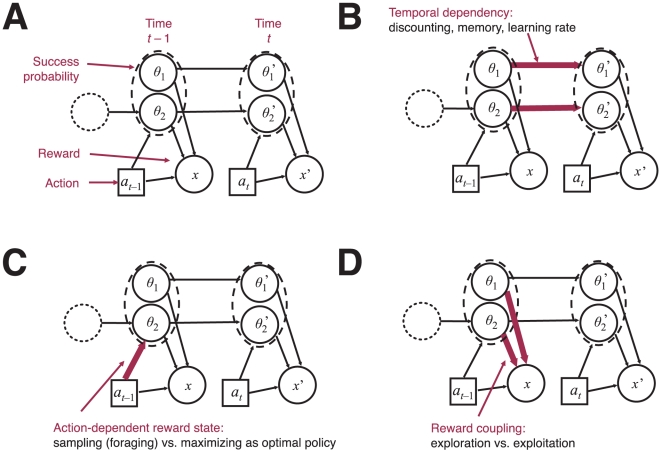
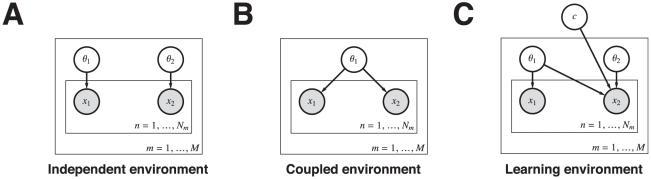
 tasks, each comprising a random number
tasks, each comprising a random number  of choices. A) Rewarding options are independent. B) Rewarding options are coupled within a task. C) Mixture of tasks. Rewarding options may be independent or coupled. The node
of choices. A) Rewarding options are independent. B) Rewarding options are coupled within a task. C) Mixture of tasks. Rewarding options may be independent or coupled. The node  acts as a “XOR” switch between coupled and independent structure.
acts as a “XOR” switch between coupled and independent structure.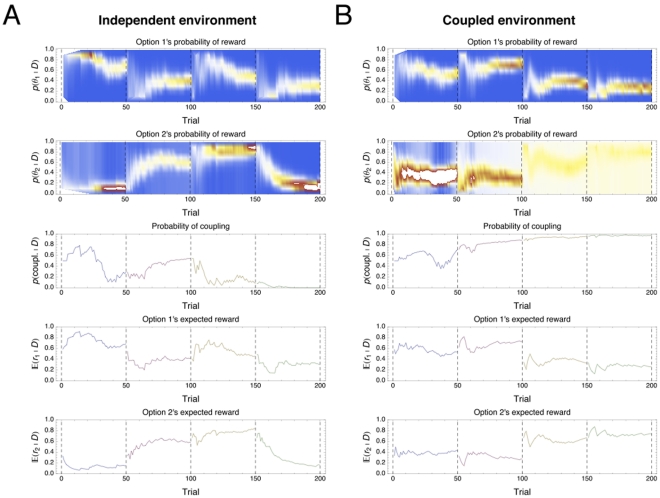
 and
and  . Marginal beliefs on reward probabilities (brightness indicates relative probability mass), probability of coupling and expected reward are shown as functions of time. A) Simulation on Independent Environment B) Simulation on Coupled Environment.
. Marginal beliefs on reward probabilities (brightness indicates relative probability mass), probability of coupling and expected reward are shown as functions of time. A) Simulation on Independent Environment B) Simulation on Coupled Environment.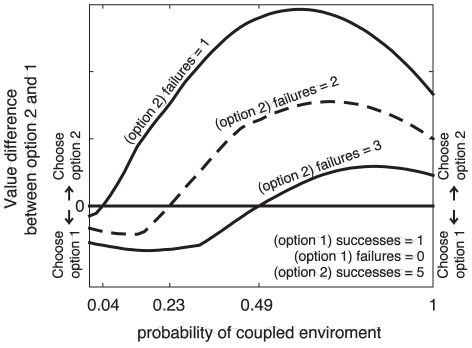
 ,
,  , and
, and  and discount factor
and discount factor  is 0.98, all values fixed for the simulation. The number of failures for option two (
is 0.98, all values fixed for the simulation. The number of failures for option two ( ) is varied from 1 through 3. Under these conditions, the independent would always choose option 1 whereas the coupled model would always choose option 2. However, the structure learning model switches between these two The graph shows the difference in values between the option 2 and 1 as a function of the task uncertainty.
) is varied from 1 through 3. Under these conditions, the independent would always choose option 1 whereas the coupled model would always choose option 2. However, the structure learning model switches between these two The graph shows the difference in values between the option 2 and 1 as a function of the task uncertainty.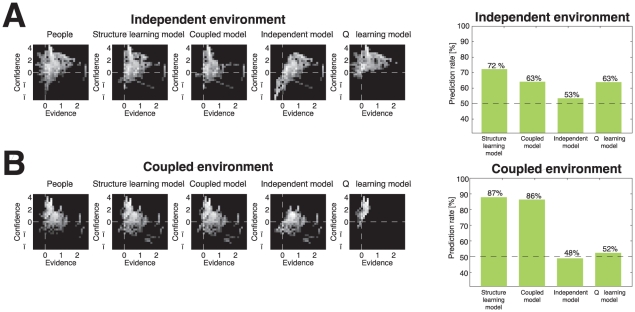
 ) A) Trials in Independent Environment B) Trials in Coupled Environment.
) A) Trials in Independent Environment B) Trials in Coupled Environment.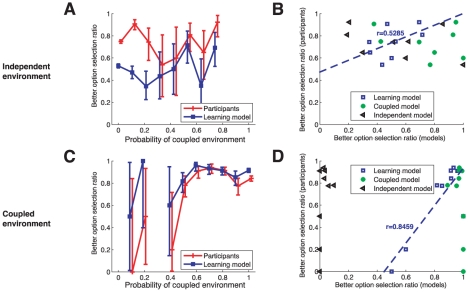
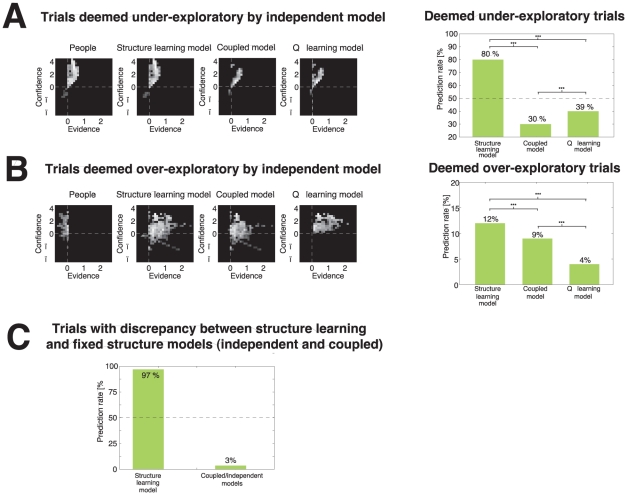
References
-
- Bellman RE. A problem in the sequential design of experiments. Sankhyā. 1956;16:221–229.
-
- Gittins JC. Multi-armed bandit allocation indices. Chichester [West Sussex]; New York: Wiley; 1989.
-
- Whittle P. Restless bandits: activity allocation in a changing world. J Appl Probab. 1988;25:287–298.
-
- Yi MS, Steyvers M, Lee M. Modeling human performance in restless bandits with particle filters. The Journal of Problem Solving. 2009;2 Available: http://docs.lib.purdue.edu/jps/vol2/iss2/5/
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
