

Smed454 dataset: unravelling the transcriptome of Schmidtea mediterranea
- PMID: 21194483
- PMCID: PMC3022928
- DOI: 10.1186/1471-2164-11-731
Smed454 dataset: unravelling the transcriptome of Schmidtea mediterranea
Abstract
Background: Freshwater planarians are an attractive model for regeneration and stem cell research and have become a promising tool in the field of regenerative medicine. With the availability of a sequenced planarian genome, the recent application of modern genetic and high-throughput tools has resulted in revitalized interest in these animals, long known for their amazing regenerative capabilities, which enable them to regrow even a new head after decapitation. However, a detailed description of the planarian transcriptome is essential for future investigation into regenerative processes using planarians as a model system.
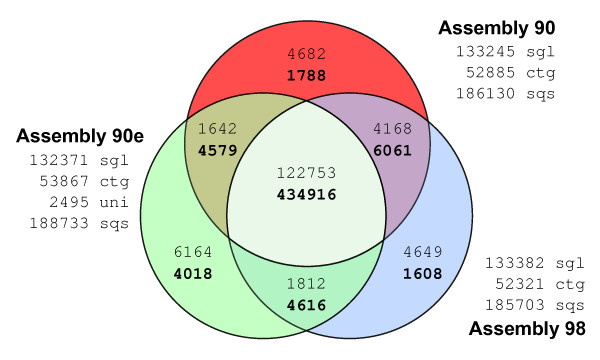
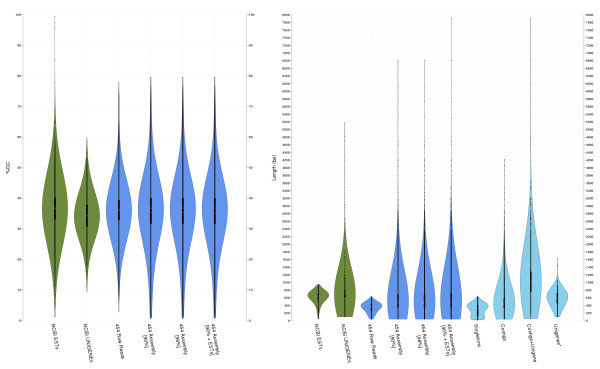
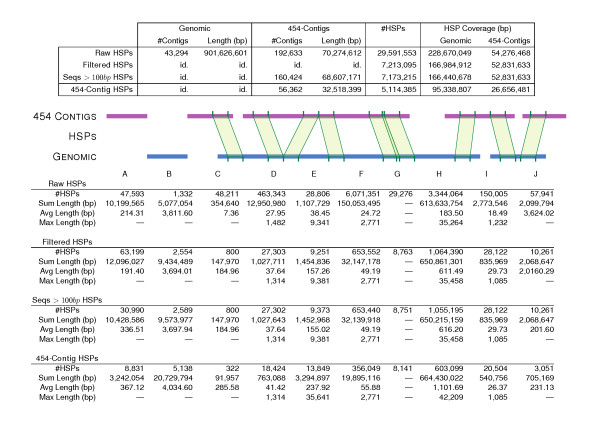
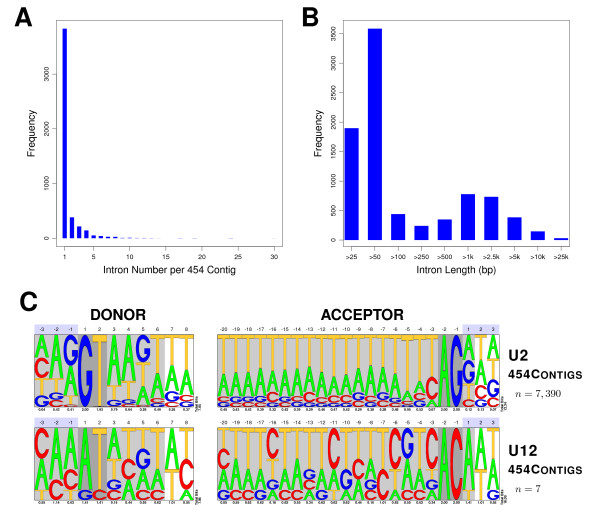
Results: In order to complement and improve existing gene annotations, we used a 454 pyrosequencing approach to analyze the transcriptome of the planarian species Schmidtea mediterranea Altogether, 598,435 454-sequencing reads, with an average length of 327 bp, were assembled together with the ~10,000 sequences of the S. mediterranea UniGene set using different similarity cutoffs. The assembly was then mapped onto the current genome data. Remarkably, our Smed454 dataset contains more than 3 million novel transcribed nucleotides sequenced for the first time. A descriptive analysis of planarian splice sites was conducted on those Smed454 contigs that mapped univocally to the current genome assembly. Sequence analysis allowed us to identify genes encoding putative proteins with defined structural properties, such as transmembrane domains. Moreover, we annotated the Smed454 dataset using Gene Ontology, and identified putative homologues of several gene families that may play a key role during regeneration, such as neurotransmitter and hormone receptors, homeobox-containing genes, and genes related to eye function.
Conclusions: We report the first planarian transcript dataset, Smed454, as an open resource tool that can be accessed via a web interface. Smed454 contains significant novel sequence information about most expressed genes of S. mediterranea. Analysis of the annotated data promises to contribute to identification of gene families poorly characterized at a functional level. The Smed454 transcriptome data will assist in the molecular characterization of S. mediterranea as a model organism, which will be useful to a broad scientific community.
Figures
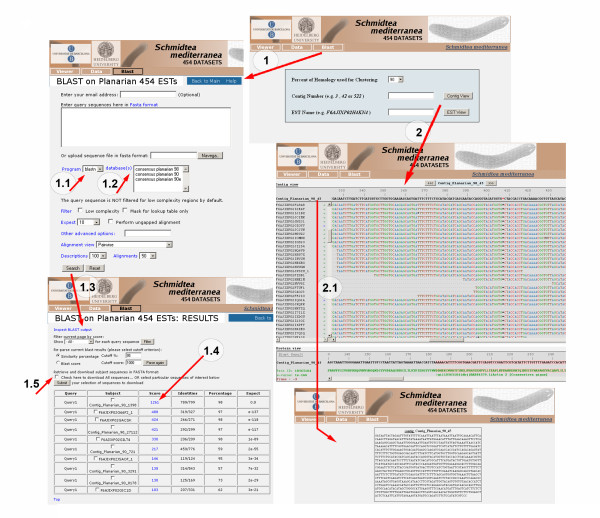
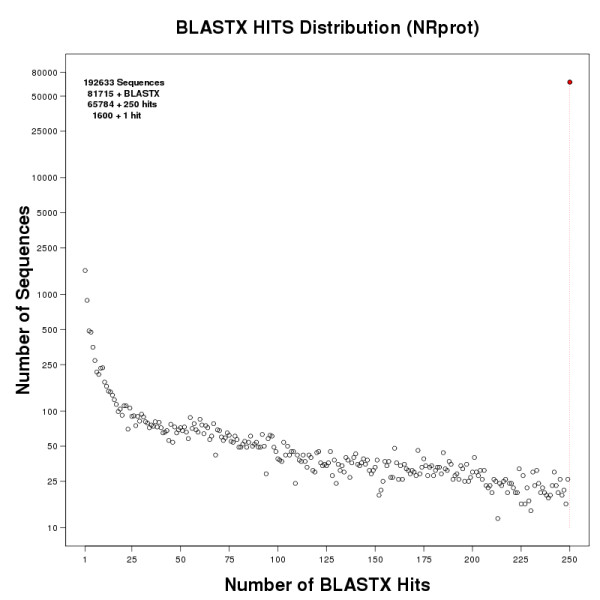
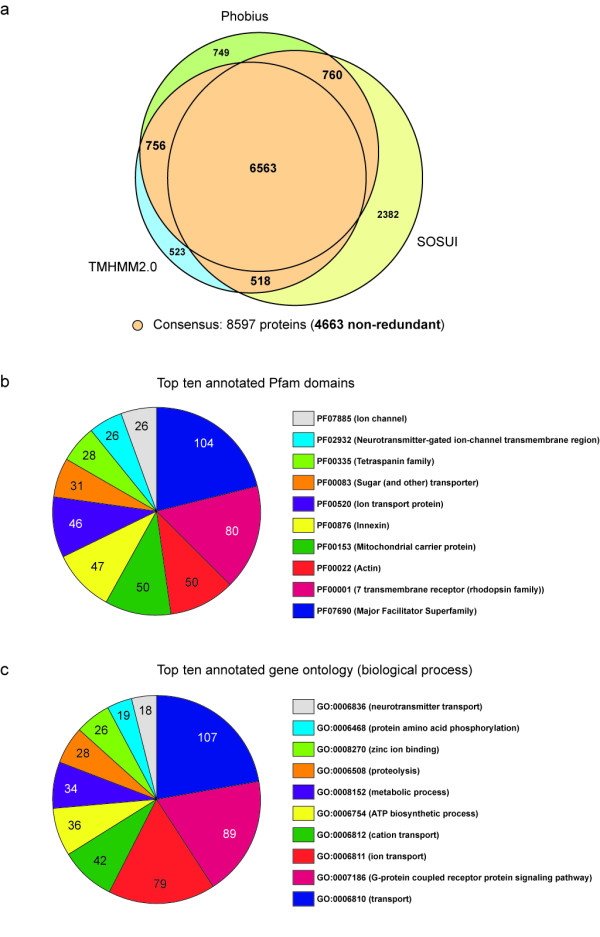
References
-
- Saló E. The power of regeneration and the stem-cell kingdom: freshwater planarians (Platyhelminthes) Bioessays. 2006;28(5):546–559. - PubMed
-
- Baguñà J, Saló E, Auladell C. Regeneration and pattern formation in planarians. III. Evidence that neoblasts are totipotent stem cells and the source of blastema cells. Development. 1989;107:77–86.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
