

Recovering sound sources from embedded repetition
- PMID: 21199948
- PMCID: PMC3024660
- DOI: 10.1073/pnas.1004765108
Recovering sound sources from embedded repetition
Abstract
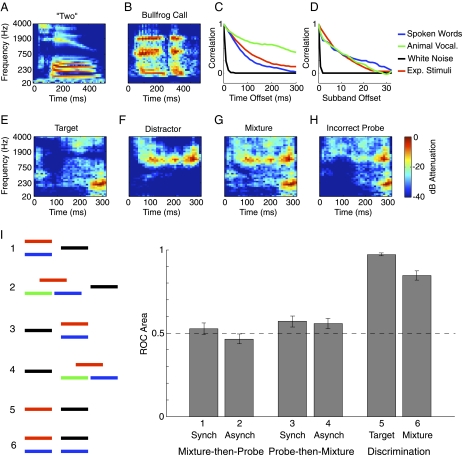
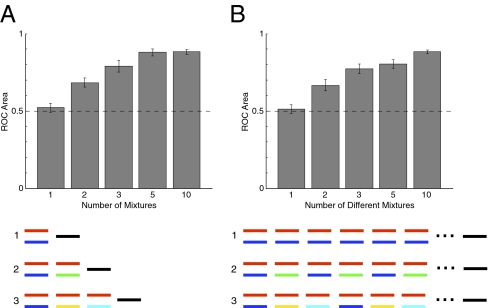
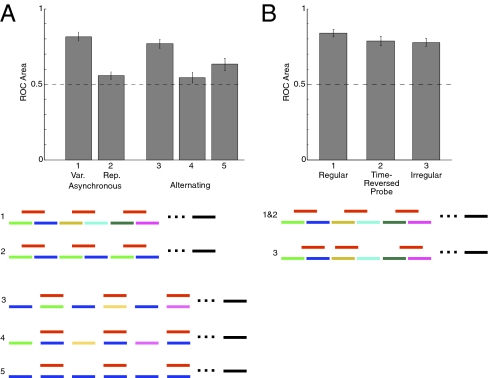
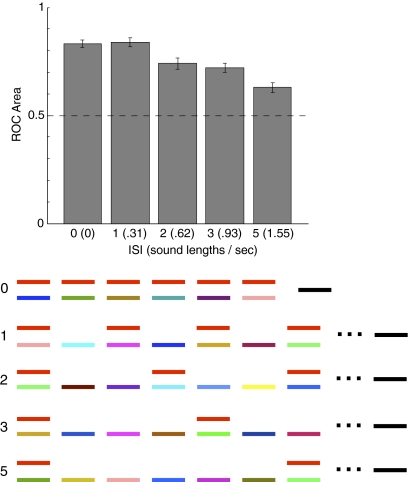
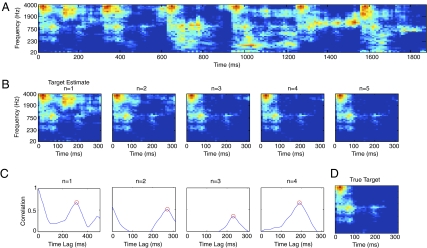
Cocktail parties and other natural auditory environments present organisms with mixtures of sounds. Segregating individual sound sources is thought to require prior knowledge of source properties, yet these presumably cannot be learned unless the sources are segregated first. Here we show that the auditory system can bootstrap its way around this problem by identifying sound sources as repeating patterns embedded in the acoustic input. Due to the presence of competing sounds, source repetition is not explicit in the input to the ear, but it produces temporal regularities that listeners detect and use for segregation. We used a simple generative model to synthesize novel sounds with naturalistic properties. We found that such sounds could be segregated and identified if they occurred more than once across different mixtures, even when the same sounds were impossible to segregate in single mixtures. Sensitivity to the repetition of sound sources can permit their recovery in the absence of other segregation cues or prior knowledge of sounds, and could help solve the cocktail party problem.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Bregman AS. Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: MIT Press; 1990.
-
- Darwin CJ, Carlyon RP. Auditory grouping. In: Moore BCJ, editor. The Handbook of Perception and Cognition. Vol. 6. New York: Academic; 1995.
-
- Bronkhorst AW. The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions. Acustica. 2000;86:117–128.
-
- Narayan R, et al. Cortical interference effects in the cocktail party problem. Nat Neurosci. 2007;10:1601–1607. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
