

High-Dimensional Sparse Factor Modeling: Applications in Gene Expression Genomics
- PMID: 21218139
- PMCID: PMC3017385
- DOI: 10.1198/016214508000000869
High-Dimensional Sparse Factor Modeling: Applications in Gene Expression Genomics
Abstract
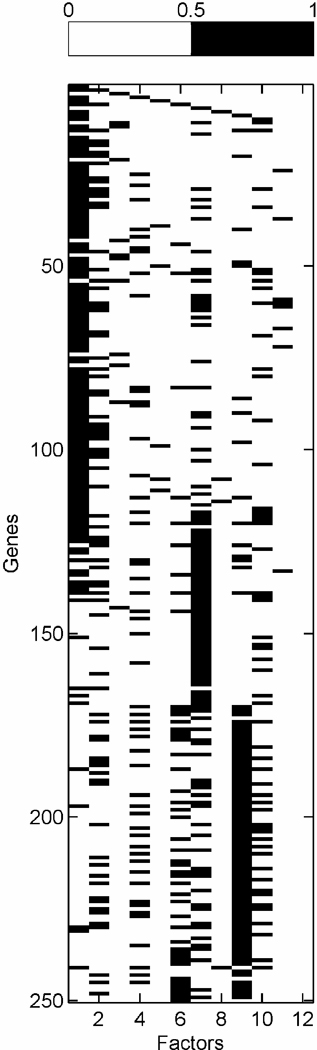
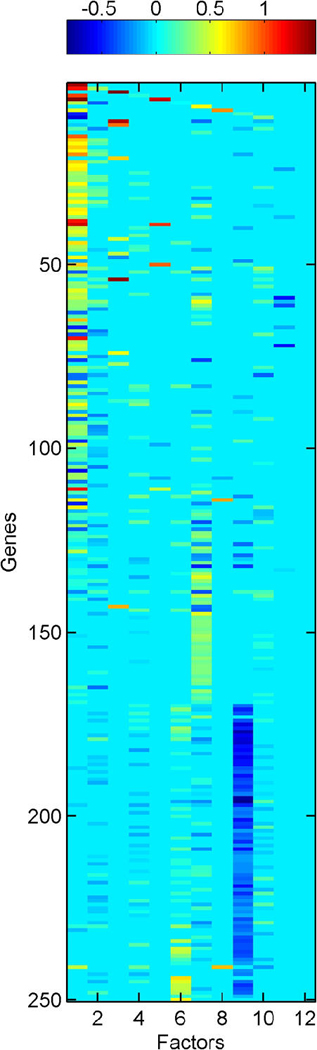
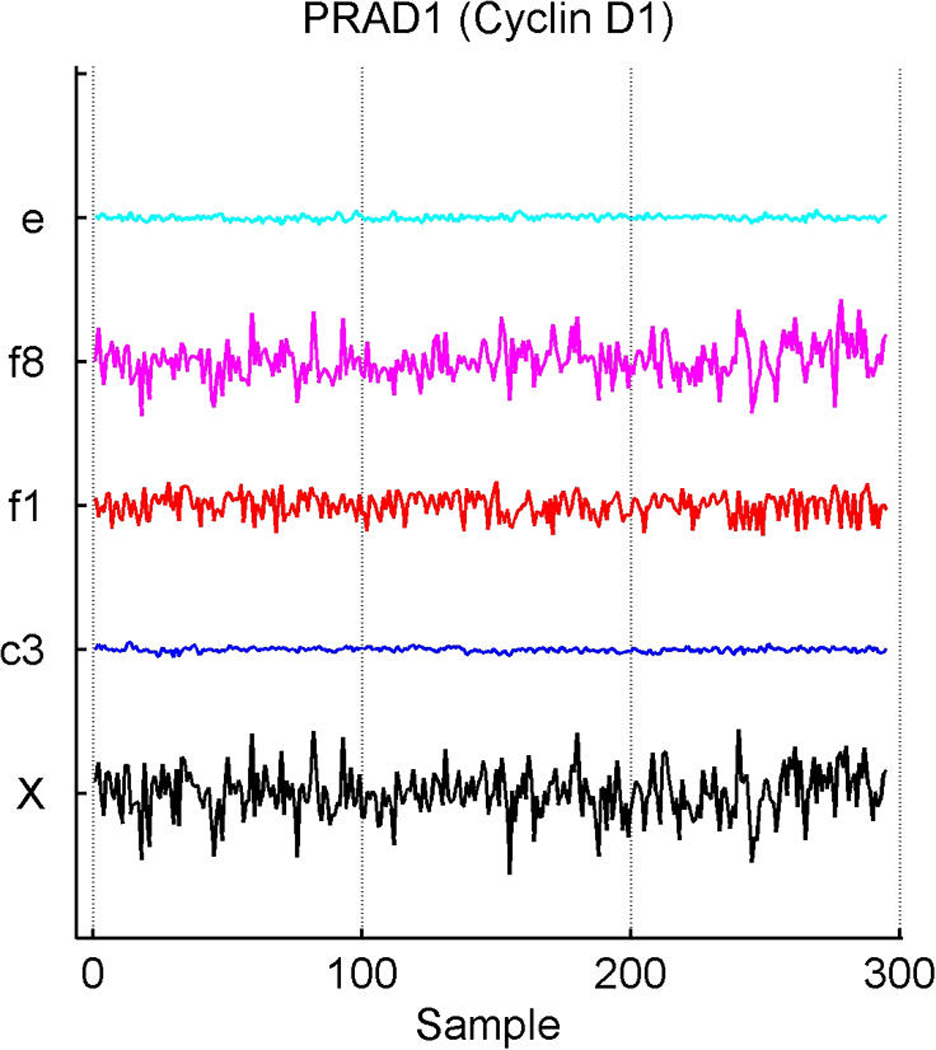
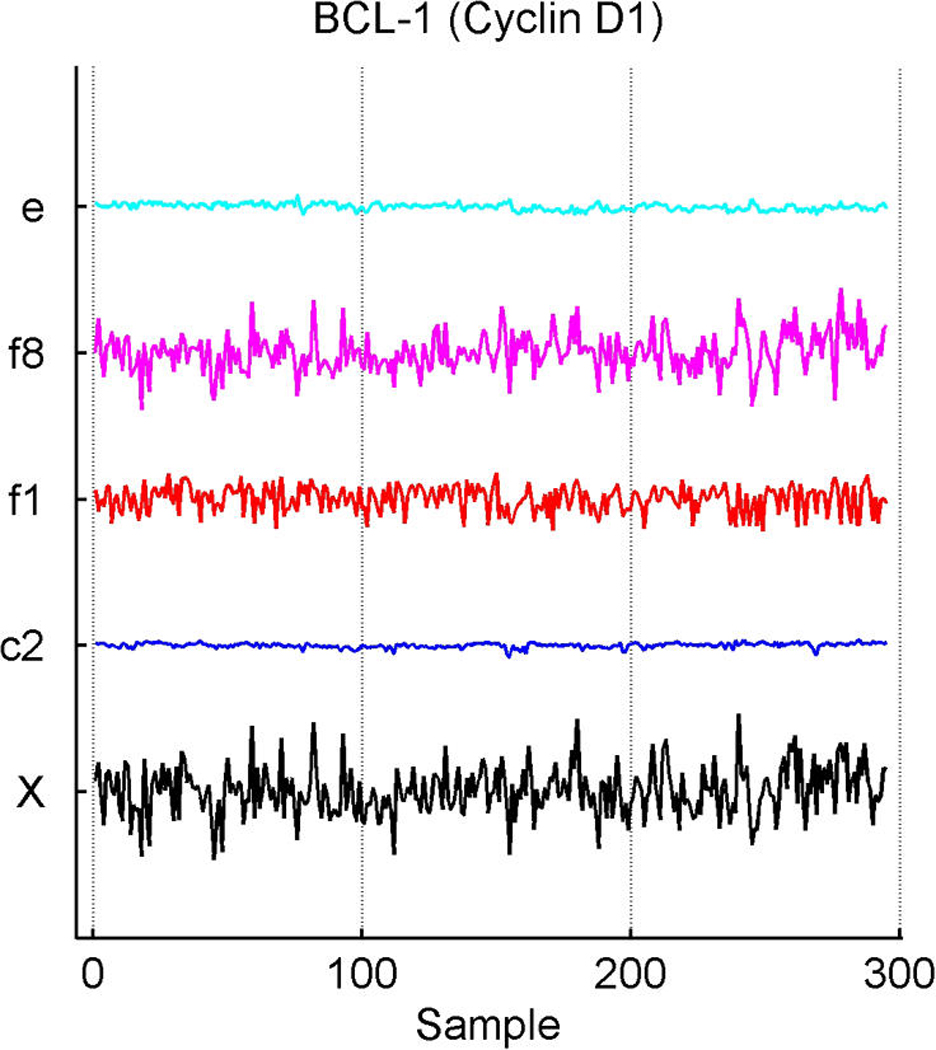
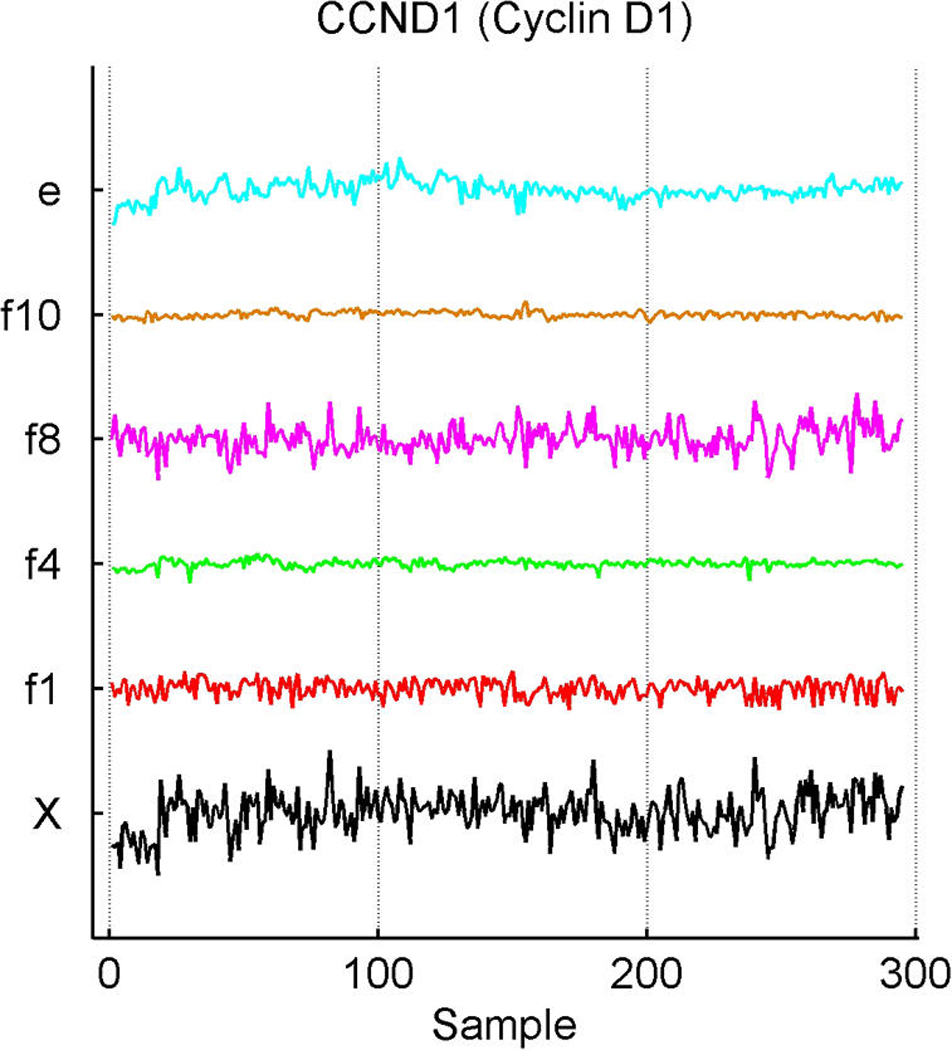
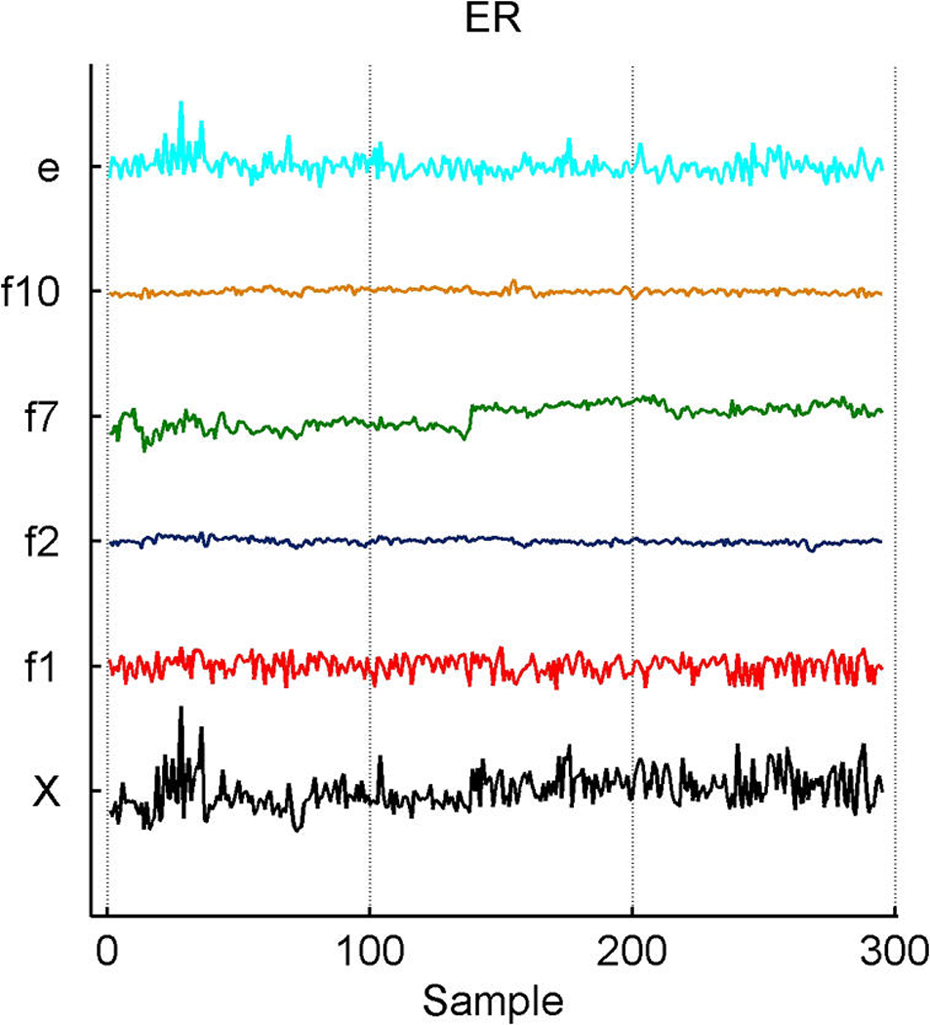
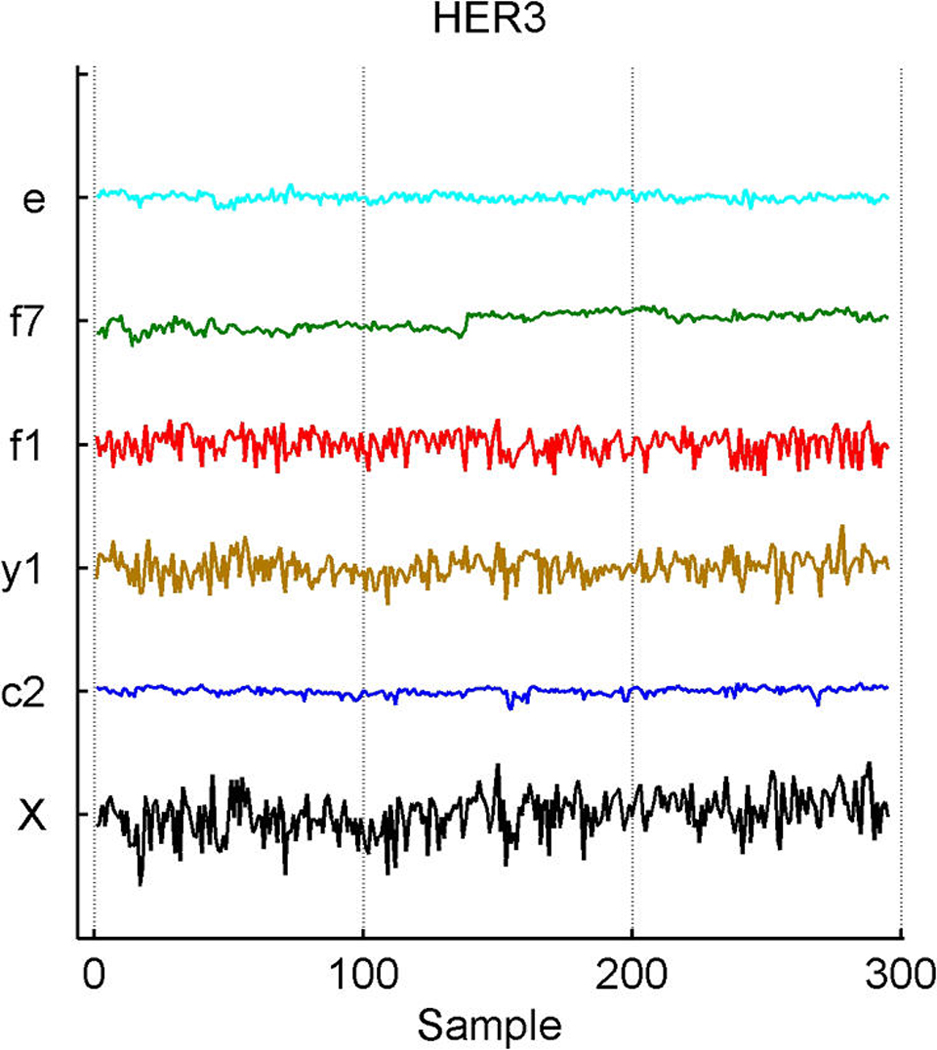
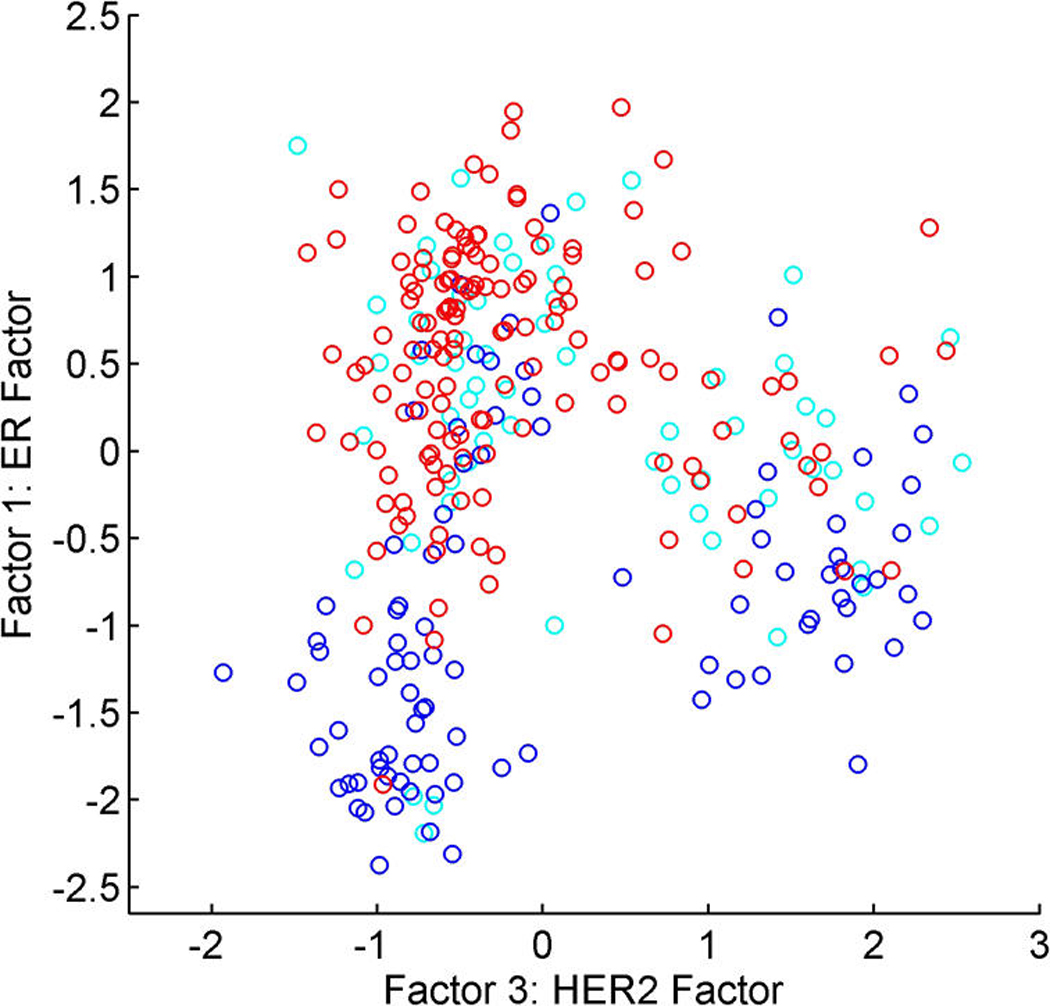
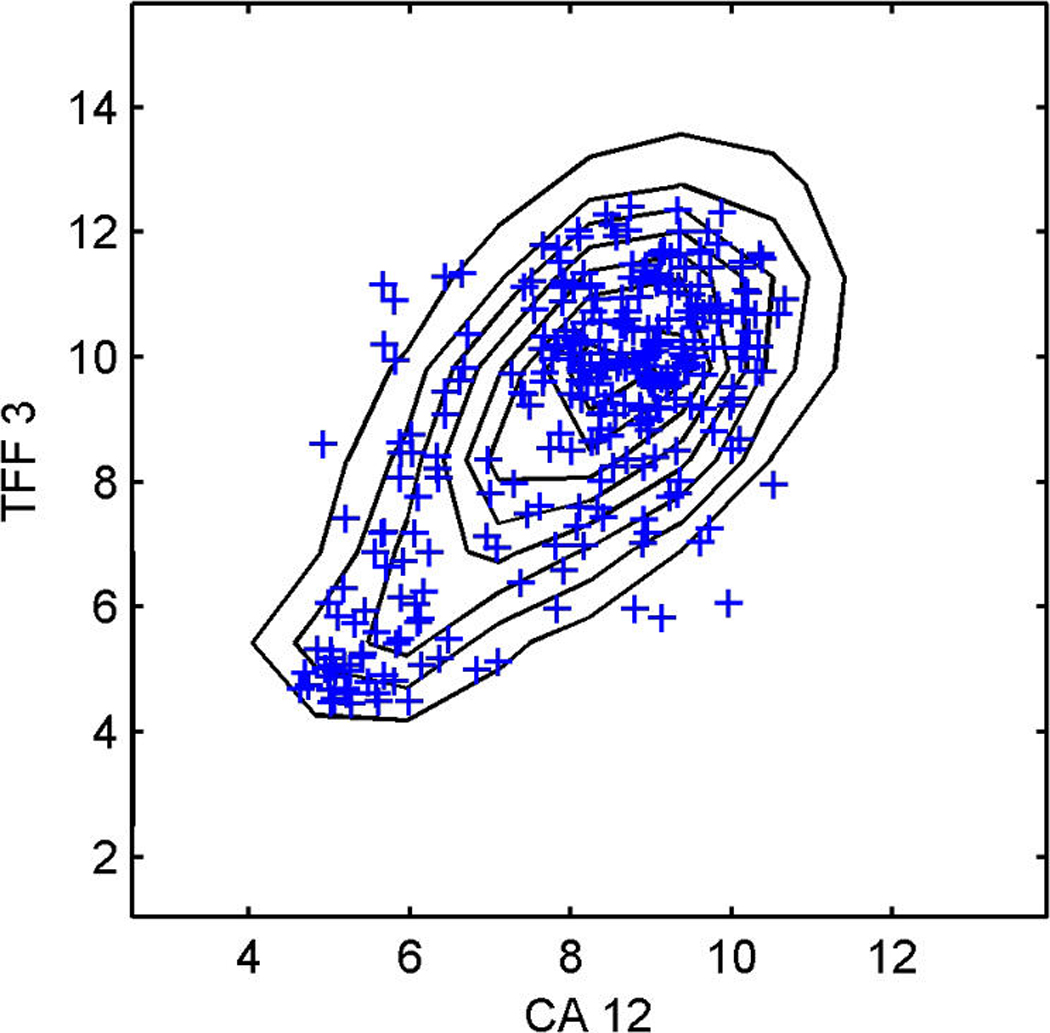
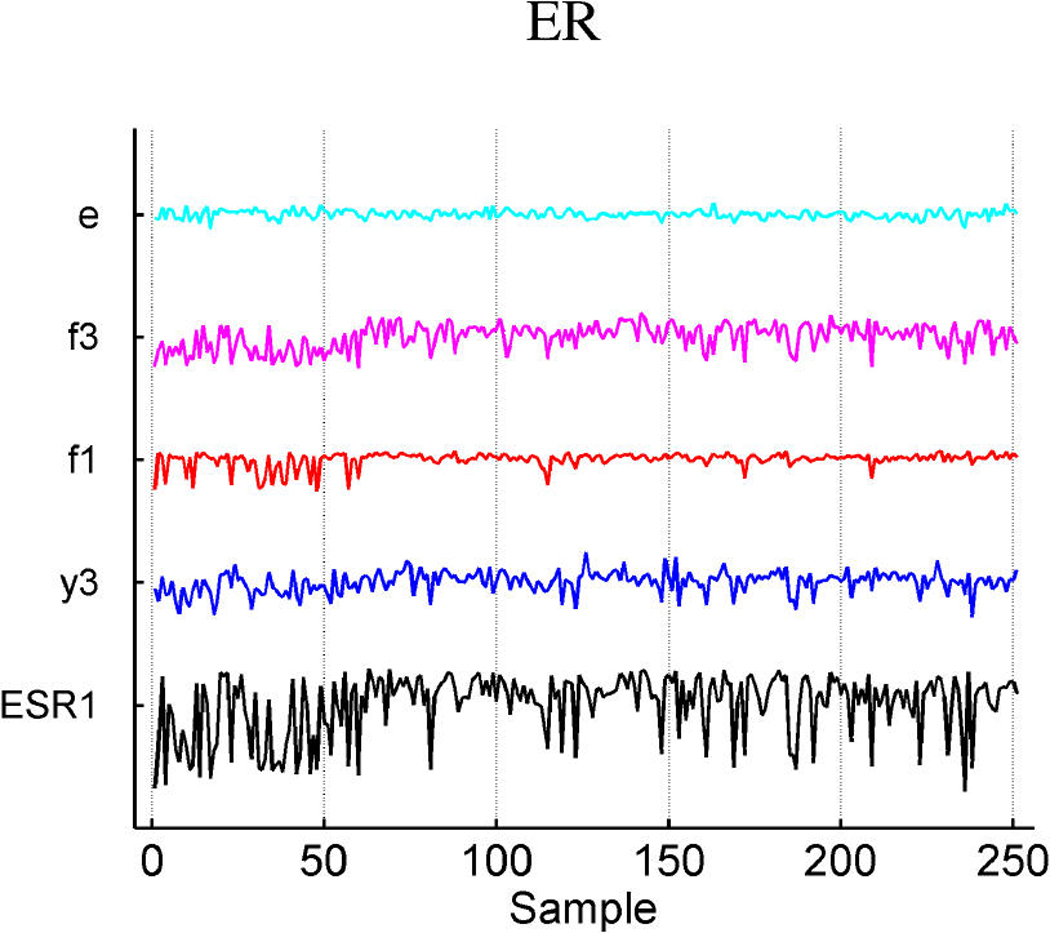
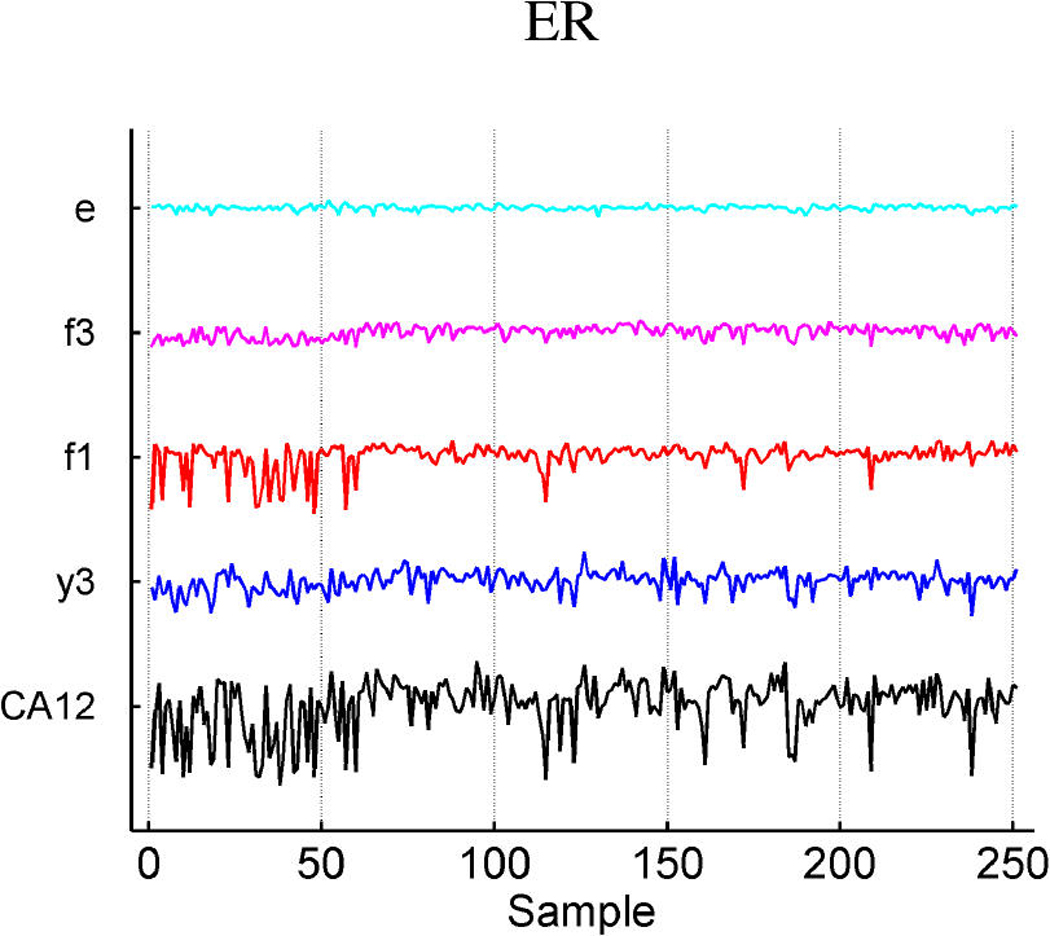
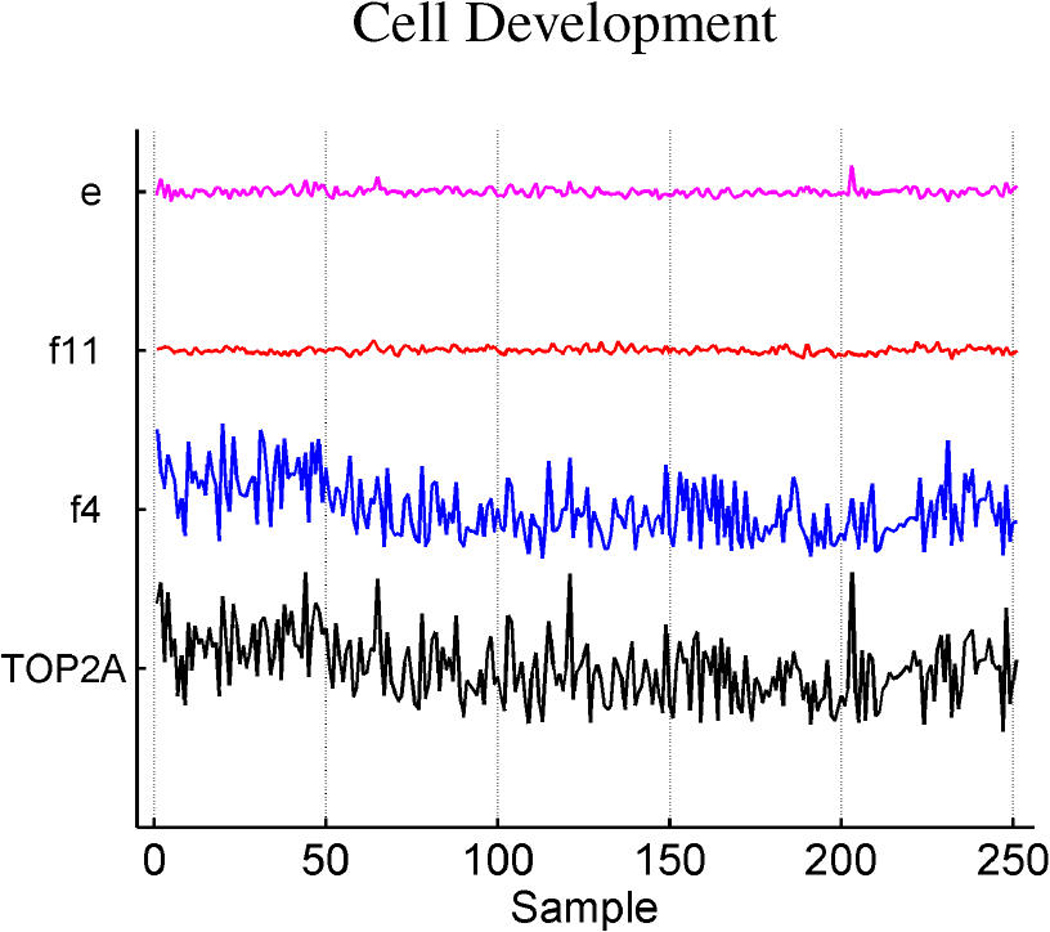
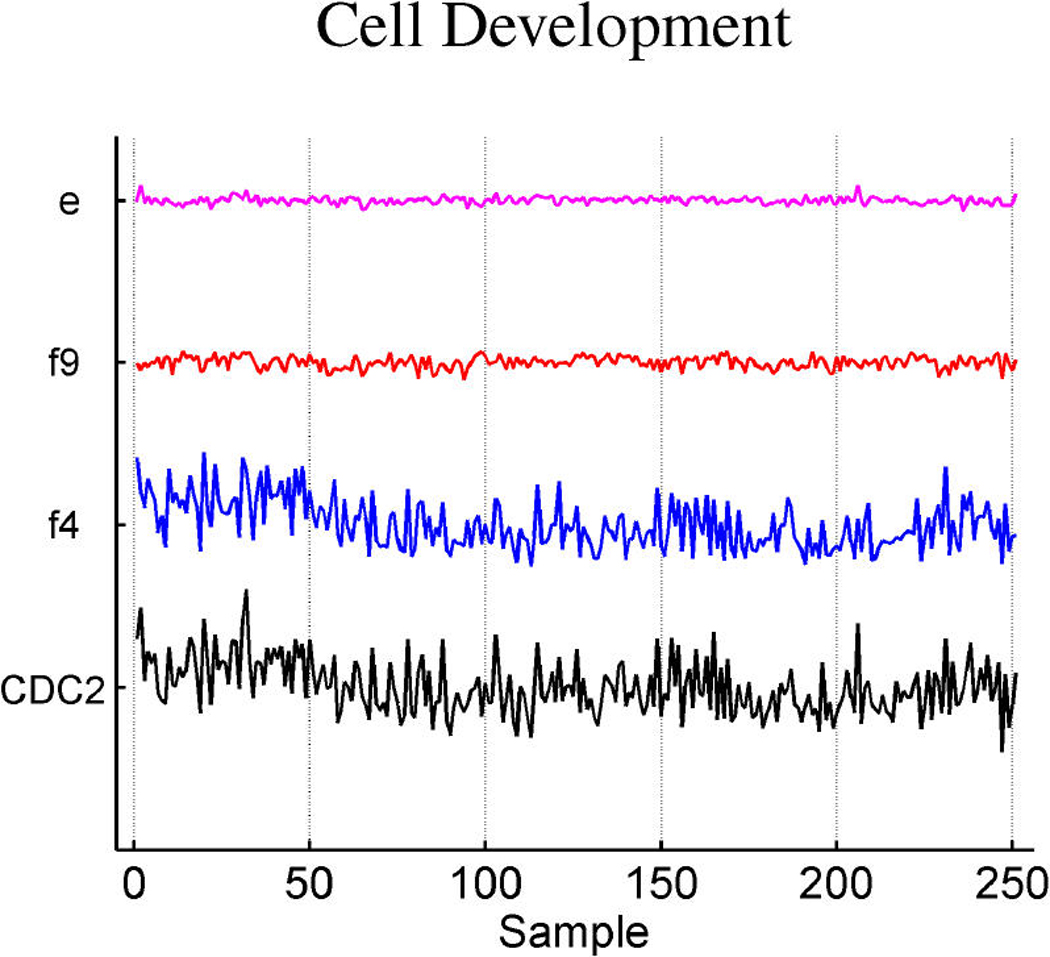
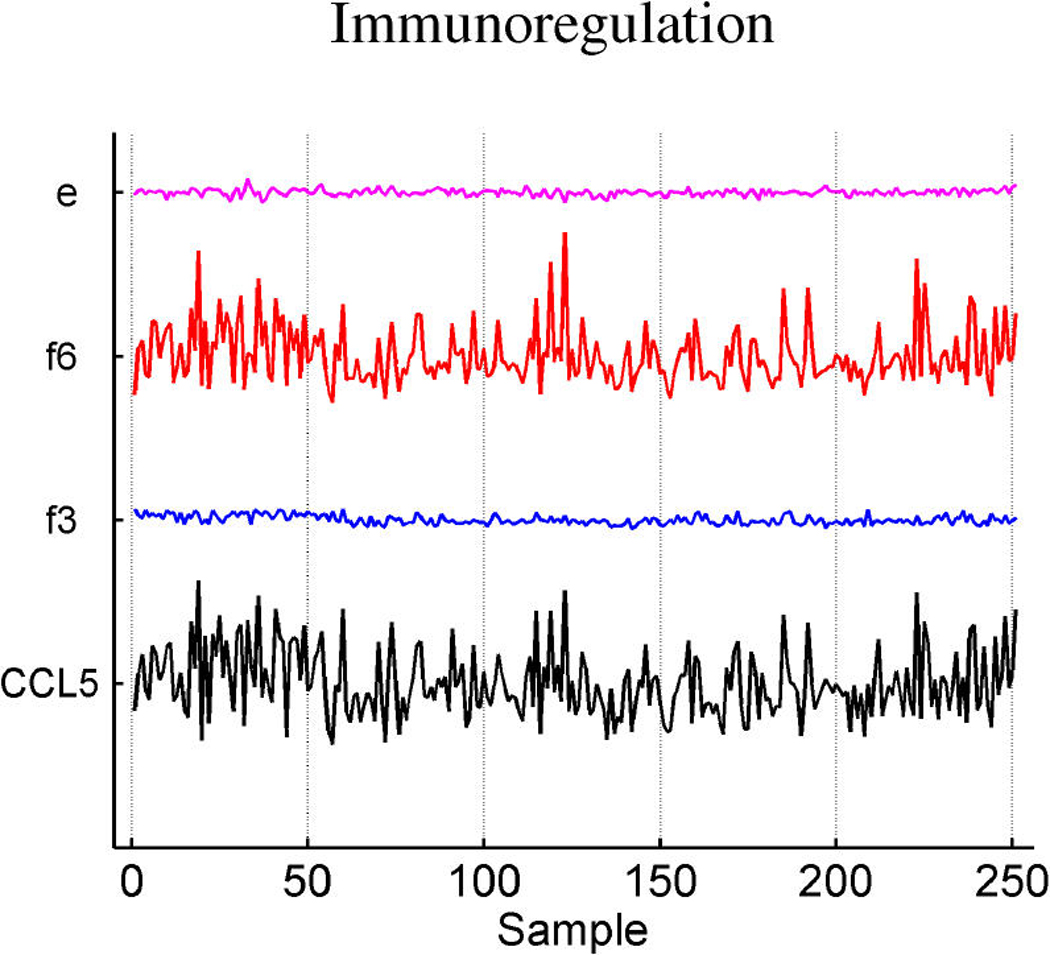
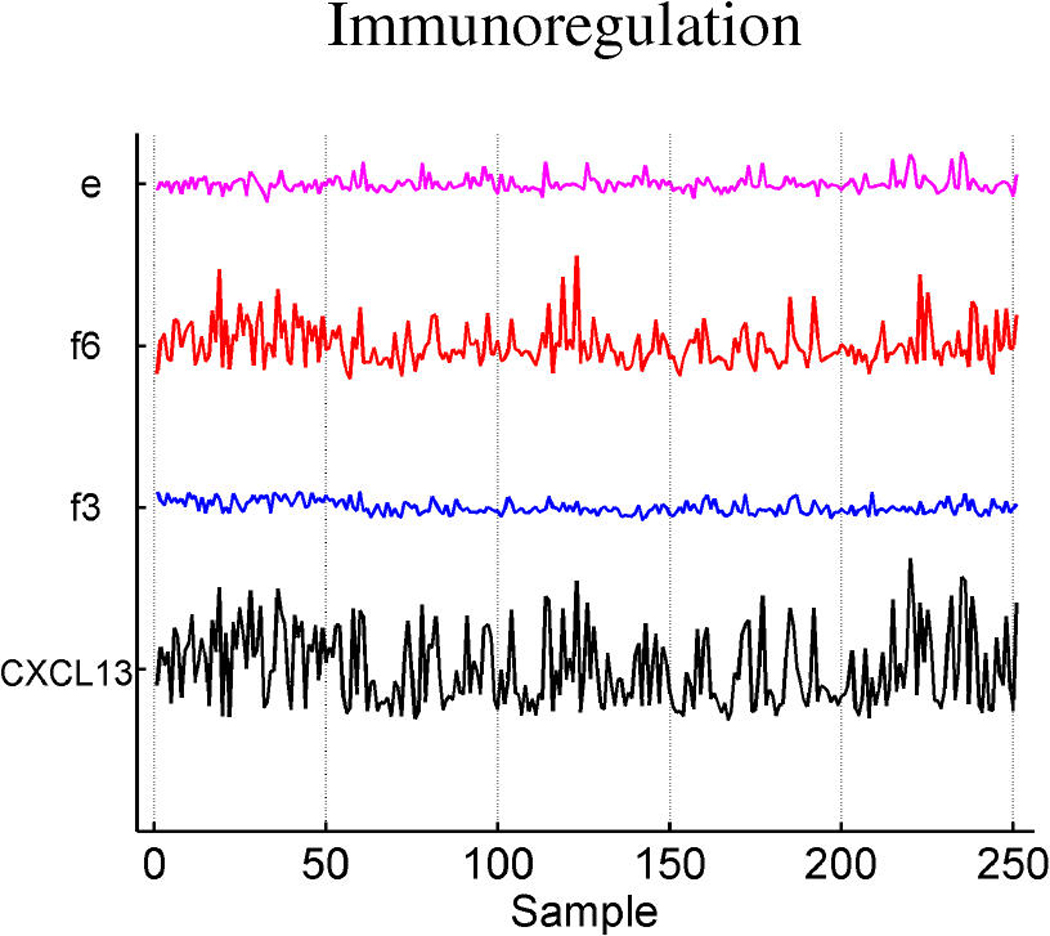
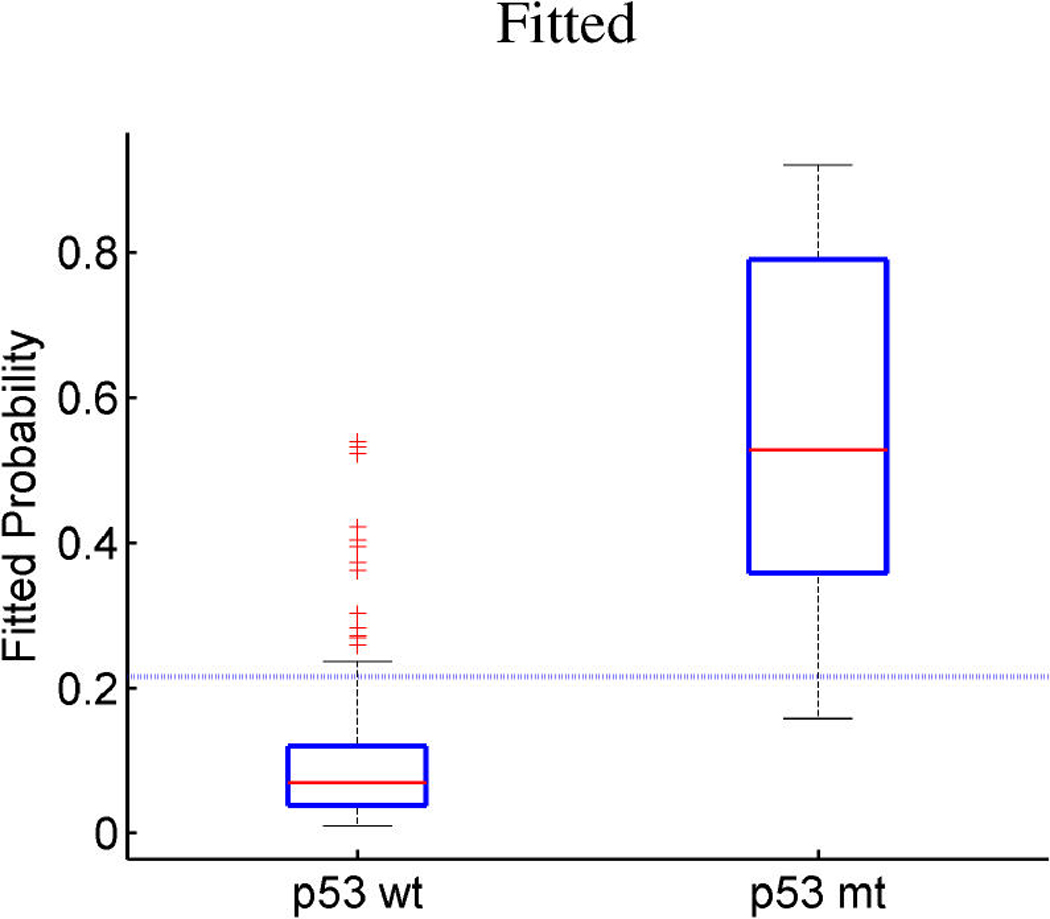
We describe studies in molecular profiling and biological pathway analysis that use sparse latent factor and regression models for microarray gene expression data. We discuss breast cancer applications and key aspects of the modeling and computational methodology. Our case studies aim to investigate and characterize heterogeneity of structure related to specific oncogenic pathways, as well as links between aggregate patterns in gene expression profiles and clinical biomarkers. Based on the metaphor of statistically derived "factors" as representing biological "subpathway" structure, we explore the decomposition of fitted sparse factor models into pathway subcomponents and investigate how these components overlay multiple aspects of known biological activity. Our methodology is based on sparsity modeling of multivariate regression, ANOVA, and latent factor models, as well as a class of models that combines all components. Hierarchical sparsity priors address questions of dimension reduction and multiple comparisons, as well as scalability of the methodology. The models include practically relevant non-Gaussian/nonparametric components for latent structure, underlying often quite complex non-Gaussianity in multivariate expression patterns. Model search and fitting are addressed through stochastic simulation and evolutionary stochastic search methods that are exemplified in the oncogenic pathway studies. Supplementary supporting material provides more details of the applications, as well as examples of the use of freely available software tools for implementing the methodology.
Figures
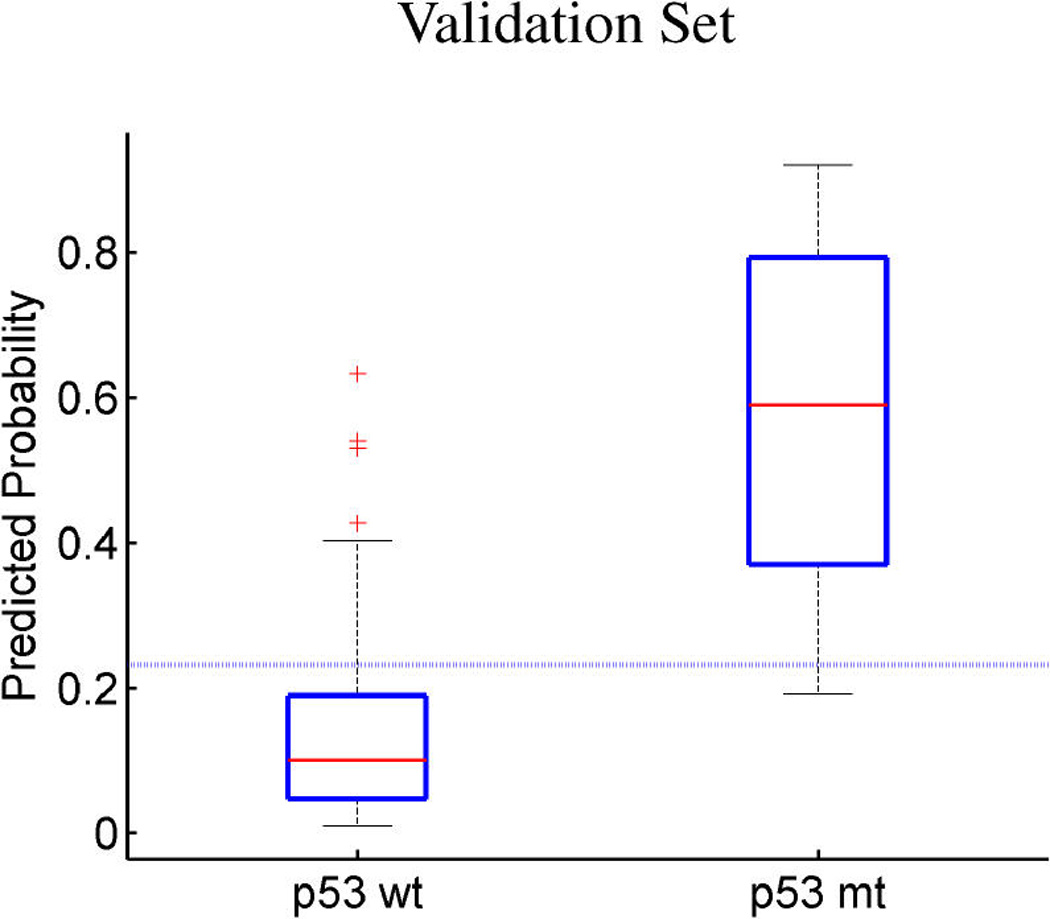
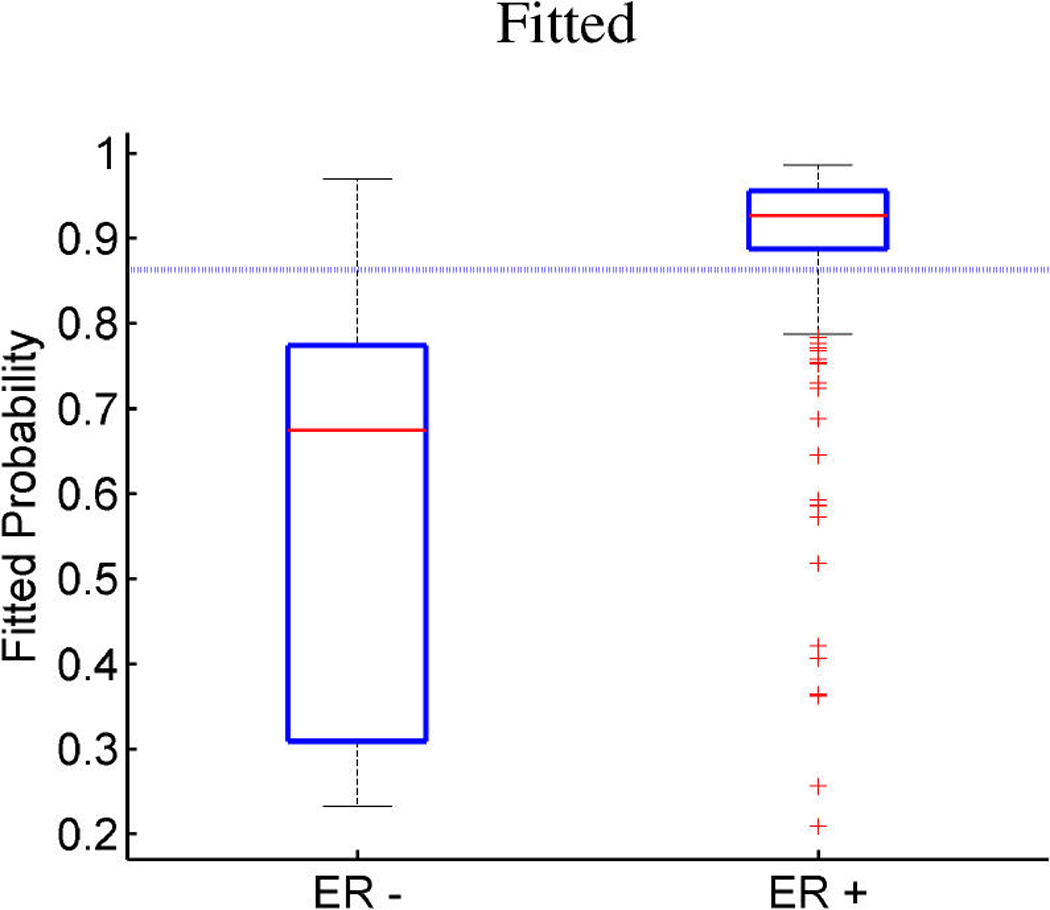
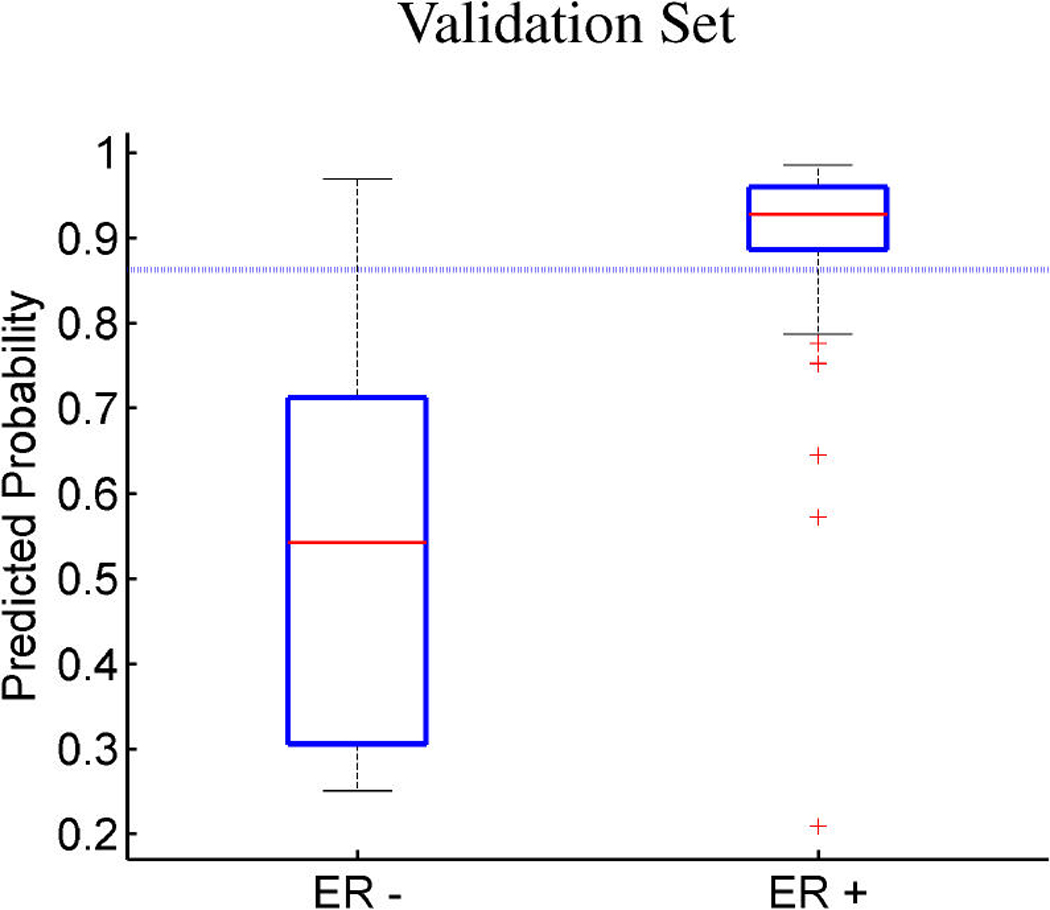
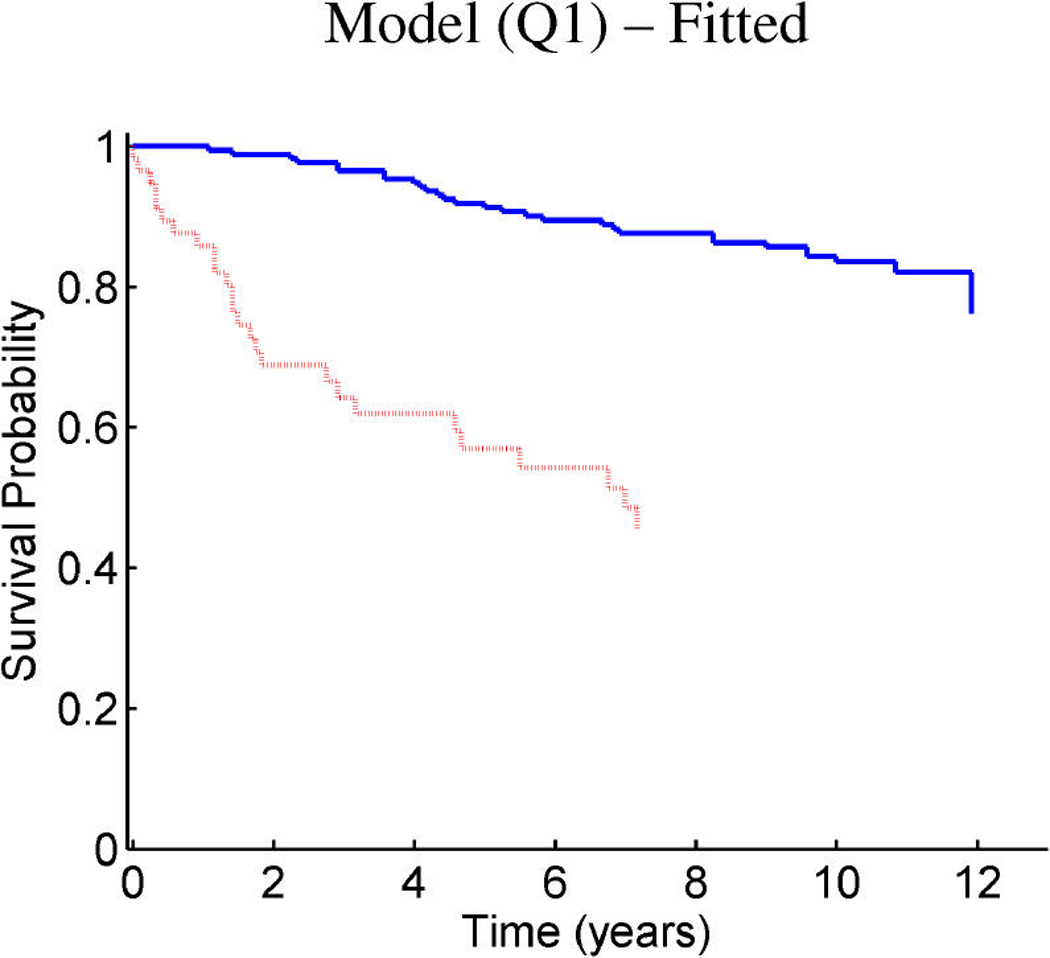
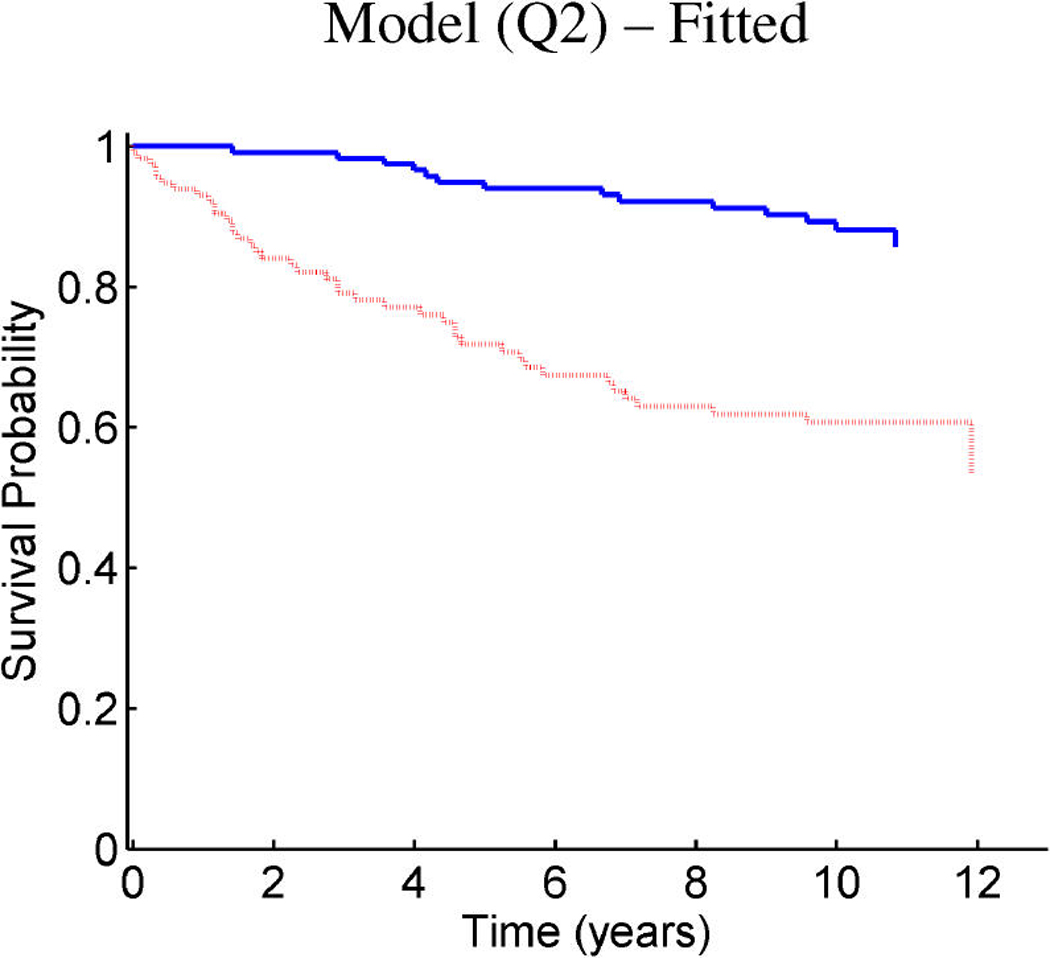
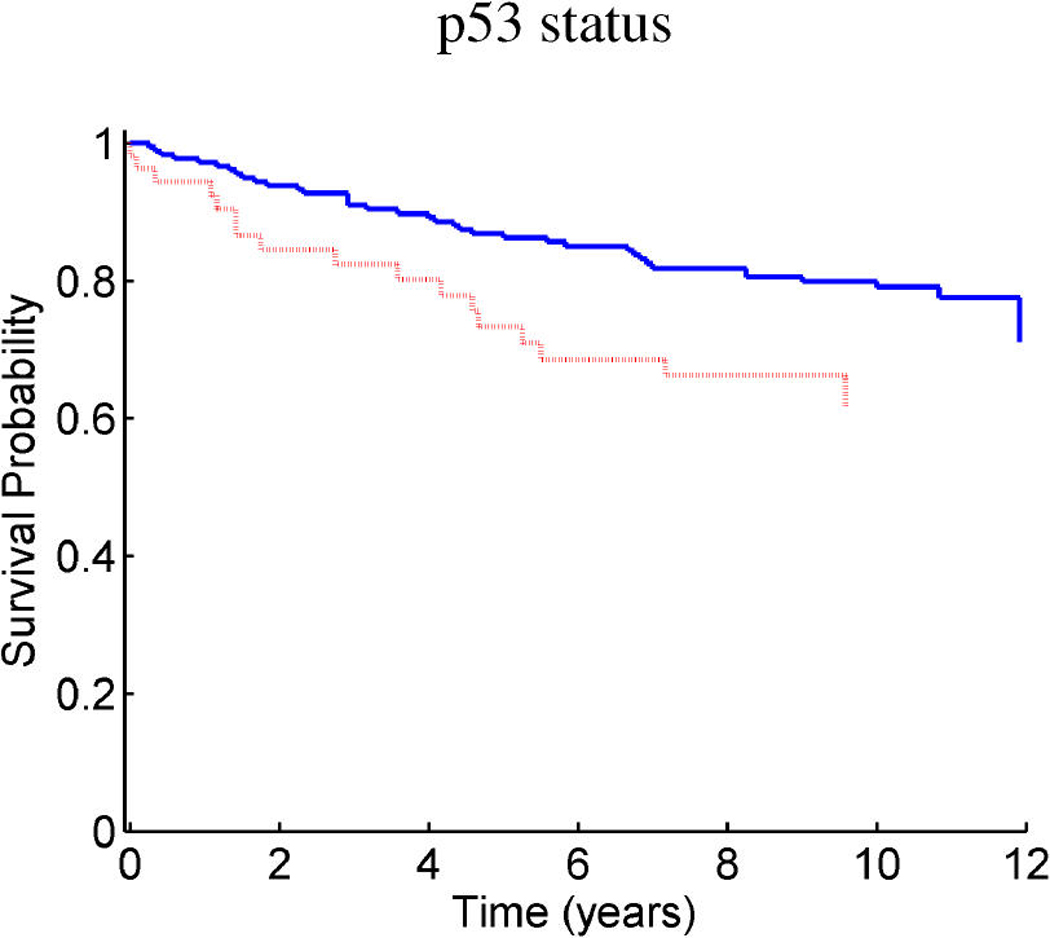
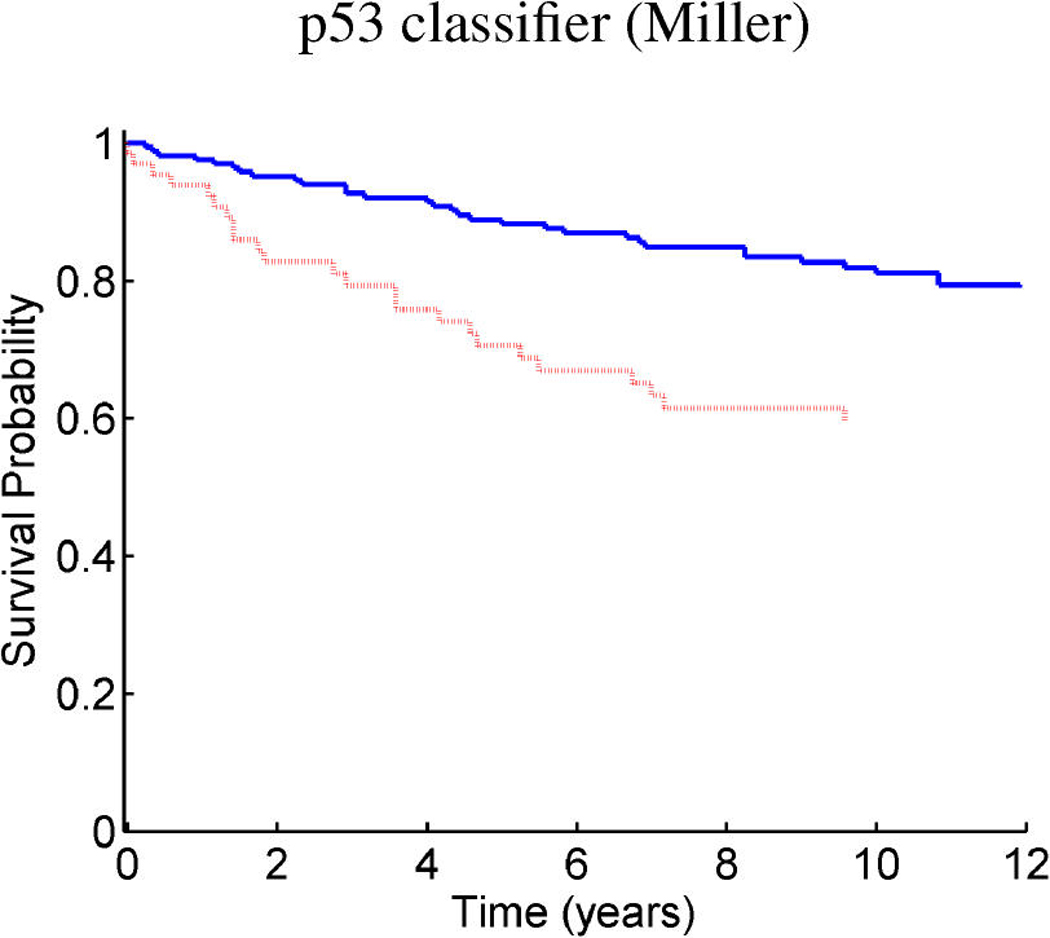
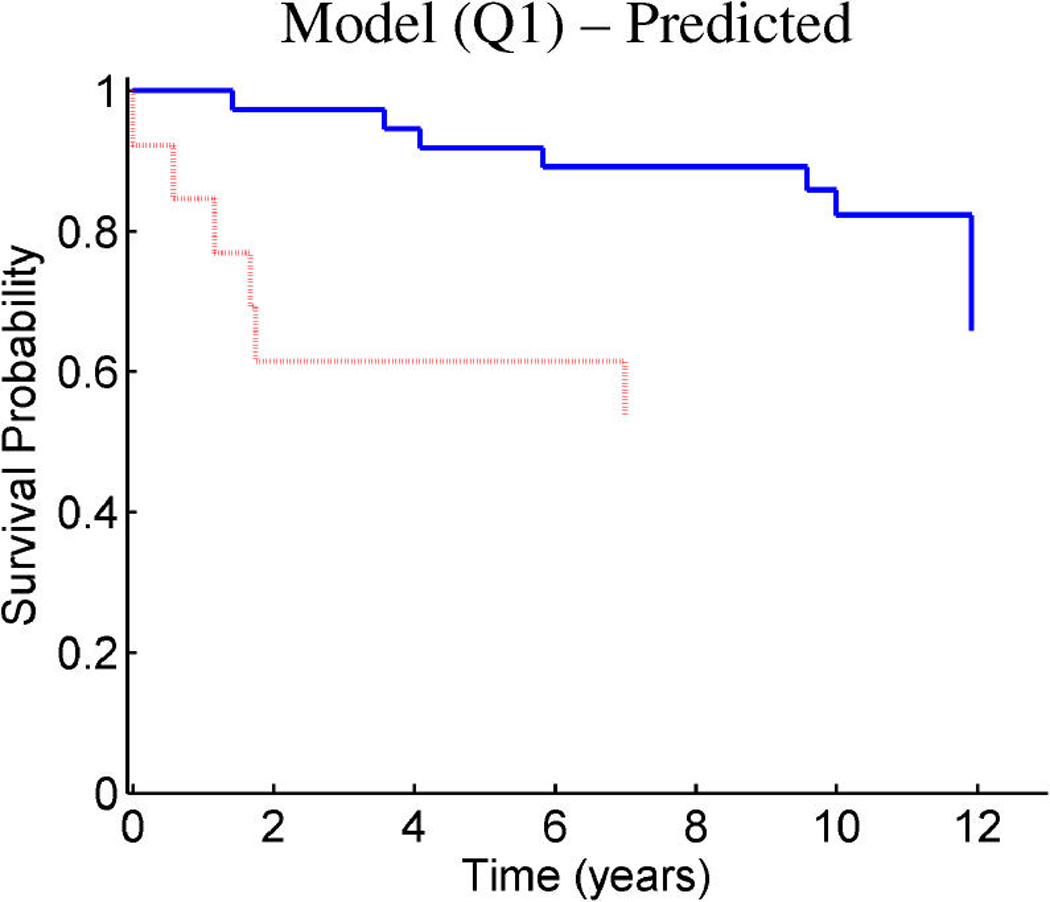
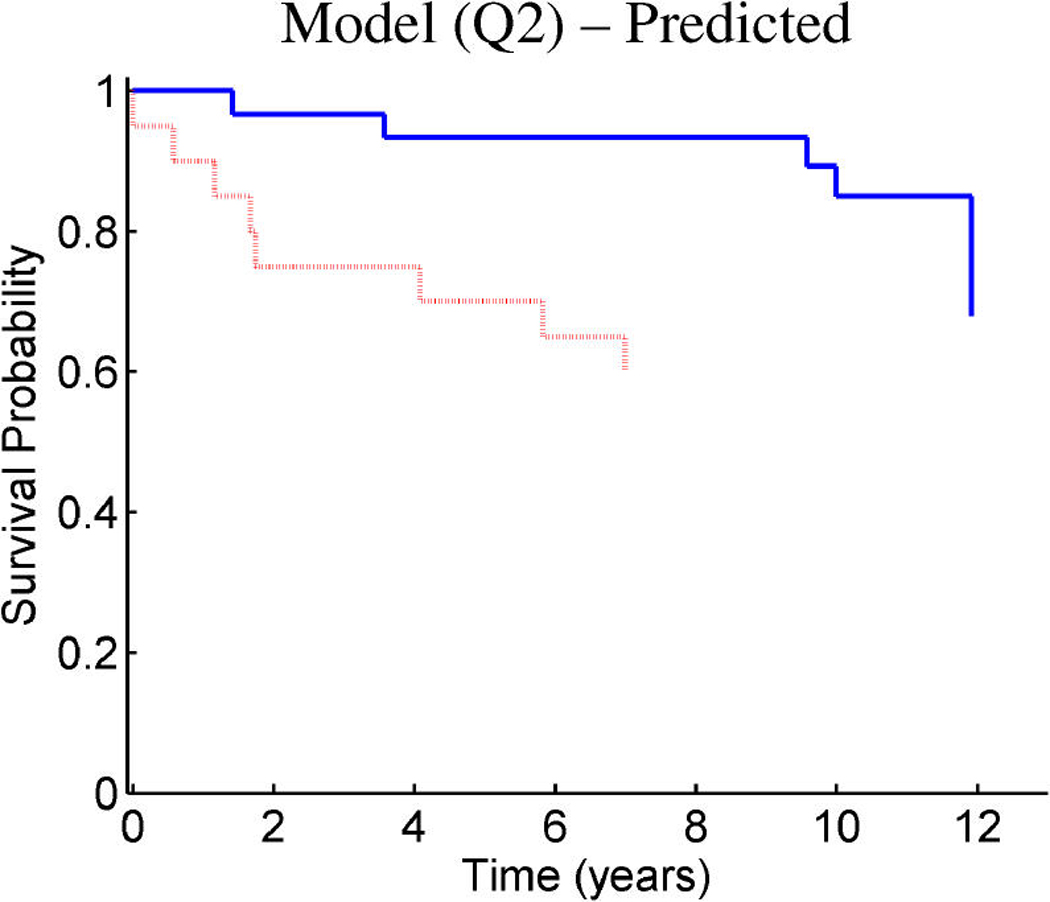
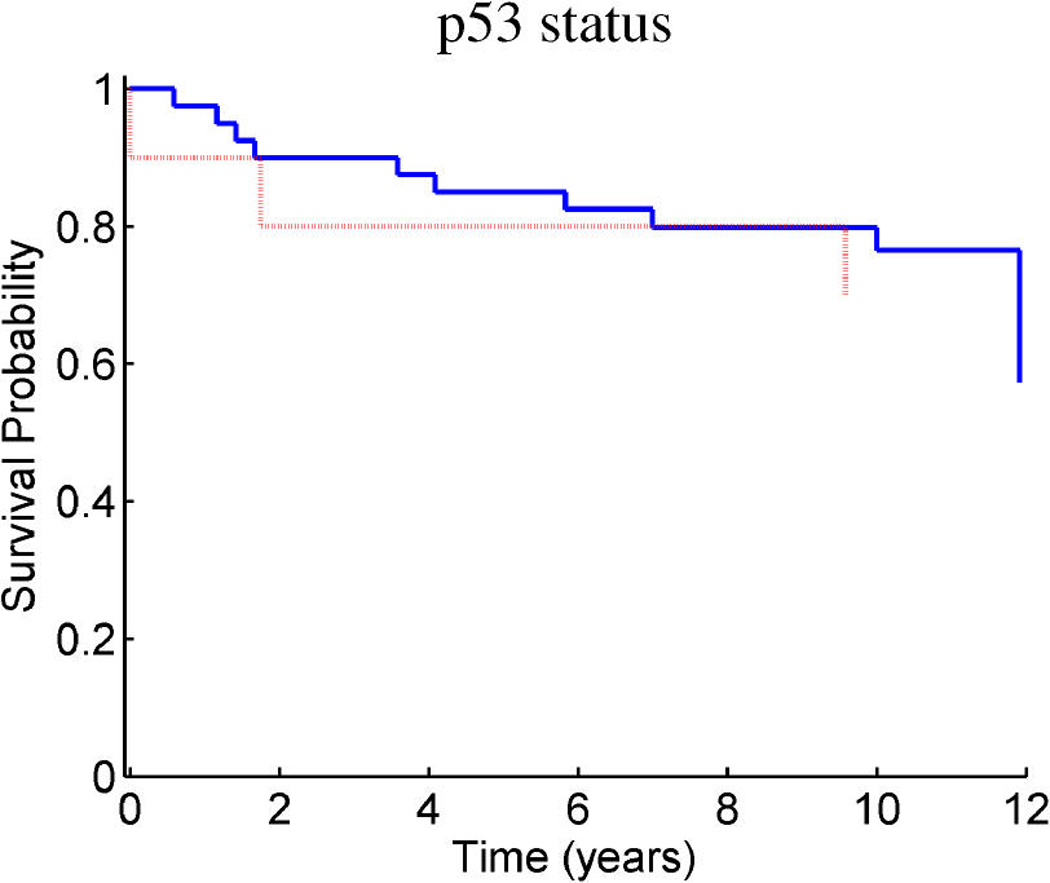
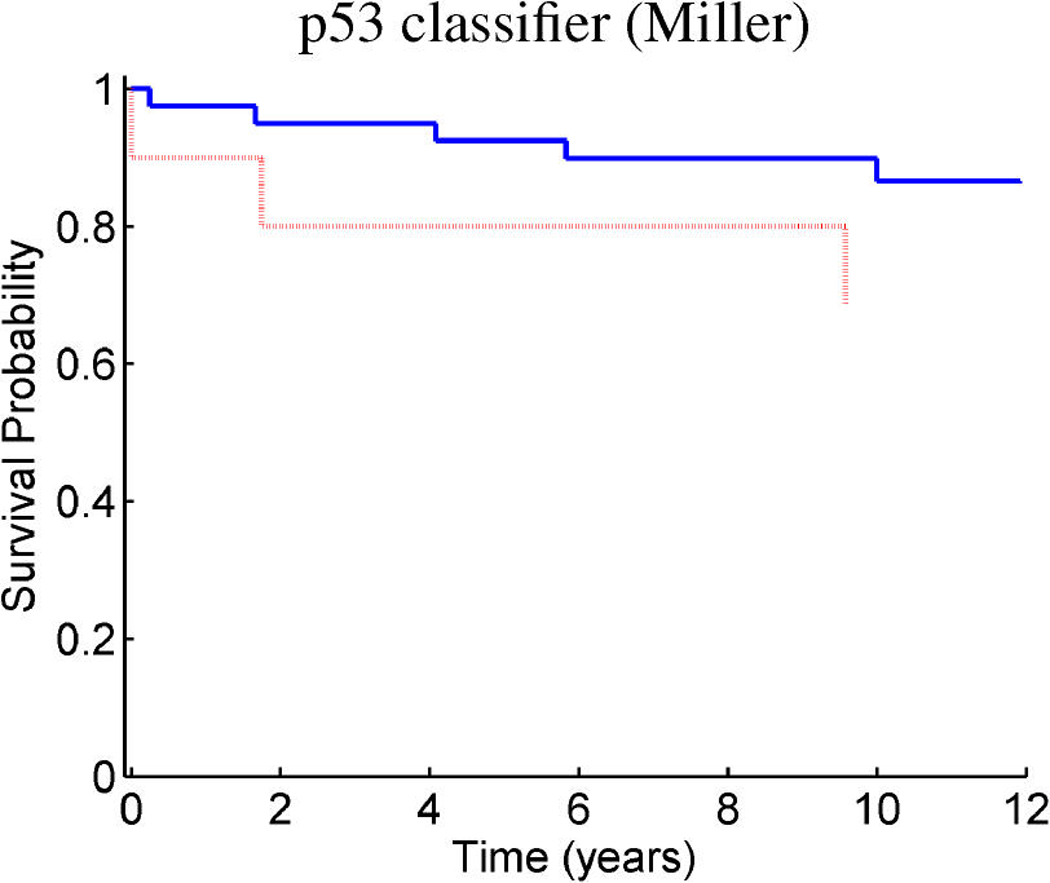
References
-
- Aguilar O, West M. Bayesian Dynamic Factor Models and Portfolio Allocation. Journal of Business & Economic Statistics. 2000;18:338–357.
-
- Albert J, Johnson V. Ordinal Data Models. New York: Springer-Verlag; 1999.
-
- Broet P, Richardson S, Radvanyi F. Bayesian Hierarchical Model for Identifying Changes in Gene Expression From Microarray Experiments. Journal of Computational Biology. 2002;9:671–683. - PubMed
-
- Carvalho C. unpublished doctoral thesis. Duke University, ISDS; 2006. Structure and Sparsity in High-Dimensional Multivariate Analysis. available at http://stat.duke.edu/people/theses/carlos.html.
-
- Clyde M, George E. Model Uncertainty. Statistical Science. 2004;19:81–94.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases