

An EST-based analysis identifies new genes and reveals distinctive gene expression features of Coffea arabica and Coffea canephora
- PMID: 21303543
- PMCID: PMC3045888
- DOI: 10.1186/1471-2229-11-30
An EST-based analysis identifies new genes and reveals distinctive gene expression features of Coffea arabica and Coffea canephora
Abstract
Background: Coffee is one of the world's most important crops; it is consumed worldwide and plays a significant role in the economy of producing countries. Coffea arabica and C. canephora are responsible for 70 and 30% of commercial production, respectively. C. arabica is an allotetraploid from a recent hybridization of the diploid species, C. canephora and C. eugenioides. C. arabica has lower genetic diversity and results in a higher quality beverage than C. canephora. Research initiatives have been launched to produce genomic and transcriptomic data about Coffea spp. as a strategy to improve breeding efficiency.
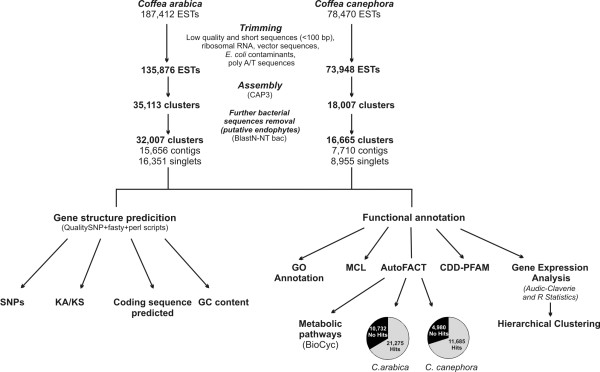
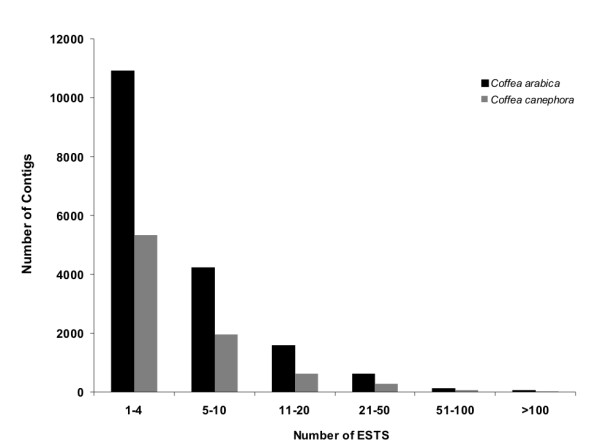
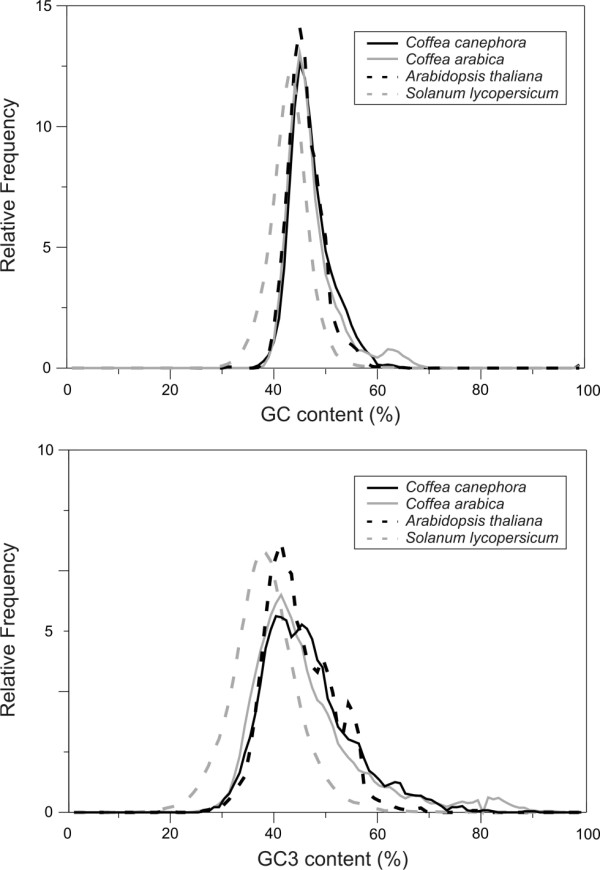
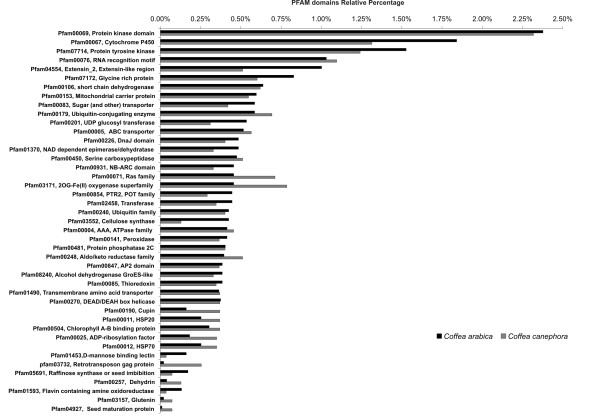
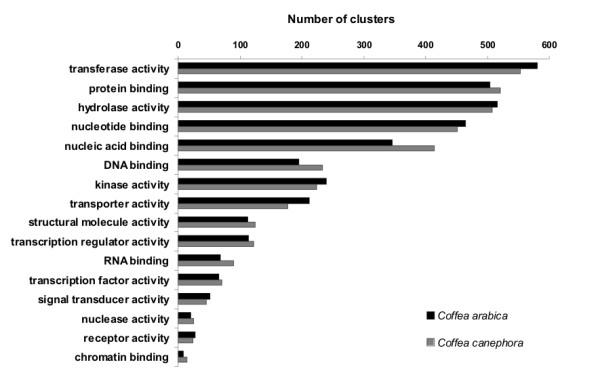
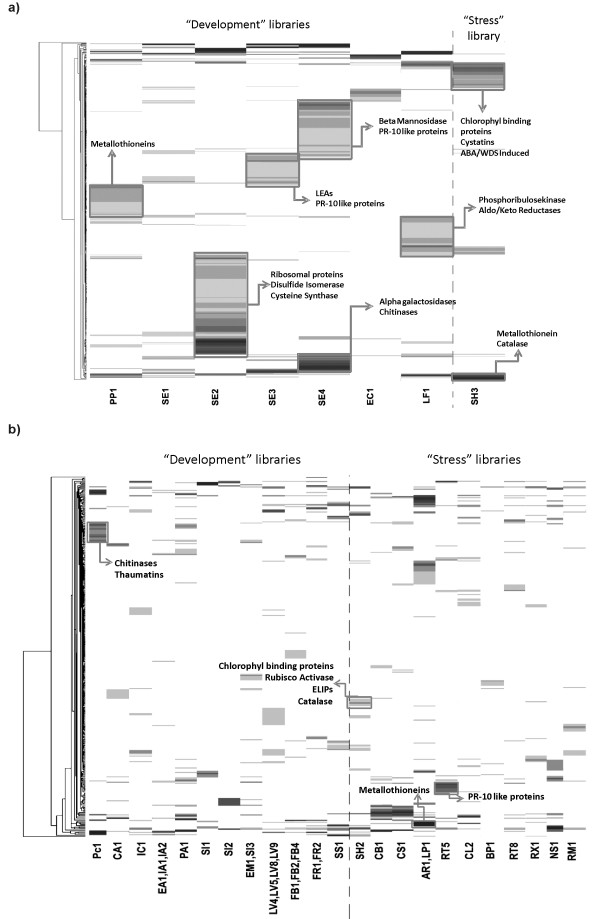
Results: Assembling the expressed sequence tags (ESTs) of C. arabica and C. canephora produced by the Brazilian Coffee Genome Project and the Nestlé-Cornell Consortium revealed 32,007 clusters of C. arabica and 16,665 clusters of C. canephora. We detected different GC3 profiles between these species that are related to their genome structure and mating system. BLAST analysis revealed similarities between coffee and grape (Vitis vinifera) genes. Using KA/KS analysis, we identified coffee genes under purifying and positive selection. Protein domain and gene ontology analyses suggested differences between Coffea spp. data, mainly in relation to complex sugar synthases and nucleotide binding proteins. OrthoMCL was used to identify specific and prevalent coffee protein families when compared to five other plant species. Among the interesting families annotated are new cystatins, glycine-rich proteins and RALF-like peptides. Hierarchical clustering was used to independently group C. arabica and C. canephora expression clusters according to expression data extracted from EST libraries, resulting in the identification of differentially expressed genes. Based on these results, we emphasize gene annotation and discuss plant defenses, abiotic stress and cup quality-related functional categories.
Conclusion: We present the first comprehensive genome-wide transcript profile study of C. arabica and C. canephora, which can be freely assessed by the scientific community at http://www.lge.ibi.unicamp.br/coffea. Our data reveal the presence of species-specific/prevalent genes in coffee that may help to explain particular characteristics of these two crops. The identification of differentially expressed transcripts offers a starting point for the correlation between gene expression profiles and Coffea spp. developmental traits, providing valuable insights for coffee breeding and biotechnology, especially concerning sugar metabolism and stress tolerance.
Figures
References
-
- Pay E. The market for organic and fair-trade coffee. FAO Rome. 2009.
-
- Charrier A, Berthaud J. In: Coffee: botany, biochemistry, and production of beans and beverage. New York. Clifforf MN, Wilsson KC, editor. 1985. Botanical classification of coffee; pp. 13–47.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous
