

Multi-resolution independent component analysis for high-performance tumor classification and biomarker discovery
- PMID: 21342590
- PMCID: PMC3044315
- DOI: 10.1186/1471-2105-12-S1-S7
Multi-resolution independent component analysis for high-performance tumor classification and biomarker discovery
Abstract
Background: Although high-throughput microarray based molecular diagnostic technologies show a great promise in cancer diagnosis, it is still far from a clinical application due to its low and instable sensitivities and specificities in cancer molecular pattern recognition. In fact, high-dimensional and heterogeneous tumor profiles challenge current machine learning methodologies for its small number of samples and large or even huge number of variables (genes). This naturally calls for the use of an effective feature selection in microarray data classification.
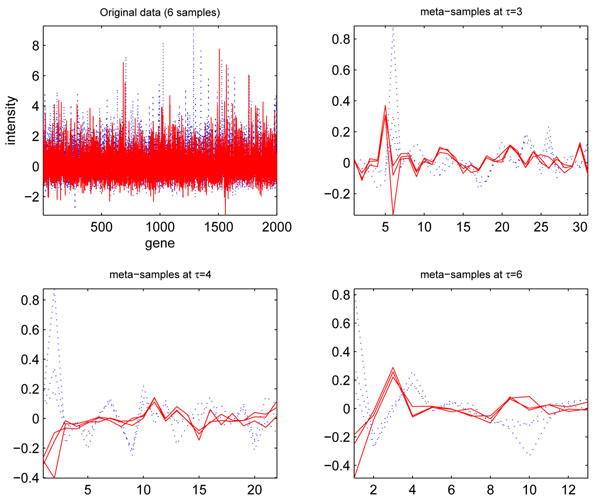
Methods: We propose a novel feature selection method: multi-resolution independent component analysis (MICA) for large-scale gene expression data. This method overcomes the weak points of the widely used transform-based feature selection methods such as principal component analysis (PCA), independent component analysis (ICA), and nonnegative matrix factorization (NMF) by avoiding their global feature-selection mechanism. In addition to demonstrating the effectiveness of the multi-resolution independent component analysis in meaningful biomarker discovery, we present a multi-resolution independent component analysis based support vector machines (MICA-SVM) and linear discriminant analysis (MICA-LDA) to attain high-performance classifications in low-dimensional spaces.
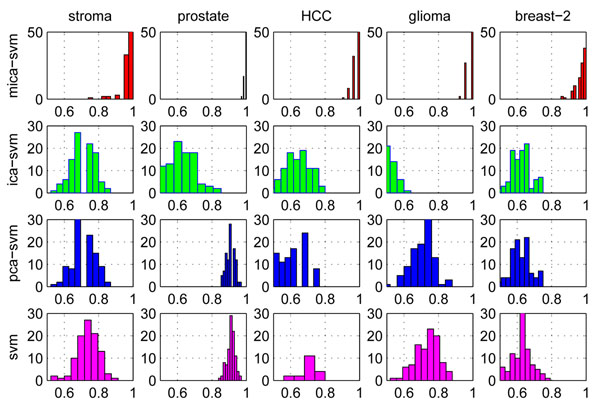
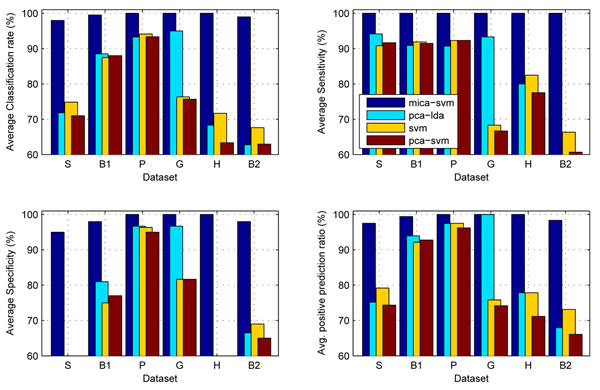
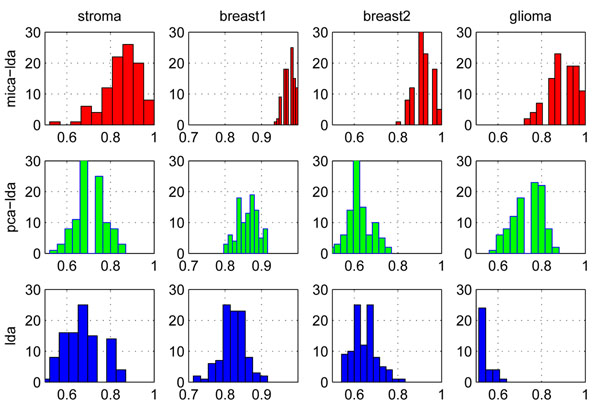
Results: We have demonstrated the superiority and stability of our algorithms by performing comprehensive experimental comparisons with nine state-of-the-art algorithms on six high-dimensional heterogeneous profiles under cross validations. Our classification algorithms, especially, MICA-SVM, not only accomplish clinical or near-clinical level sensitivities and specificities, but also show strong performance stability over its peers in classification. Software that implements the major algorithm and data sets on which this paper focuses are freely available at https://sites.google.com/site/heyaumapbc2011/.
Conclusions: This work suggests a new direction to accelerate microarray technologies into a clinical routine through building a high-performance classifier to attain clinical-level sensitivities and specificities by treating an input profile as a 'profile-biomarker'. The multi-resolution data analysis based redundant global feature suppressing and effective local feature extraction also have a positive impact on large scale 'omics' data mining.
Figures
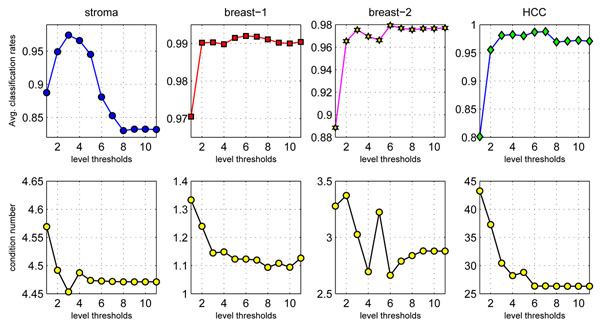
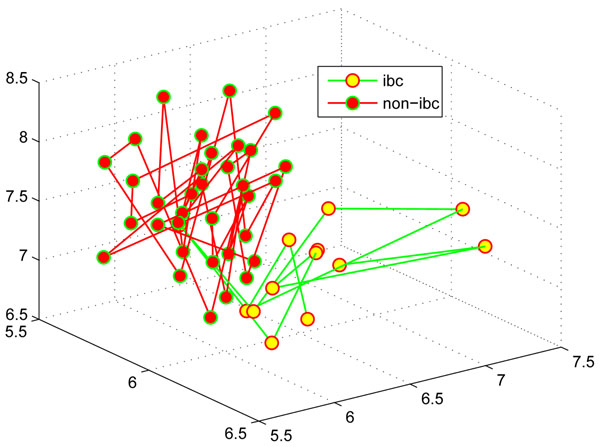
References
-
- Wang Y, Klijn J, Zhang, Atkins, Foeken J. Gene expression profiles and prognostic markers for primary breast cancer. Methods Mol Biol. 2007;377:131–138. full_text. - PubMed
-
- Jolliffe I. Principal component analysis. Springer Series in Statistics, 2nd ed., Springer, New York; 2002.
-
- Hyvärinen A. Fast and robust fixed-point algorithms for independent component analysis. IEEE Transactions on Neural Networks. 1999;10(3):626–634. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
