

TargetMine, an integrated data warehouse for candidate gene prioritisation and target discovery
- PMID: 21408081
- PMCID: PMC3050930
- DOI: 10.1371/journal.pone.0017844
TargetMine, an integrated data warehouse for candidate gene prioritisation and target discovery
Abstract
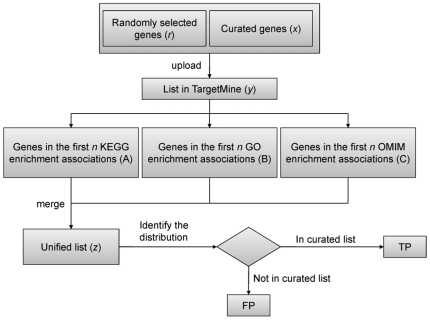
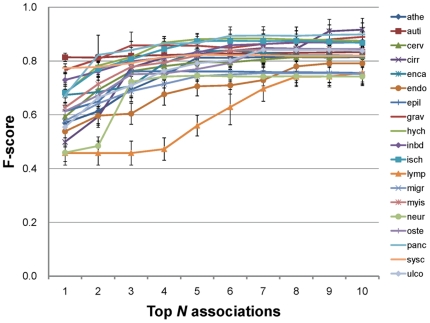
Prioritising candidate genes for further experimental characterisation is a non-trivial challenge in drug discovery and biomedical research in general. An integrated approach that combines results from multiple data types is best suited for optimal target selection. We developed TargetMine, a data warehouse for efficient target prioritisation. TargetMine utilises the InterMine framework, with new data models such as protein-DNA interactions integrated in a novel way. It enables complicated searches that are difficult to perform with existing tools and it also offers integration of custom annotations and in-house experimental data. We proposed an objective protocol for target prioritisation using TargetMine and set up a benchmarking procedure to evaluate its performance. The results show that the protocol can identify known disease-associated genes with high precision and coverage. A demonstration version of TargetMine is available at http://targetmine.nibio.go.jp/.
Conflict of interest statement
Figures


References
-
- Ge H, Walhout AJ, Vidal M. Integrating ‘omic’ information: a bridge between genomics and systems biology. Trends Genet. 2003;19:551–560. - PubMed
-
- Gerstein M, Lan N, Jansen R. Proteomics. Integrating interactomes. Science. 2002;295:284–287. - PubMed
-
- Garcia Castro A, Chen YP, Ragan MA. Information integration in molecular bioscience. Appl Bioinformatics. 2005;4:157–173. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
