

A topological map of the compartmentalized Arabidopsis thaliana leaf metabolome
- PMID: 21423574
- PMCID: PMC3058050
- DOI: 10.1371/journal.pone.0017806
A topological map of the compartmentalized Arabidopsis thaliana leaf metabolome
Abstract
Background: The extensive subcellular compartmentalization of metabolites and metabolism in eukaryotic cells is widely acknowledged and represents a key factor of metabolic activity and functionality. In striking contrast, the knowledge of actual compartmental distribution of metabolites from experimental studies is surprisingly low. However, a precise knowledge of, possibly all, metabolites and their subcellular distributions remains a key prerequisite for the understanding of any cellular function.
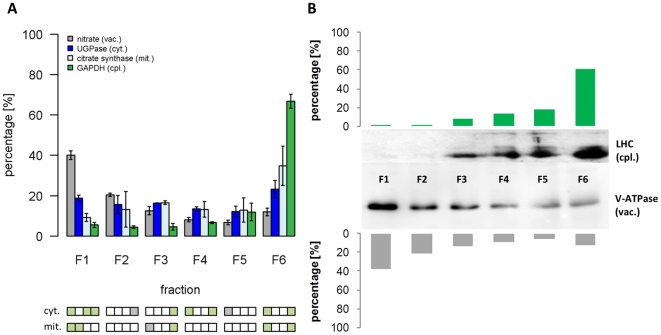
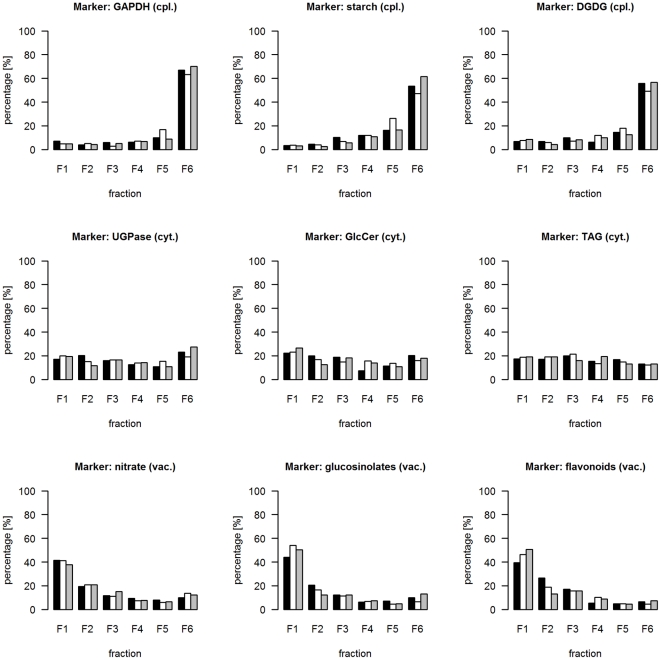
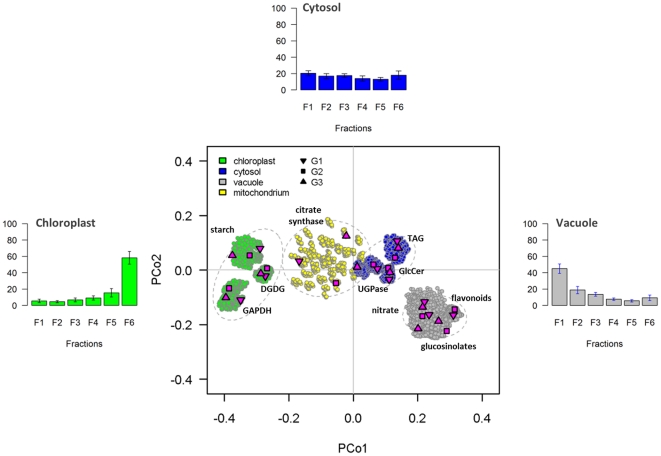
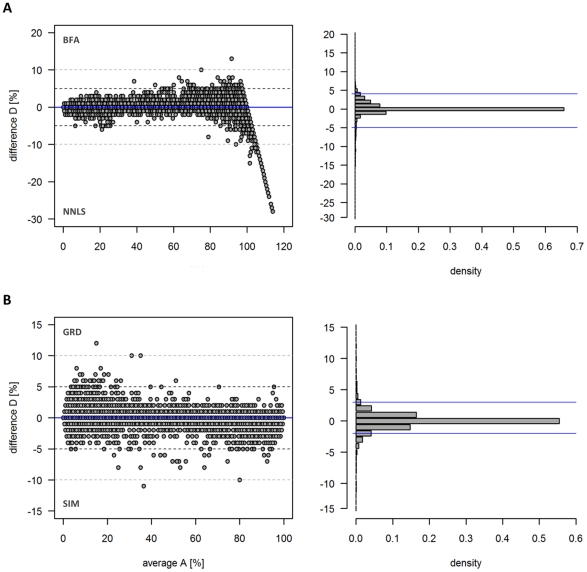
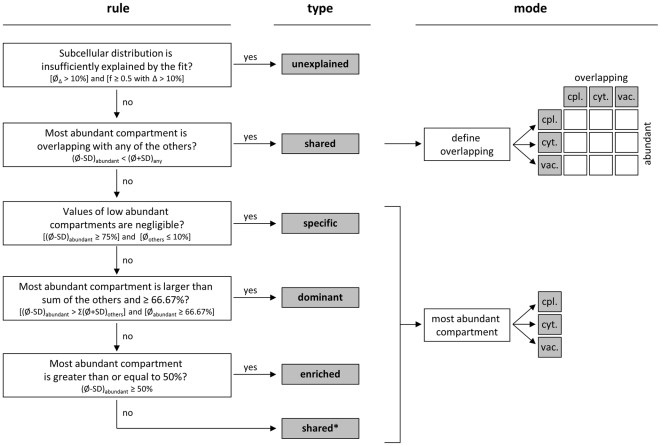
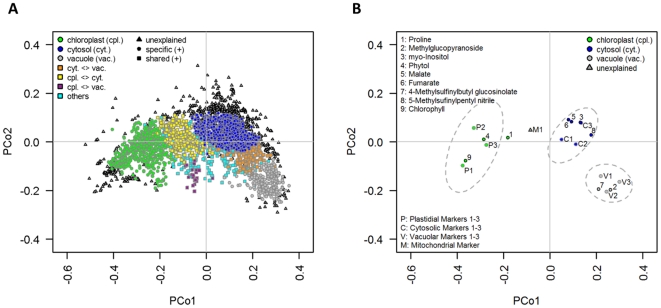
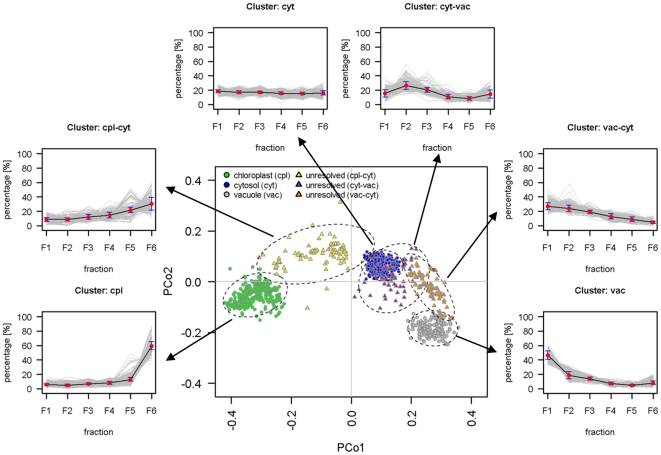
Methodology/principal findings: Here we describe results for the subcellular distribution of 1,117 polar and 2,804 lipophilic mass spectrometric features associated to known and unknown compounds from leaves of the model plant Arabidopsis thaliana. Using an optimized non-aqueous fractionation protocol in conjunction with GC/MS- and LC/MS-based metabolite profiling, 81.5% of the metabolic data could be associated to one of three subcellular compartments: the cytosol (including the mitochondria), vacuole, or plastids. Statistical analysis using a marker-'free' approach revealed that 18.5% of these metabolites show intermediate distributions, which can either be explained by transport processes or by additional subcellular compartments.
Conclusion/significance: Next to a functional and conceptual workflow for the efficient, highly resolved metabolite analysis of the fractionated Arabidopsis thaliana leaf metabolome, a detailed survey of the subcellular distribution of several compounds, in the graphical format of a topological map, is provided. This complex data set therefore does not only contain a rich repository of metabolic information, but due to thorough validation and testing by statistical methods, represents an initial step in the analysis of metabolite dynamics and fluxes within and between subcellular compartments.
Conflict of interest statement
Figures

Similar articles
-
Analysis of subcellular metabolite distributions within Arabidopsis thaliana leaf tissue: a primer for subcellular metabolomics.Methods Mol Biol. 2014;1062:575-96. doi: 10.1007/978-1-62703-580-4_30. Methods Mol Biol. 2014. PMID: 24057387
-
Subcellular reprogramming of metabolism during cold acclimation in Arabidopsis thaliana.Plant Cell Environ. 2017 May;40(5):602-610. doi: 10.1111/pce.12836. Epub 2016 Oct 24. Plant Cell Environ. 2017. PMID: 27642699
-
Resolving subcellular plant metabolism.Plant J. 2019 Nov;100(3):438-455. doi: 10.1111/tpj.14472. Epub 2019 Sep 25. Plant J. 2019. PMID: 31361942 Free PMC article.
-
Compartmentation in plant metabolism.J Exp Bot. 2007;58(1):35-47. doi: 10.1093/jxb/erl134. Epub 2006 Oct 9. J Exp Bot. 2007. PMID: 17030538 Review.
-
Should we consider subcellular compartmentalization of metabolites, and if so, how do we measure them?Curr Opin Clin Nutr Metab Care. 2019 Sep;22(5):347-354. doi: 10.1097/MCO.0000000000000580. Curr Opin Clin Nutr Metab Care. 2019. PMID: 31365463 Free PMC article. Review.
Cited by
-
Cytoplasmic genetic variation and extensive cytonuclear interactions influence natural variation in the metabolome.Elife. 2013 Oct 8;2:e00776. doi: 10.7554/eLife.00776. Elife. 2013. PMID: 24150750 Free PMC article.
-
Reconstruction of Arabidopsis metabolic network models accounting for subcellular compartmentalization and tissue-specificity.Proc Natl Acad Sci U S A. 2012 Jan 3;109(1):339-44. doi: 10.1073/pnas.1100358109. Epub 2011 Dec 19. Proc Natl Acad Sci U S A. 2012. PMID: 22184215 Free PMC article.
-
Impaired cell growth under ammonium stress explained by modeling the energy cost of vacuole expansion in tomato leaves.Plant J. 2022 Nov;112(4):1014-1028. doi: 10.1111/tpj.15991. Epub 2022 Nov 4. Plant J. 2022. PMID: 36198049 Free PMC article.
-
Identification of a plastidial phenylalanine exporter that influences flux distribution through the phenylalanine biosynthetic network.Nat Commun. 2015 Sep 10;6:8142. doi: 10.1038/ncomms9142. Nat Commun. 2015. PMID: 26356302 Free PMC article.
-
Metabolic fluxes in an illuminated Arabidopsis rosette.Plant Cell. 2013 Feb;25(2):694-714. doi: 10.1105/tpc.112.106989. Epub 2013 Feb 26. Plant Cell. 2013. PMID: 23444331 Free PMC article.
References
-
- Linka N, Weber AP. Intracellular metabolite transporters in plants. Mol Plant. 2010;3:21–53. - PubMed
-
- Weber AP, Fischer K. Making the connections–the crucial role of metabolite transporters at the interface between chloroplast and cytosol. FEBS Lett. 2007;581:2215–2222. - PubMed
-
- Martinoia E, Maeshima M, Neuhaus HE. Vacuolar transporters and their essential role in plant metabolism. J Exp Bot. 2007;58:83–102. - PubMed
-
- Stitt M, Fernie AR. From measurements of metabolites to metabolomics: an ‘on the fly’ perspective illustrated by recent studies of carbon-nitrogen interactions. Curr Opin Biotechnol. 2003;14:136–144. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
