

Learning from sensory and reward prediction errors during motor adaptation
- PMID: 21423711
- PMCID: PMC3053313
- DOI: 10.1371/journal.pcbi.1002012
Learning from sensory and reward prediction errors during motor adaptation
Abstract
Voluntary motor commands produce two kinds of consequences. Initially, a sensory consequence is observed in terms of activity in our primary sensory organs (e.g., vision, proprioception). Subsequently, the brain evaluates the sensory feedback and produces a subjective measure of utility or usefulness of the motor commands (e.g., reward). As a result, comparisons between predicted and observed consequences of motor commands produce two forms of prediction error. How do these errors contribute to changes in motor commands? Here, we considered a reach adaptation protocol and found that when high quality sensory feedback was available, adaptation of motor commands was driven almost exclusively by sensory prediction errors. This form of learning had a distinct signature: as motor commands adapted, the subjects altered their predictions regarding sensory consequences of motor commands, and generalized this learning broadly to neighboring motor commands. In contrast, as the quality of the sensory feedback degraded, adaptation of motor commands became more dependent on reward prediction errors. Reward prediction errors produced comparable changes in the motor commands, but produced no change in the predicted sensory consequences of motor commands, and generalized only locally. Because we found that there was a within subject correlation between generalization patterns and sensory remapping, it is plausible that during adaptation an individual's relative reliance on sensory vs. reward prediction errors could be inferred. We suggest that while motor commands change because of sensory and reward prediction errors, only sensory prediction errors produce a change in the neural system that predicts sensory consequences of motor commands.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
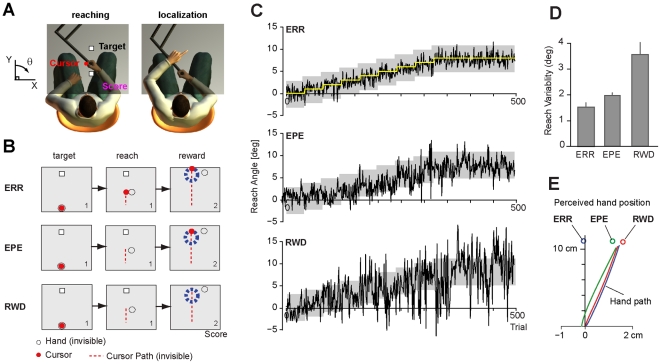
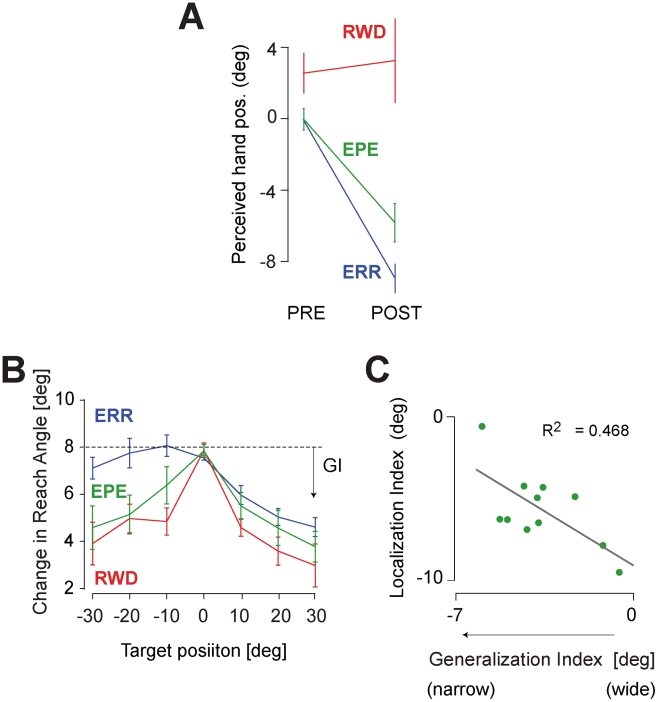
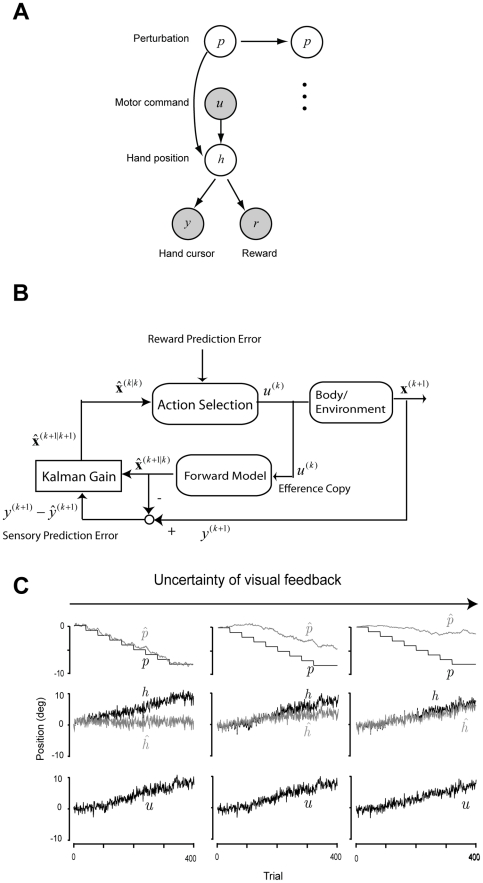
 to make a transition of the state of the body and task from
to make a transition of the state of the body and task from  to
to  . The state variable
. The state variable  includes three elements: hand position h, perturbation p, and the position t. The brain observes the part of the state of the body
includes three elements: hand position h, perturbation p, and the position t. The brain observes the part of the state of the body  . At the same time, the learner predicts the transition of the body state
. At the same time, the learner predicts the transition of the body state  from the efference copy of the motor command. Kalman filtering correct the prediction to minimize the sensory prediction error
from the efference copy of the motor command. Kalman filtering correct the prediction to minimize the sensory prediction error  to have the updated state
to have the updated state  . The action selector selects the optimal action as a function of the updated state at the next trial. (C) Sample disturbance and the response of the model. The task is to control the reach angle. Clockwise (CW) direction is positive and the target is at 0°. The uncertainty of the visual feedback was controlled to modulates the Kalman gain. The simulations predict a remapping regarding estimated hand position
. The action selector selects the optimal action as a function of the updated state at the next trial. (C) Sample disturbance and the response of the model. The task is to control the reach angle. Clockwise (CW) direction is positive and the target is at 0°. The uncertainty of the visual feedback was controlled to modulates the Kalman gain. The simulations predict a remapping regarding estimated hand position  modulated by the level of visual uncertainty.
modulated by the level of visual uncertainty.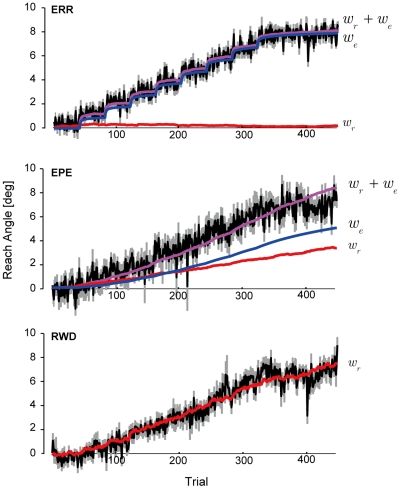
 , where
, where  was updated by the sensory-prediction error and
was updated by the sensory-prediction error and  was updated by the reward prediction error. The best fit parameters predict the update of the two memories. The black think line is the averaged subject's reach angle during the adaptation period. The gray shadow is SEM. The superimposed purple line is the estimated reach angle from the model which is a combination of
was updated by the reward prediction error. The best fit parameters predict the update of the two memories. The black think line is the averaged subject's reach angle during the adaptation period. The gray shadow is SEM. The superimposed purple line is the estimated reach angle from the model which is a combination of  (red) and
(red) and  (blue). In the RWD condition, the motor commands are updated by only the reward-prediction error:
(blue). In the RWD condition, the motor commands are updated by only the reward-prediction error:  .
.Similar articles
-
The Errors of Our Ways: Understanding Error Representations in Cerebellar-Dependent Motor Learning.Cerebellum. 2016 Apr;15(2):93-103. doi: 10.1007/s12311-015-0685-5. Cerebellum. 2016. PMID: 26112422 Free PMC article. Review.
-
The Neural Feedback Response to Error As a Teaching Signal for the Motor Learning System.J Neurosci. 2016 Apr 27;36(17):4832-45. doi: 10.1523/JNEUROSCI.0159-16.2016. J Neurosci. 2016. PMID: 27122039 Free PMC article.
-
Neural signatures of reward and sensory error feedback processing in motor learning.J Neurophysiol. 2019 Apr 1;121(4):1561-1574. doi: 10.1152/jn.00792.2018. Epub 2019 Feb 27. J Neurophysiol. 2019. PMID: 30811259 Free PMC article.
-
Task errors contribute to implicit aftereffects in sensorimotor adaptation.Eur J Neurosci. 2018 Dec;48(11):3397-3409. doi: 10.1111/ejn.14213. Epub 2018 Nov 9. Eur J Neurosci. 2018. PMID: 30339299 Clinical Trial.
-
Error correction, sensory prediction, and adaptation in motor control.Annu Rev Neurosci. 2010;33:89-108. doi: 10.1146/annurev-neuro-060909-153135. Annu Rev Neurosci. 2010. PMID: 20367317 Review.
Cited by
-
Continuous reports of sensed hand position during sensorimotor adaptation.J Neurophysiol. 2020 Oct 1;124(4):1122-1130. doi: 10.1152/jn.00242.2020. Epub 2020 Sep 9. J Neurophysiol. 2020. PMID: 32902347 Free PMC article.
-
The Errors of Our Ways: Understanding Error Representations in Cerebellar-Dependent Motor Learning.Cerebellum. 2016 Apr;15(2):93-103. doi: 10.1007/s12311-015-0685-5. Cerebellum. 2016. PMID: 26112422 Free PMC article. Review.
-
Sensory prediction errors, not performance errors, update memories in visuomotor adaptation.Sci Rep. 2018 Nov 7;8(1):16483. doi: 10.1038/s41598-018-34598-y. Sci Rep. 2018. PMID: 30405177 Free PMC article.
-
Clustering analysis of movement kinematics in reinforcement learning.J Neurophysiol. 2022 Feb 1;127(2):341-353. doi: 10.1152/jn.00229.2021. Epub 2021 Dec 22. J Neurophysiol. 2022. PMID: 34936514 Free PMC article.
-
Feedback Modulates Audio-Visual Spatial Recalibration.Front Integr Neurosci. 2020 Jan 17;13:74. doi: 10.3389/fnint.2019.00074. eCollection 2019. Front Integr Neurosci. 2020. PMID: 32009913 Free PMC article.
References
-
- Synofzik M, Thier P, Lindner A. Internalizing agency of self-action: perception of one's own hand movements depends on an adaptable prediction about the sensory action outcome. J Neurophysiol. 2006;96:1592–1601. - PubMed
-
- Synofzik M, Lindner A, Thier P. The cerebellum updates predictions about the visual consequences of one's behavior. Curr Biol. 2008;18:814–818. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
