

Clustering more than two million biomedical publications: comparing the accuracies of nine text-based similarity approaches
- PMID: 21437291
- PMCID: PMC3060097
- DOI: 10.1371/journal.pone.0018029
Clustering more than two million biomedical publications: comparing the accuracies of nine text-based similarity approaches
Abstract
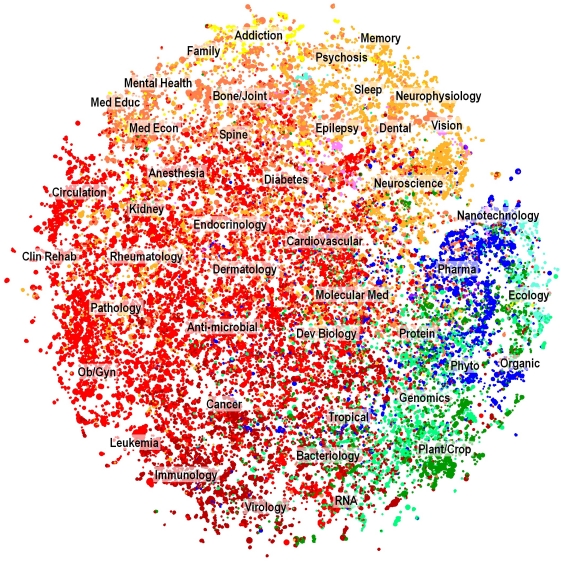
Background: We investigate the accuracy of different similarity approaches for clustering over two million biomedical documents. Clustering large sets of text documents is important for a variety of information needs and applications such as collection management and navigation, summary and analysis. The few comparisons of clustering results from different similarity approaches have focused on small literature sets and have given conflicting results. Our study was designed to seek a robust answer to the question of which similarity approach would generate the most coherent clusters of a biomedical literature set of over two million documents.
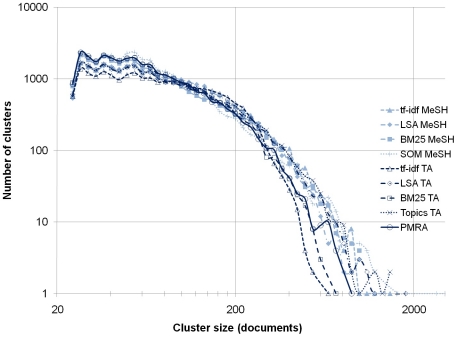
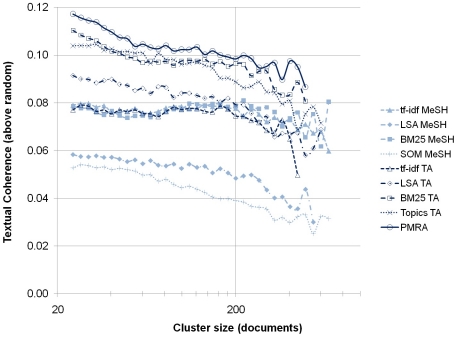
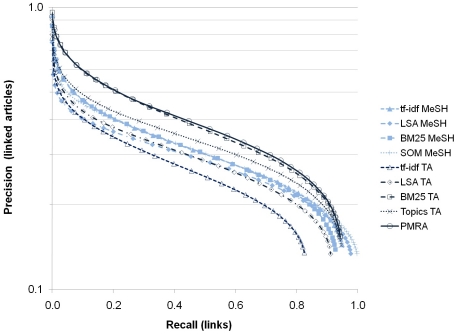
Methodology: We used a corpus of 2.15 million recent (2004-2008) records from MEDLINE, and generated nine different document-document similarity matrices from information extracted from their bibliographic records, including titles, abstracts and subject headings. The nine approaches were comprised of five different analytical techniques with two data sources. The five analytical techniques are cosine similarity using term frequency-inverse document frequency vectors (tf-idf cosine), latent semantic analysis (LSA), topic modeling, and two Poisson-based language models--BM25 and PMRA (PubMed Related Articles). The two data sources were a) MeSH subject headings, and b) words from titles and abstracts. Each similarity matrix was filtered to keep the top-n highest similarities per document and then clustered using a combination of graph layout and average-link clustering. Cluster results from the nine similarity approaches were compared using (1) within-cluster textual coherence based on the Jensen-Shannon divergence, and (2) two concentration measures based on grant-to-article linkages indexed in MEDLINE.
Conclusions: PubMed's own related article approach (PMRA) generated the most coherent and most concentrated cluster solution of the nine text-based similarity approaches tested, followed closely by the BM25 approach using titles and abstracts. Approaches using only MeSH subject headings were not competitive with those based on titles and abstracts.
Conflict of interest statement
Figures
References
-
- Cooper WS. On selecting a measure of retrieval effectiveness. Journal of the American Society for Information Science. 1973;24:87–100.
-
- Robertson SE, Sparck Jones K. Relevance weighting of search terms. Journal of the American Society for Information Science. 1976;27:129–146.
-
- Salton G, Buckley C. Term-weighting approaches in automatic text retrieval. Information Processing & Management. 1988;24:513–523.
-
- Belkin NJ, Kantor P, Fox EA, Shaw JA. Combining the evidence of multiple query representations for information retrieval. Information Processing & Management. 1995;31:431–448.
-
- Jardine N, van Rijsbergen CJ. The use of hierarchic clustering in information retrieval. Information Storage and Retrieval. 1971;7:217–240.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
