

Neural correlates of forward planning in a spatial decision task in humans
- PMID: 21471389
- PMCID: PMC3108440
- DOI: 10.1523/JNEUROSCI.4647-10.2011
Neural correlates of forward planning in a spatial decision task in humans
Abstract
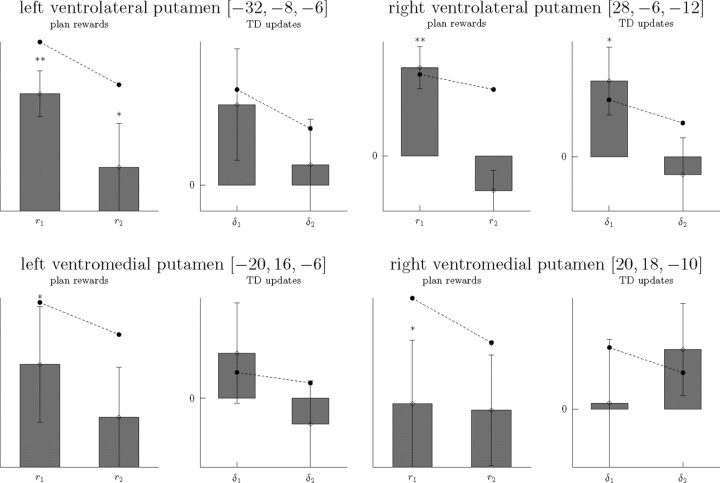
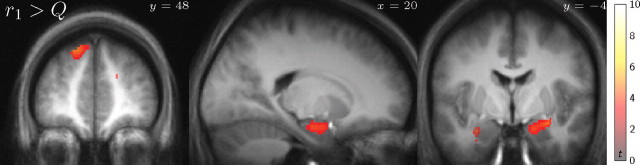
Although reinforcement learning (RL) theories have been influential in characterizing the mechanisms for reward-guided choice in the brain, the predominant temporal difference (TD) algorithm cannot explain many flexible or goal-directed actions that have been demonstrated behaviorally. We investigate such actions by contrasting an RL algorithm that is model based, in that it relies on learning a map or model of the task and planning within it, to traditional model-free TD learning. To distinguish these approaches in humans, we used functional magnetic resonance imaging in a continuous spatial navigation task, in which frequent changes to the layout of the maze forced subjects continually to relearn their favored routes, thereby exposing the RL mechanisms used. We sought evidence for the neural substrates of such mechanisms by comparing choice behavior and blood oxygen level-dependent (BOLD) signals to decision variables extracted from simulations of either algorithm. Both choices and value-related BOLD signals in striatum, although most often associated with TD learning, were better explained by the model-based theory. Furthermore, predecessor quantities for the model-based value computation were correlated with BOLD signals in the medial temporal lobe and frontal cortex. These results point to a significant extension of both the computational and anatomical substrates for RL in the brain.
Figures

References
-
- Ainslie G. Cambridge, UK: Cambridge UP; 2001. Breakdown of will.
-
- Balleine BW, Dickinson A. Goal-directed instrumental action: contingency and incentive learning and their cortical substrates. Neuropharmacology. 1998;37:407–419. - PubMed
-
- Balleine BW, Daw ND, O'Doherty JP. Multiple forms of value learning and the function of dopamine. In: Glimcher PW, Camerer CF, Fehr E, Poldrack RA, editors. Neuroeconomics: decision making and the brain, Chap 24. London: Academic; 2008. pp. 367–387.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases