

Evaluating ortholog prediction algorithms in a yeast model clade
- PMID: 21533202
- PMCID: PMC3076445
- DOI: 10.1371/journal.pone.0018755
Evaluating ortholog prediction algorithms in a yeast model clade
Abstract
Background: Accurate identification of orthologs is crucial for evolutionary studies and for functional annotation. Several algorithms have been developed for ortholog delineation, but so far, manually curated genome-scale biological databases of orthologous genes for algorithm evaluation have been lacking. We evaluated four popular ortholog prediction algorithms (MultiParanoid; and OrthoMCL; RBH: Reciprocal Best Hit; RSD: Reciprocal Smallest Distance; the last two extended into clustering algorithms cRBH and cRSD, respectively, so that they can predict orthologs across multiple taxa) against a set of 2,723 groups of high-quality curated orthologs from 6 Saccharomycete yeasts in the Yeast Gene Order Browser.
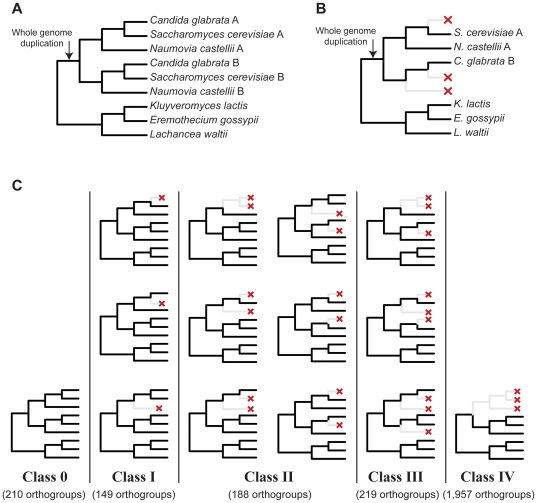
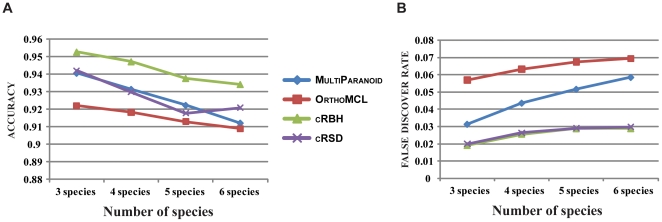
Results: Examination of sensitivity [TP/(TP+FN)], specificity [TN/(TN+FP)], and accuracy [(TP+TN)/(TP+TN+FP+FN)] across a broad parameter range showed that cRBH was the most accurate and specific algorithm, whereas OrthoMCL was the most sensitive. Evaluation of the algorithms across a varying number of species showed that cRBH had the highest accuracy and lowest false discovery rate [FP/(FP+TP)], followed by cRSD. Of the six species in our set, three descended from an ancestor that underwent whole genome duplication. Subsequent differential duplicate loss events in the three descendants resulted in distinct classes of gene loss patterns, including cases where the genes retained in the three descendants are paralogs, constituting 'traps' for ortholog prediction algorithms. We found that the false discovery rate of all algorithms dramatically increased in these traps.
Conclusions: These results suggest that simple algorithms, like cRBH, may be better ortholog predictors than more complex ones (e.g., OrthoMCL and MultiParanoid) for evolutionary and functional genomics studies where the objective is the accurate inference of single-copy orthologs (e.g., molecular phylogenetics), but that all algorithms fail to accurately predict orthologs when paralogy is rampant.
Conflict of interest statement
Figures




References
-
- Fitch WM. Distinguishing homologous from analogous proteins. Syst Zool. 1970;19:99–113. - PubMed
-
- Koonin EV. Orthologs, paralogs, and evolutionary genomics. Annu Rev Genet. 2005;39:309–338. - PubMed
-
- Bork P, Dandekar T, Diaz-Lazcoz Y, Eisenhaber F, Huynen M, et al. Predicting function: From genes to genomes and back. J Mol Biol. 1998;283:707–725. - PubMed
-
- Mirny LA, Gelfand MS. Using orthologous and paralogous proteins to identify specificity determining residues. Genome Biol. 2002;3:preprint0002.0001–0002.0020. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Miscellaneous
