

Eye guidance in natural vision: reinterpreting salience
- PMID: 21622729
- PMCID: PMC3134223
- DOI: 10.1167/11.5.5
Eye guidance in natural vision: reinterpreting salience
Abstract
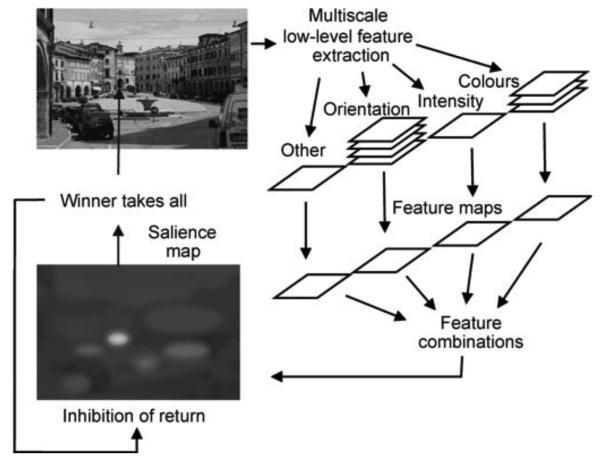
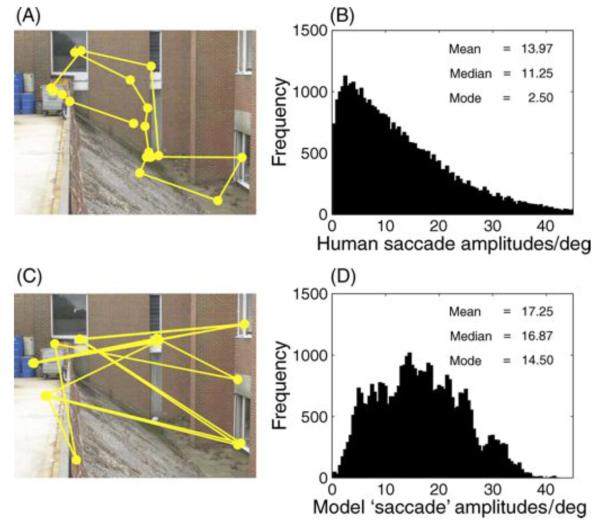
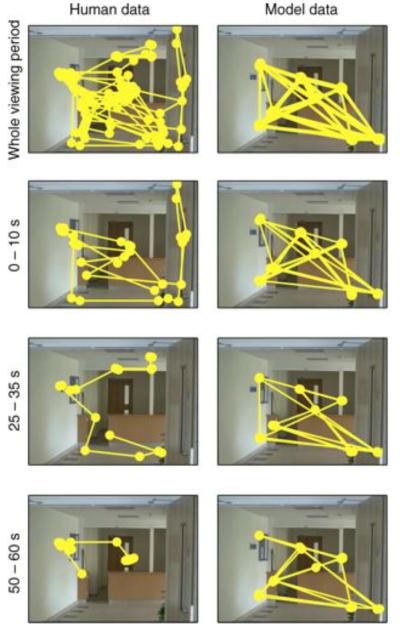
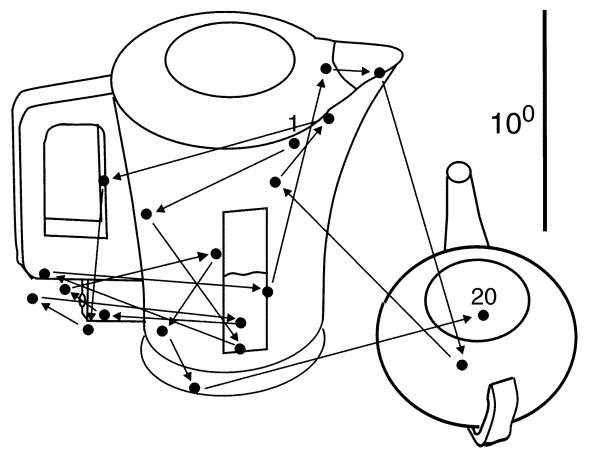
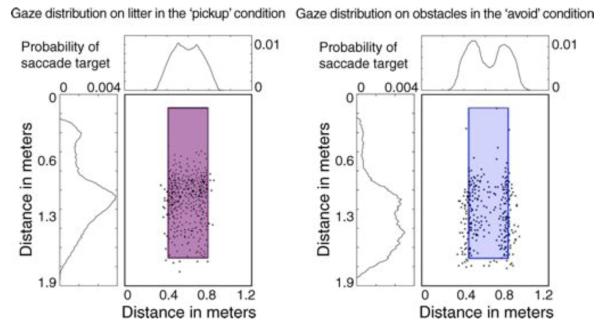
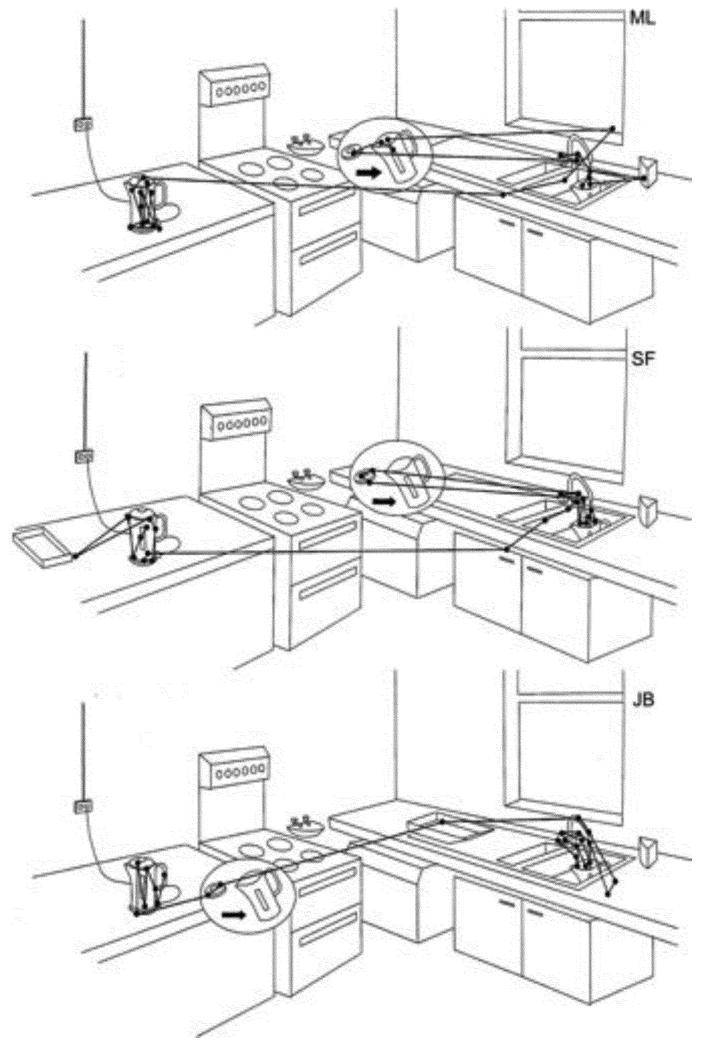
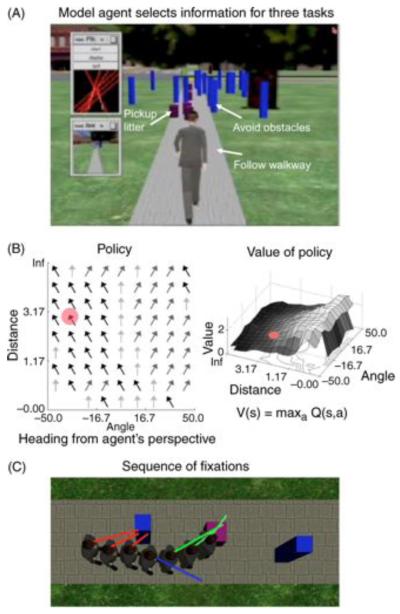
Models of gaze allocation in complex scenes are derived mainly from studies of static picture viewing. The dominant framework to emerge has been image salience, where properties of the stimulus play a crucial role in guiding the eyes. However, salience-based schemes are poor at accounting for many aspects of picture viewing and can fail dramatically in the context of natural task performance. These failures have led to the development of new models of gaze allocation in scene viewing that address a number of these issues. However, models based on the picture-viewing paradigm are unlikely to generalize to a broader range of experimental contexts, because the stimulus context is limited, and the dynamic, task-driven nature of vision is not represented. We argue that there is a need to move away from this class of model and find the principles that govern gaze allocation in a broader range of settings. We outline the major limitations of salience-based selection schemes and highlight what we have learned from studies of gaze allocation in natural vision. Clear principles of selection are found across many instances of natural vision and these are not the principles that might be expected from picture-viewing studies. We discuss the emerging theoretical framework for gaze allocation on the basis of reward maximization and uncertainty reduction.
Figures
References
-
- Bahill AT, Adler D, Stark L. Most naturally occurring human saccades have magnitudes of 15 degrees or less. Investigative Ophthalmology. 1975;14:468–469. - PubMed
-
- Bair W, O'Keefe LP. The influence of fixational eye movements on the response of neurons in area MT of the macaque. Visual Neuroscience. 1998;15:779–786. - PubMed
-
- Becker W. The control of eye movements in the saccadic system. Bibliotheca Ophthalmologica. 1972;82:233–243. - PubMed
-
- Becker W. Saccades. In: Carpenter RHS, editor. Vision & visual dysfunction: Eye movements. Vol. 8. Macmillan; Basingstoke, UK: 1991. pp. 95–137.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
