

Counterfactual choice and learning in a neural network centered on human lateral frontopolar cortex
- PMID: 21738446
- PMCID: PMC3125157
- DOI: 10.1371/journal.pbio.1001093
Counterfactual choice and learning in a neural network centered on human lateral frontopolar cortex
Abstract
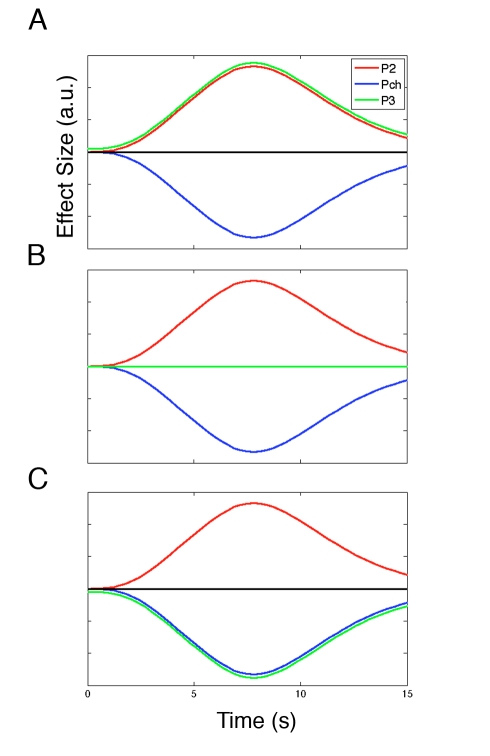
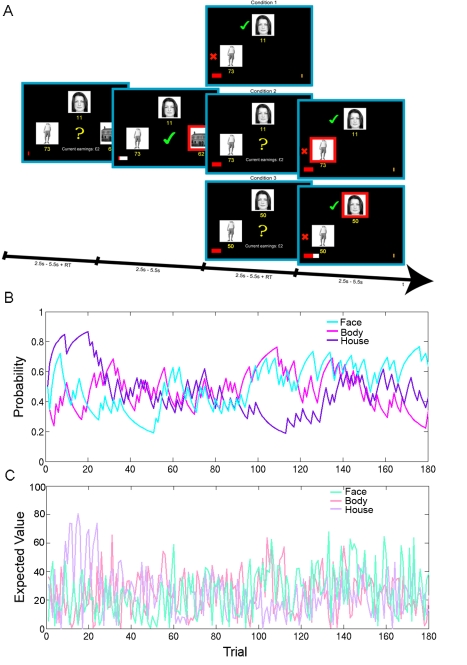
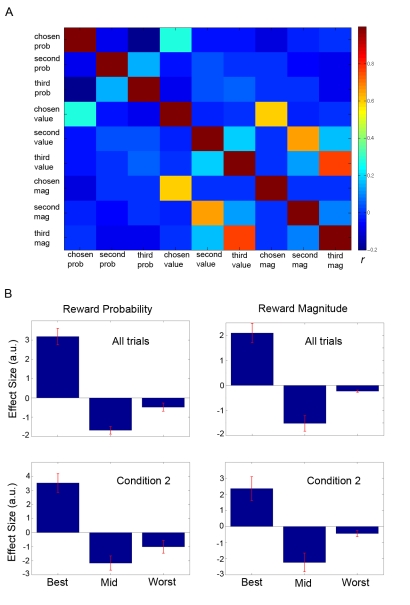
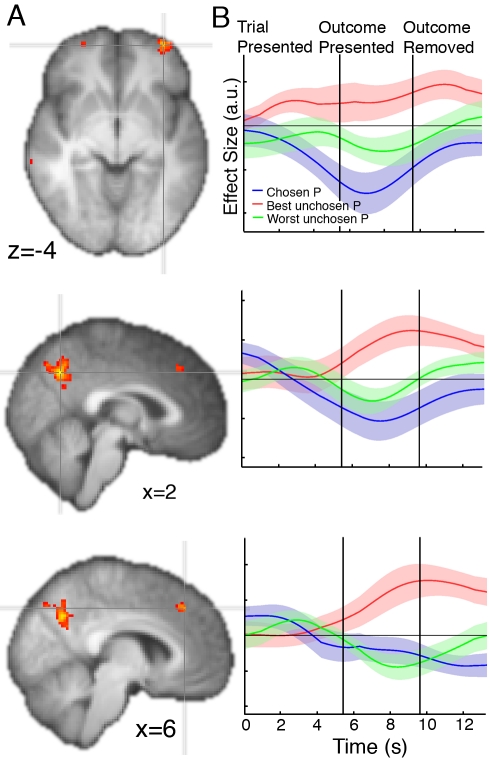
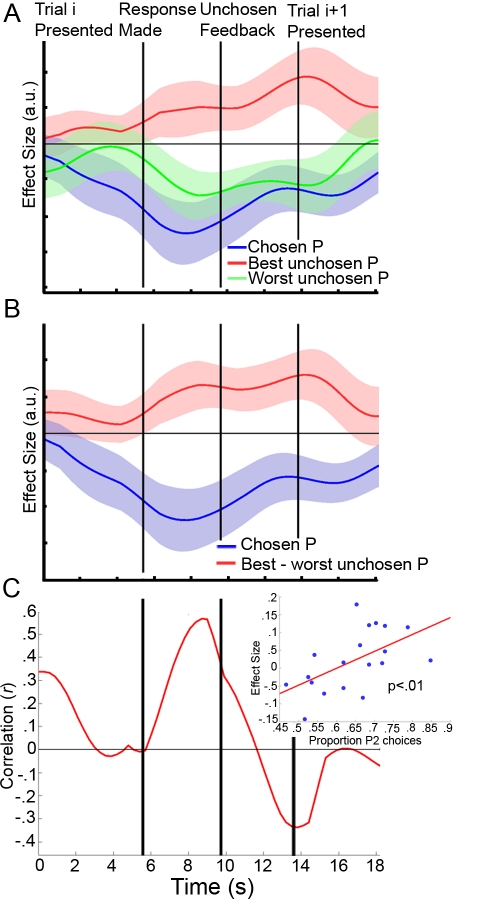
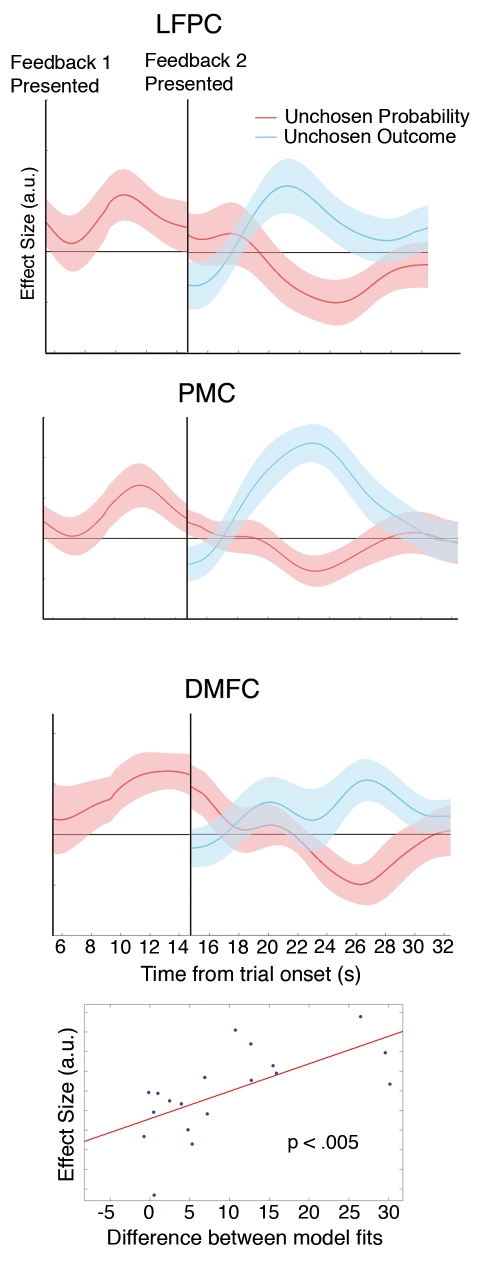
Decision making and learning in a real-world context require organisms to track not only the choices they make and the outcomes that follow but also other untaken, or counterfactual, choices and their outcomes. Although the neural system responsible for tracking the value of choices actually taken is increasingly well understood, whether a neural system tracks counterfactual information is currently unclear. Using a three-alternative decision-making task, a Bayesian reinforcement-learning algorithm, and fMRI, we investigated the coding of counterfactual choices and prediction errors in the human brain. Rather than representing evidence favoring multiple counterfactual choices, lateral frontal polar cortex (lFPC), dorsomedial frontal cortex (DMFC), and posteromedial cortex (PMC) encode the reward-based evidence favoring the best counterfactual option at future decisions. In addition to encoding counterfactual reward expectations, the network carries a signal for learning about counterfactual options when feedback is available-a counterfactual prediction error. Unlike other brain regions that have been associated with the processing of counterfactual outcomes, counterfactual prediction errors within the identified network cannot be related to regret theory. Furthermore, individual variation in counterfactual choice-related activity and prediction error-related activity, respectively, predicts variation in the propensity to switch to profitable choices in the future and the ability to learn from hypothetical feedback. Taken together, these data provide both neural and behavioral evidence to support the existence of a previously unidentified neural system responsible for tracking both counterfactual choice options and their outcomes.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Comment in
-
Learning: not just the facts, ma'am, but the counterfactuals as well.PLoS Biol. 2011 Jun;9(6):e1001092. doi: 10.1371/journal.pbio.1001092. Epub 2011 Jun 28. PLoS Biol. 2011. PMID: 21738445 Free PMC article. No abstract available.
References
-
- Rushworth M. F, Behrens T. E. Choice, uncertainty and value in prefrontal and cingulate cortex. Nat Neurosci. 2008;11:389–397. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
