

A rapid protein structure alignment algorithm based on a text modeling technique
- PMID: 21814392
- PMCID: PMC3143397
- DOI: 10.6026/97320630006344
A rapid protein structure alignment algorithm based on a text modeling technique
Abstract
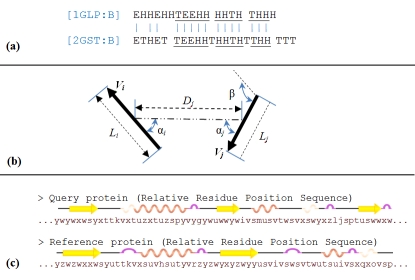
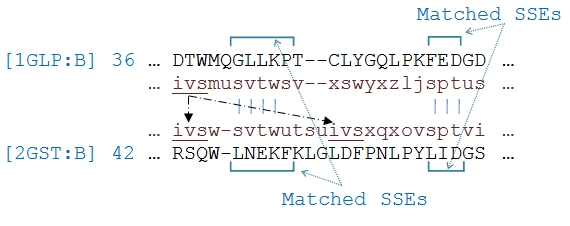
Structural alignment of proteins is widely used in various fields of structural biology. In order to further improve the quality of alignment, we describe an algorithm for structural alignment based on text modelling techniques. The technique firstly superimposes secondary structure elements of two proteins and then, models the 3D-structure of the protein in a sequence of alphabets. These sequences are utilized by a step-by-step sequence alignment procedure to align two protein structures. A benchmark test was organized on a set of 200 non-homologous proteins to evaluate the program and compare it to state of the art programs, e.g. CE, SAL, TM-align and 3D-BLAST. On average, the results of all-against-all structure comparison by the program have a competitive accuracy with CE and TM-align where the algorithm has a high running speed like 3D-BLAST.
Keywords: protein structure alignment; sequence alignment; text modeling.
Figures

References
LinkOut - more resources
Full Text Sources
Research Materials