

Credit assignment in multiple goal embodied visuomotor behavior
- PMID: 21833235
- PMCID: PMC3153784
- DOI: 10.3389/fpsyg.2010.00173
Credit assignment in multiple goal embodied visuomotor behavior
Abstract
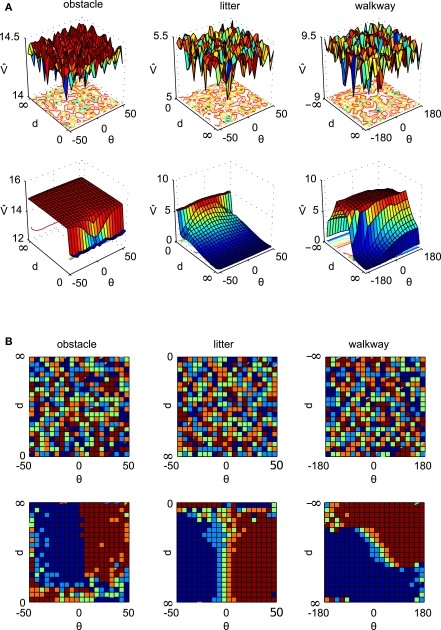
The intrinsic complexity of the brain can lead one to set aside issues related to its relationships with the body, but the field of embodied cognition emphasizes that understanding brain function at the system level requires one to address the role of the brain-body interface. It has only recently been appreciated that this interface performs huge amounts of computation that does not have to be repeated by the brain, and thus affords the brain great simplifications in its representations. In effect the brain's abstract states can refer to coded representations of the world created by the body. But even if the brain can communicate with the world through abstractions, the severe speed limitations in its neural circuitry mean that vast amounts of indexing must be performed during development so that appropriate behavioral responses can be rapidly accessed. One way this could happen would be if the brain used a decomposition whereby behavioral primitives could be quickly accessed and combined. This realization motivates our study of independent sensorimotor task solvers, which we call modules, in directing behavior. The issue we focus on herein is how an embodied agent can learn to calibrate such individual visuomotor modules while pursuing multiple goals. The biologically plausible standard for module programming is that of reinforcement given during exploration of the environment. However this formulation contains a substantial issue when sensorimotor modules are used in combination: The credit for their overall performance must be divided amongst them. We show that this problem can be solved and that diverse task combinations are beneficial in learning and not a complication, as usually assumed. Our simulations show that fast algorithms are available that allot credit correctly and are insensitive to measurement noise.
Keywords: credit assignment; learning; modules; reinforcement; reward.
Figures
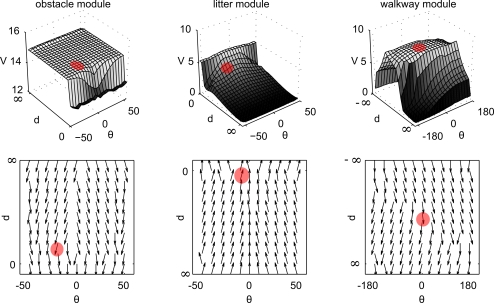
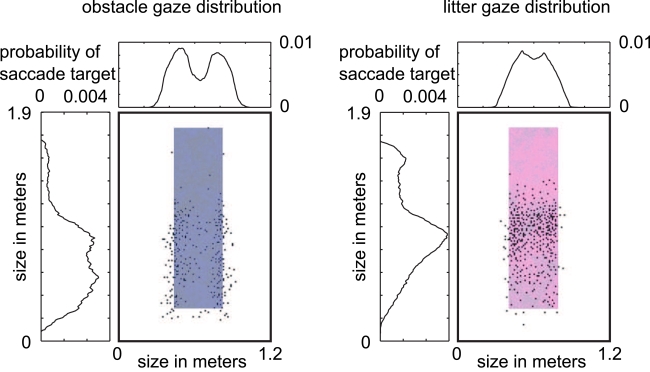
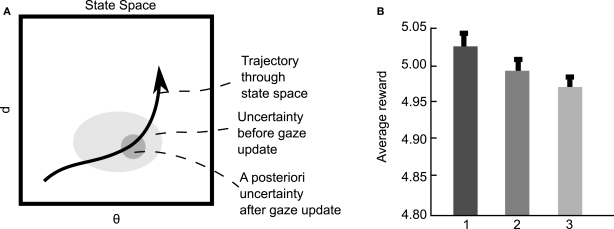
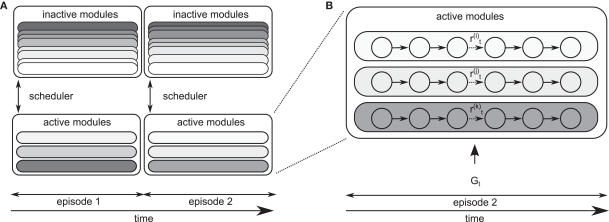
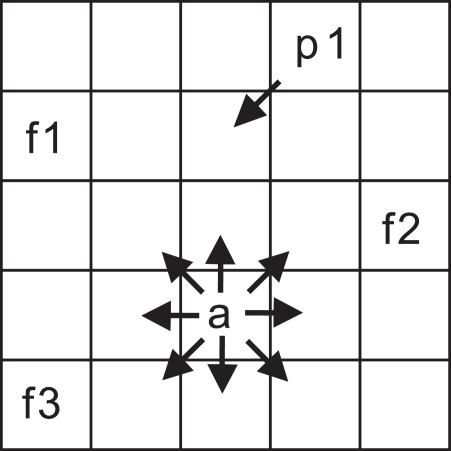
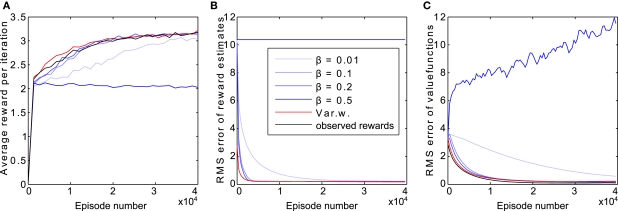
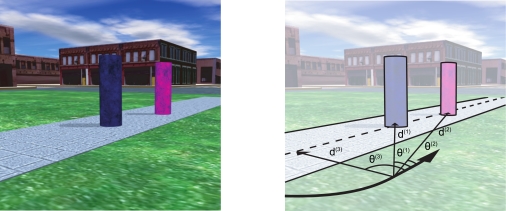
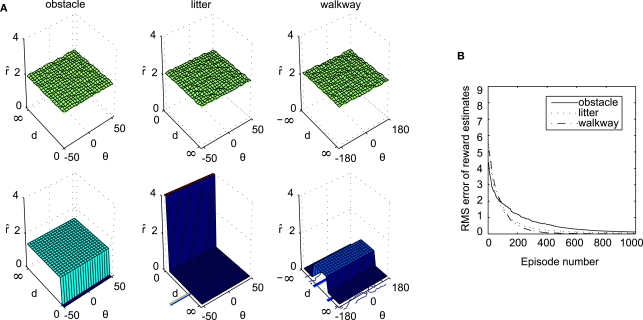
References
-
- Anderson J. (1983). The Architecture of Cognition. Cambridge, MA: Harvard University Press
-
- Arkin R. (1998). Behavior Based Robotics. Cambridge, MA: MIT Press
-
- Badler N. I., Phillips C. B., Webber B. L. (1993). Simulating Humans: Computer Graphics Animation and Control. New York, NY: Oxford University Press
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous