

Effect of priming on energetic and informational masking in a same-different task
- PMID: 21841488
- PMCID: PMC3227770
- DOI: 10.1097/AUD.0b013e31822b5bee
Effect of priming on energetic and informational masking in a same-different task
Abstract
Objectives: The primary goal of this study was to investigate how speech perception is altered by the provision of a preview or "prime" of a sample of speech just before it is presented in masking. A same-different test paradigm was developed which enabled the effect of priming to be measured with energetic maskers in addition to those that most likely produced both energetic and informational masking. Using this paradigm, the benefit of priming in overcoming energetic and informational masking was compared.
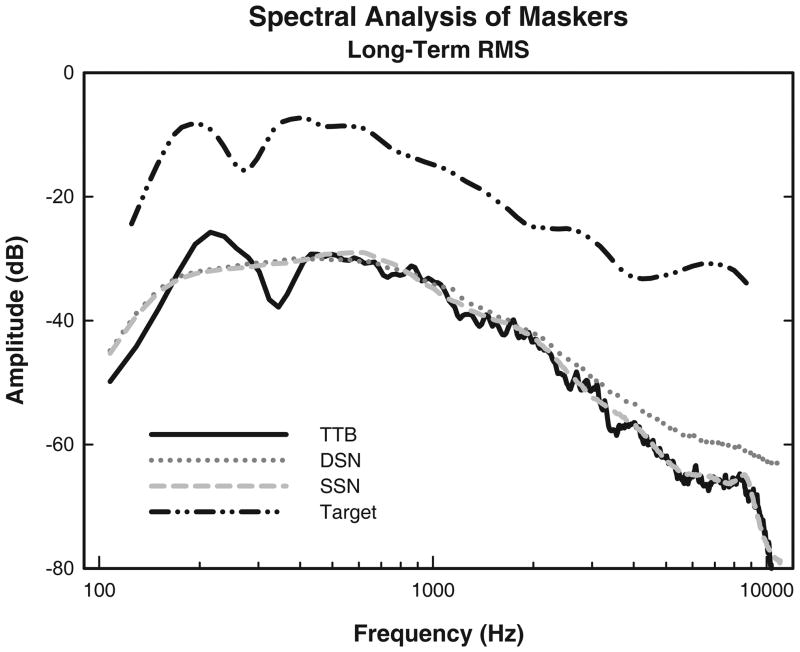
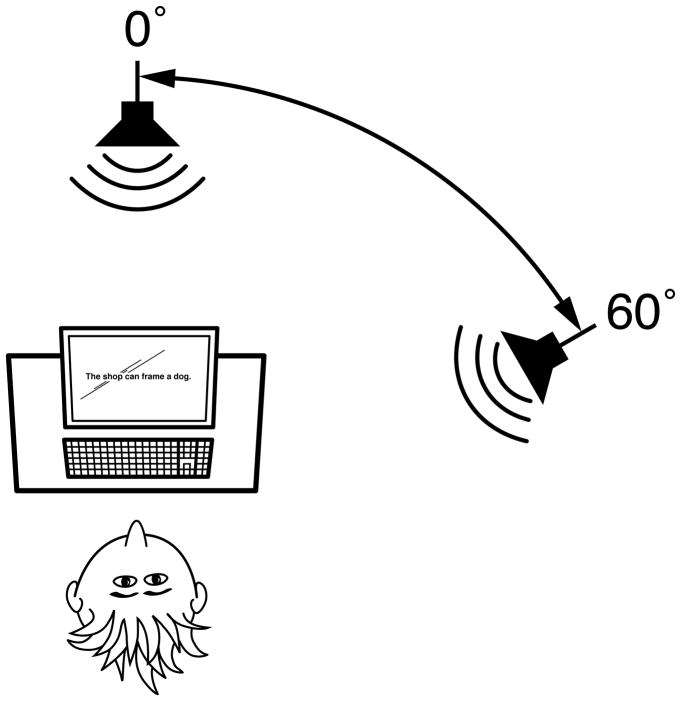
Design: Twenty-four normal-hearing subjects listened to nonsense sentences presented in a background of competing speech (two-talker babble) or one of two types of speech-shaped noise. Both target and masker were presented via loudspeaker directly in front of the listeners. In the baseline condition, the listeners were then shown a sentence on a computer screen that either matched the auditory target sentence exactly or contained a replacement for one of the three target key words. Their task was to judge whether the printed sentence matched the auditory target and respond via computer keyboard. In the first experimental condition, the printed sentence preceded rather than followed the auditory presentation (the priming condition). In the second experimental condition, the perception of spatial separation was created between target and masker by presenting the masker from two loudspeakers (front and 60° to the right) and imposing a 4-msec delay in the masker coming from the front loudspeaker. This resulted in the target being heard from the front while, because of the precedence effect, the masker was heard well to the right (the spatial condition). In a third experimental condition, spatial separation and priming were combined. A total of five signal-to-noise ratios were tested for each masker.
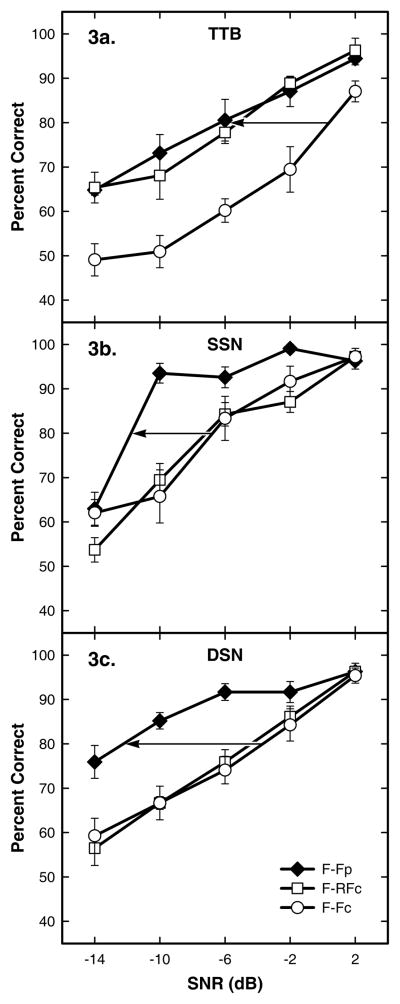
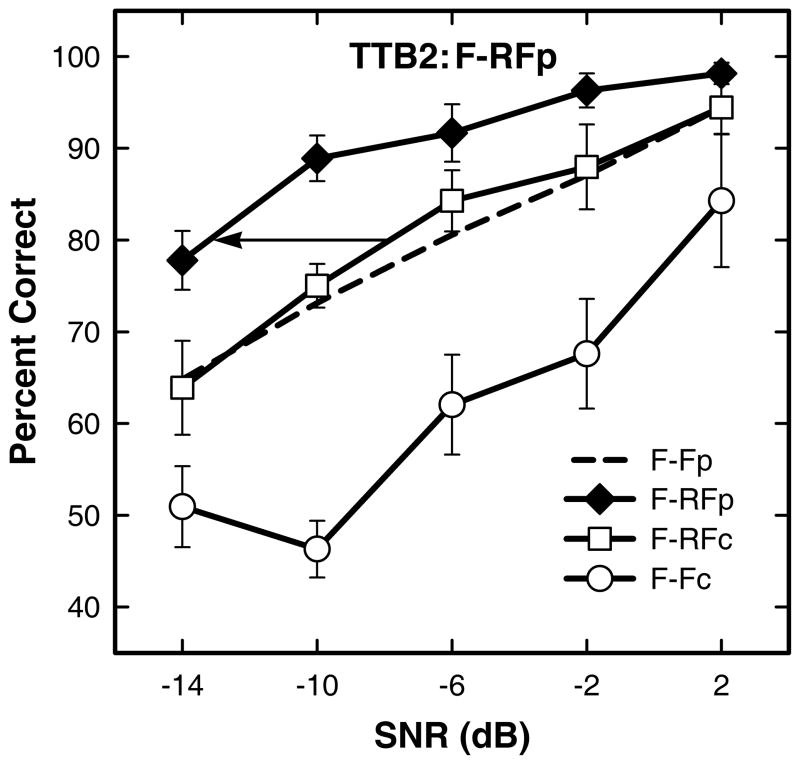
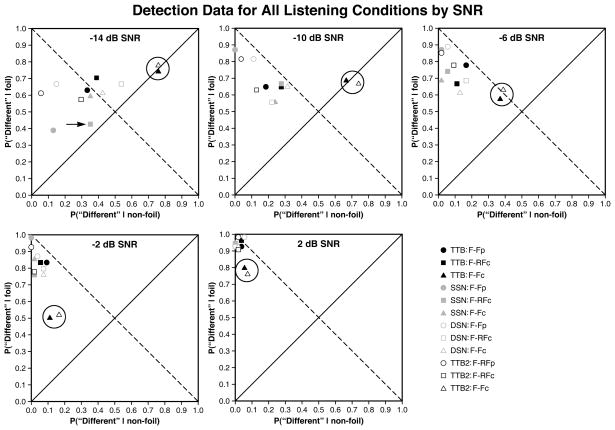
Results: The competing speech masker produced more masking than noise, consistent with previous findings. For the competing speech masker, the signal-to-noise ratio for 80% correct performance was approximately 6.7 dB lower when the listeners read the sentences first (the priming condition) than in the baseline condition. This priming effect was similar to the improvement obtained when the target and masker were separated spatially. Significant priming effects were also observed with speech-shaped noise maskers, and when there was perceived spatial separation between target and masker, conditions in which informational masking was believed to have been minimal. There seemed to be an additive effect of spatial separation and priming in the two-talker babble condition.
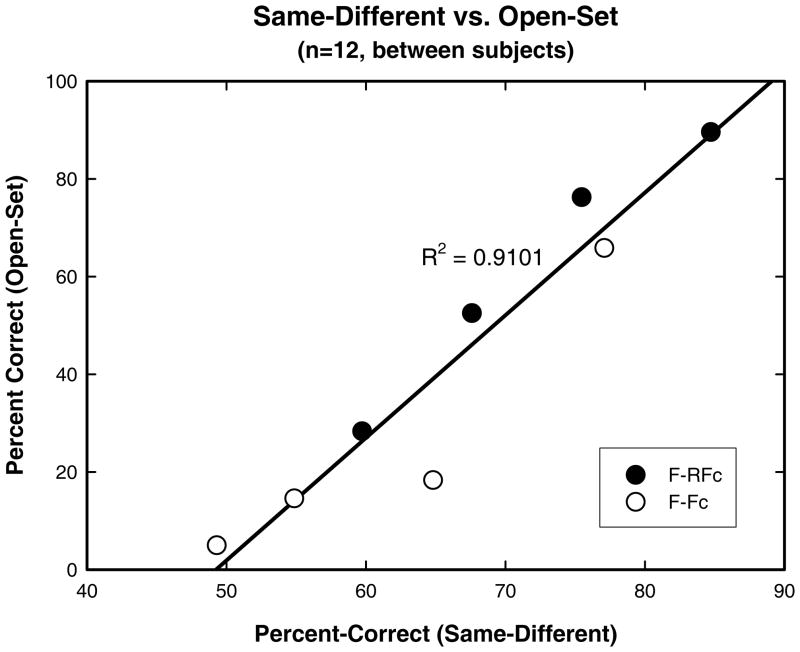
Conclusions: (1) Priming was effective in improving speech perception in all conditions, including those consisting of primarily energetic masking. (2) It is not clear how much benefit from priming could be attributed to release from informational masking. (3) Performance on the same-different task was linearly related to performance on an open-set speech recognition task using the same target and masker.
Figures
Similar articles
-
Effect of number of masking talkers and auditory priming on informational masking in speech recognition.J Acoust Soc Am. 2004 May;115(5 Pt 1):2246-56. doi: 10.1121/1.1689343. J Acoust Soc Am. 2004. PMID: 15139635
-
The effects of energetic and informational masking on The Words-in-Noise Test (WIN).J Am Acad Audiol. 2012 Jul-Aug;23(7):522-33. doi: 10.3766/jaaa.23.7.4. J Am Acad Audiol. 2012. PMID: 22992259
-
The effect of spatial separation on informational masking of speech in normal-hearing and hearing-impaired listeners.J Acoust Soc Am. 2005 Apr;117(4 Pt 1):2169-80. doi: 10.1121/1.1861598. J Acoust Soc Am. 2005. PMID: 15898658
-
Procedural Factors That Affect Psychophysical Measures of Spatial Selectivity in Cochlear Implant Users.Trends Hear. 2015 Sep 29;19:2331216515607067. doi: 10.1177/2331216515607067. Trends Hear. 2015. PMID: 26420785 Free PMC article. Review.
-
Forward masking as a method of measuring place specificity of neural excitation in cochlear implants: a review of methods and interpretation.J Acoust Soc Am. 2012 Mar;131(3):2209-24. doi: 10.1121/1.3683248. J Acoust Soc Am. 2012. PMID: 22423717 Review.
Cited by
-
Competing speech perception in older and younger adults: behavioral and eye-movement evidence.Ear Hear. 2014 Mar-Apr;35(2):161-70. doi: 10.1097/AUD.0b013e3182a830cf. Ear Hear. 2014. PMID: 24351611 Free PMC article.
-
In a Concurrent Memory and Auditory Perception Task, the Pupil Dilation Response Is More Sensitive to Memory Load Than to Auditory Stimulus Characteristics.Ear Hear. 2019 Mar/Apr;40(2):272-286. doi: 10.1097/AUD.0000000000000612. Ear Hear. 2019. PMID: 29923867 Free PMC article.
-
Priming of lowpass-filtered speech affects response bias, not sensitivity, in a bandwidth discrimination task.J Acoust Soc Am. 2013 Aug;134(2):1183-92. doi: 10.1121/1.4807824. J Acoust Soc Am. 2013. PMID: 23927117 Free PMC article.
-
How repetition influences speech understanding by younger, middle-aged and older adults.Int J Audiol. 2018 Sep;57(9):695-702. doi: 10.1080/14992027.2018.1475756. Epub 2018 May 25. Int J Audiol. 2018. PMID: 29801416 Free PMC article.
-
Temporal effects in priming of masked and degraded speech.J Acoust Soc Am. 2015 Sep;138(3):1418-27. doi: 10.1121/1.4927490. J Acoust Soc Am. 2015. PMID: 26428780 Free PMC article.
References
-
- Brungart DS, Simpson BD, Freyman RL. Precedence-based speech segregation in a virtual auditory environment. J Acoust Soc Am. 2005;118(5):3241–3251. - PubMed
-
- Church BA, Schacter DL. Perceptual specificity of auditory priming: Implicit memory for voice intonation and fundamental frequency. J Exp Psychol Learn Mem Cogn. 1994;20:521–533. - PubMed
-
- Deese J, Kaufman RA. Serial effects in recall of unorganized and sequentially organized verbal material. J Exp Psychol. 1957;54(3):180–187. - PubMed
-
- Dubno JR, Ahlstrom JB, Horwitz AR. Use of context by young and aged adults with normal hearing. J Acoust Soc Am. 2000;107(1):538–546. - PubMed
-
- Ezzatian P, Li L, Pichora-Fuller K, Schneider B. The effect of masker type and word-position on word recall and sentence understanding. J Acoust Soc Am. 2008;123(5):3721.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
