

The modENCODE Data Coordination Center: lessons in harvesting comprehensive experimental details
- PMID: 21856757
- PMCID: PMC3170170
- DOI: 10.1093/database/bar023
The modENCODE Data Coordination Center: lessons in harvesting comprehensive experimental details
Abstract
The model organism Encyclopedia of DNA Elements (modENCODE) project is a National Human Genome Research Institute (NHGRI) initiative designed to characterize the genomes of Drosophila melanogaster and Caenorhabditis elegans. A Data Coordination Center (DCC) was created to collect, store and catalog modENCODE data. An effective DCC must gather, organize and provide all primary, interpreted and analyzed data, and ensure the community is supplied with the knowledge of the experimental conditions, protocols and verification checks used to generate each primary data set. We present here the design principles of the modENCODE DCC, and describe the ramifications of collecting thorough and deep metadata for describing experiments, including the use of a wiki for capturing protocol and reagent information, and the BIR-TAB specification for linking biological samples to experimental results. modENCODE data can be found at http://www.modencode.org.
Figures

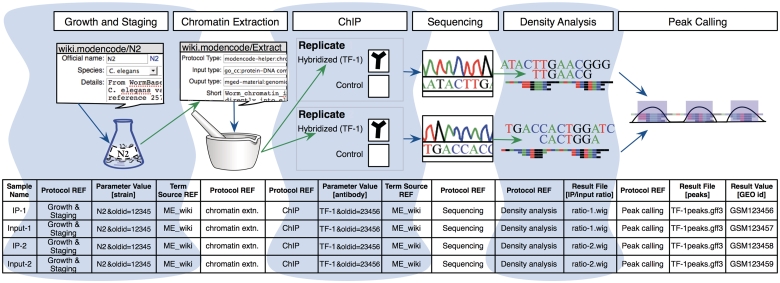
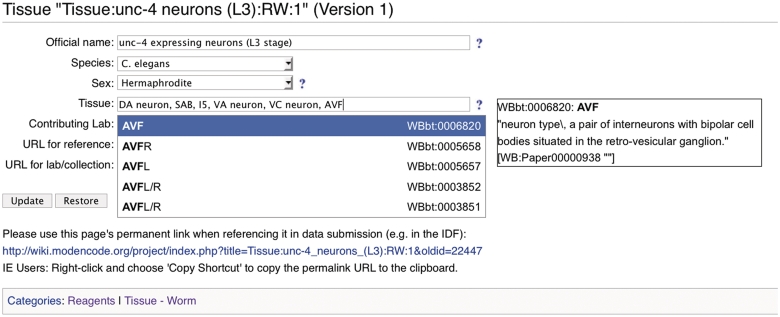
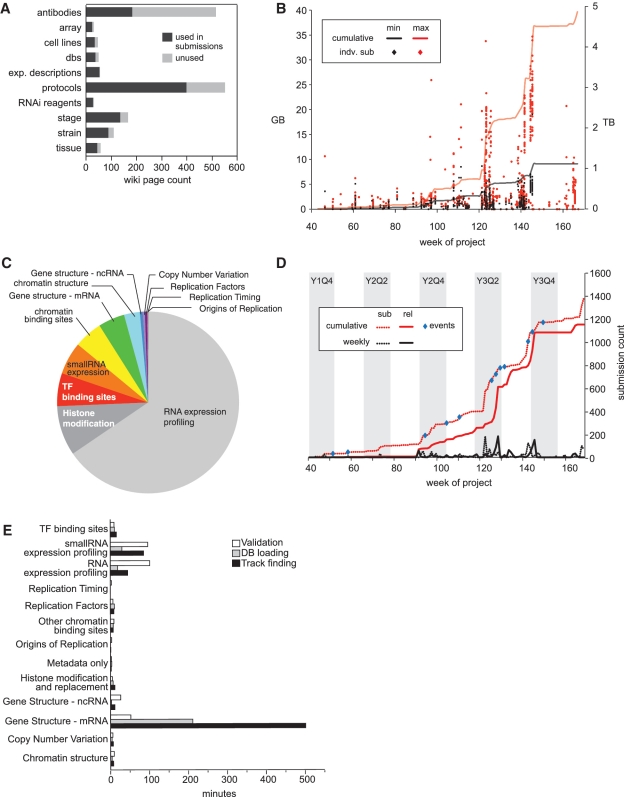

References
-
- International HapMap Consortium. The International HapMap Project. Nature. 2003;426:789–796. - PubMed
-
- C. elegans Sequencing Consortium. Genome sequence of the nematode C. elegans: a platform for investigating biology. Science. 1998;282:2012–2018. - PubMed
-
- Adams MD, Celniker SE, Holt RA, et al. The genome sequence of Drosophila melanogaster. Science. 2000;287:2185–2195. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
