

Value and prediction error in medial frontal cortex: integrating the single-unit and systems levels of analysis
- PMID: 21886616
- PMCID: PMC3155079
- DOI: 10.3389/fnhum.2011.00075
Value and prediction error in medial frontal cortex: integrating the single-unit and systems levels of analysis
Abstract
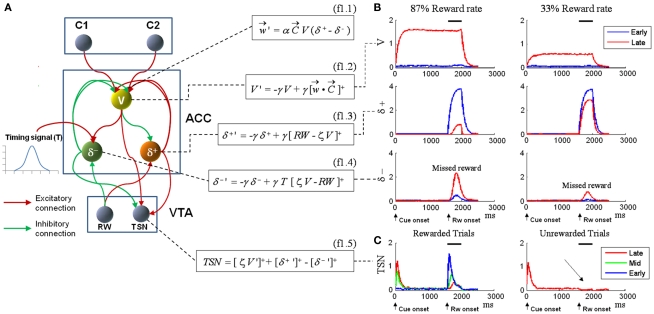
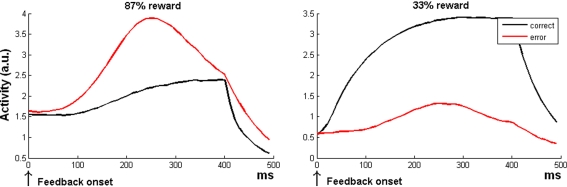
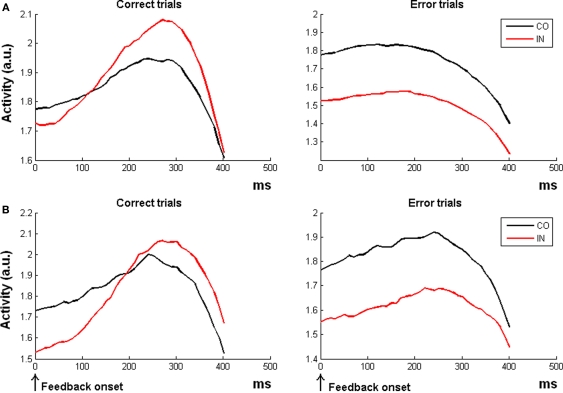
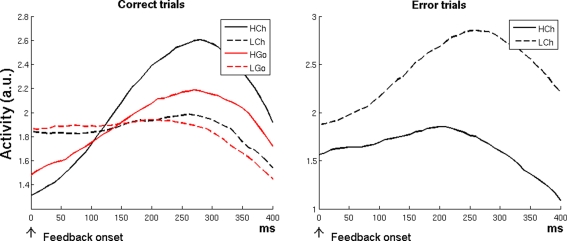
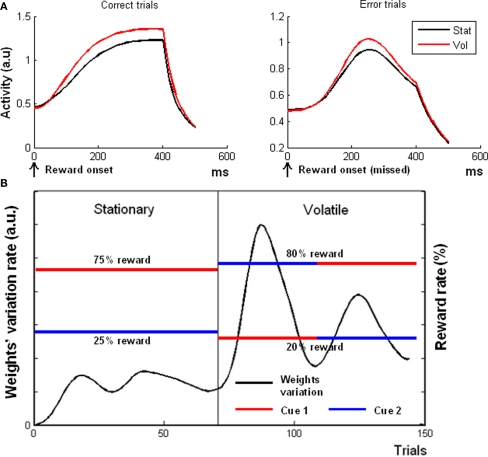
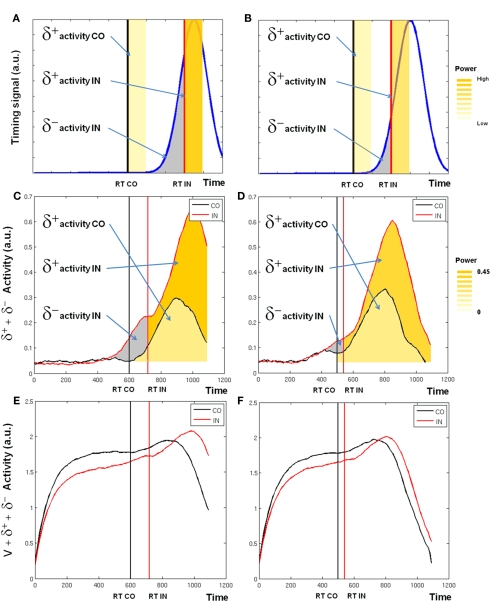
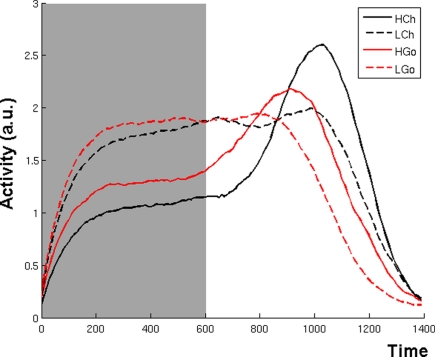
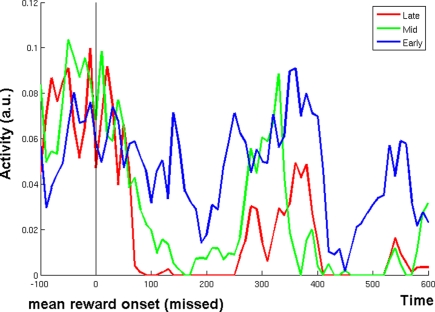
The role of the anterior cingulate cortex (ACC) in cognition has been extensively investigated with several techniques, including single-unit recordings in rodents and monkeys and EEG and fMRI in humans. This has generated a rich set of data and points of view. Important theoretical functions proposed for ACC are value estimation, error detection, error-likelihood estimation, conflict monitoring, and estimation of reward volatility. A unified view is lacking at this time, however. Here we propose that online value estimation could be the key function underlying these diverse data. This is instantiated in the reward value and prediction model (RVPM). The model contains units coding for the value of cues (stimuli or actions) and units coding for the differences between such values and the actual reward (prediction errors). We exposed the model to typical experimental paradigms from single-unit, EEG, and fMRI research to compare its overall behavior with the data from these studies. The model reproduced the ACC behavior of previous single-unit, EEG, and fMRI studies on reward processing, error processing, conflict monitoring, error-likelihood estimation, and volatility estimation, unifying the interpretations of the role performed by the ACC in some aspects of cognition.
Keywords: ACC; conflict monitoring; dopamine; error likelihood; reinforcement learning; reward; volatility.
Figures
Similar articles
-
Value and prediction error estimation account for volatility effects in ACC: a model-based fMRI study.Cortex. 2013 Jun;49(6):1627-35. doi: 10.1016/j.cortex.2012.05.008. Epub 2012 May 26. Cortex. 2013. PMID: 22717205
-
Deficient reinforcement learning in medial frontal cortex as a model of dopamine-related motivational deficits in ADHD.Neural Netw. 2013 Oct;46:199-209. doi: 10.1016/j.neunet.2013.05.008. Epub 2013 May 21. Neural Netw. 2013. PMID: 23811383
-
Conflict monitoring and error processing: new insights from simultaneous EEG-fMRI.Neuroimage. 2015 Jan 15;105:395-407. doi: 10.1016/j.neuroimage.2014.10.028. Epub 2014 Oct 22. Neuroimage. 2015. PMID: 25462691
-
The Role of the Anterior Cingulate Cortex in Prediction Error and Signaling Surprise.Top Cogn Sci. 2019 Jan;11(1):119-135. doi: 10.1111/tops.12307. Epub 2017 Nov 13. Top Cogn Sci. 2019. PMID: 29131512 Review.
-
From conflict management to reward-based decision making: actors and critics in primate medial frontal cortex.Neurosci Biobehav Rev. 2014 Oct;46 Pt 1:44-57. doi: 10.1016/j.neubiorev.2013.11.003. Epub 2013 Nov 15. Neurosci Biobehav Rev. 2014. PMID: 24239852 Review.
Cited by
-
Perceptual oddities: assessing the relationship between film editing and prediction processes.Philos Trans R Soc Lond B Biol Sci. 2024 Jan 29;379(1895):20220426. doi: 10.1098/rstb.2022.0426. Epub 2023 Dec 18. Philos Trans R Soc Lond B Biol Sci. 2024. PMID: 38104604 Free PMC article.
-
Updating expected action outcome in the medial frontal cortex involves an evaluation of error type.J Neurosci. 2013 Oct 2;33(40):15705-9. doi: 10.1523/JNEUROSCI.2785-13.2013. J Neurosci. 2013. PMID: 24089478 Free PMC article.
-
Computational Models of Anterior Cingulate Cortex: At the Crossroads between Prediction and Effort.Front Neurosci. 2017 Jun 6;11:316. doi: 10.3389/fnins.2017.00316. eCollection 2017. Front Neurosci. 2017. PMID: 28634438 Free PMC article.
-
Blinking predicts enhanced cognitive control.Cogn Affect Behav Neurosci. 2013 Jun;13(2):346-54. doi: 10.3758/s13415-012-0138-2. Cogn Affect Behav Neurosci. 2013. PMID: 23242699
-
The Role of Anterior Cingulate Cortex in the Affective Evaluation of Conflict.J Cogn Neurosci. 2017 Jan;29(1):137-149. doi: 10.1162/jocn_a_01023. Epub 2016 Aug 30. J Cogn Neurosci. 2017. PMID: 27575278 Free PMC article.
References
LinkOut - more resources
Full Text Sources