

Dopamine neurons learn to encode the long-term value of multiple future rewards
- PMID: 21896766
- PMCID: PMC3174584
- DOI: 10.1073/pnas.1014457108
Dopamine neurons learn to encode the long-term value of multiple future rewards
Abstract
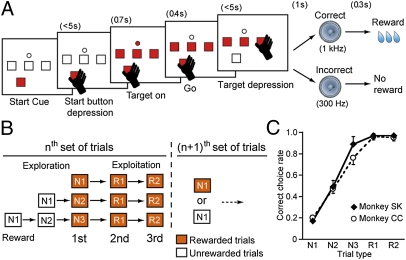
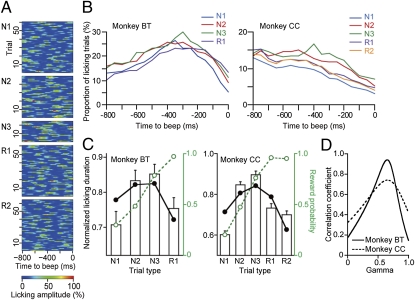
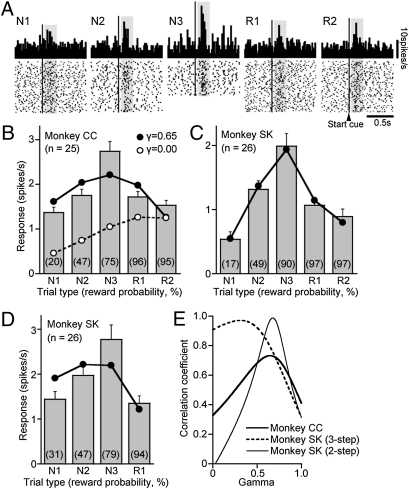
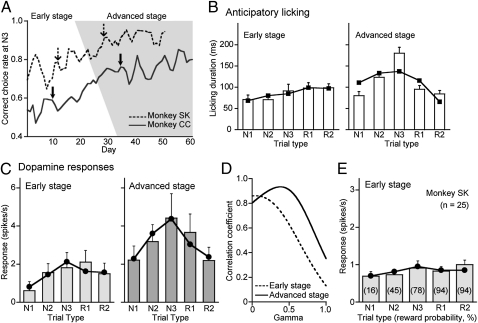
Midbrain dopamine neurons signal reward value, their prediction error, and the salience of events. If they play a critical role in achieving specific distant goals, long-term future rewards should also be encoded as suggested in reinforcement learning theories. Here, we address this experimentally untested issue. We recorded 185 dopamine neurons in three monkeys that performed a multistep choice task in which they explored a reward target among alternatives and then exploited that knowledge to receive one or two additional rewards by choosing the same target in a set of subsequent trials. An analysis of anticipatory licking for reward water indicated that the monkeys did not anticipate an immediately expected reward in individual trials; rather, they anticipated the sum of immediate and multiple future rewards. In accordance with this behavioral observation, the dopamine responses to the start cues and reinforcer beeps reflected the expected values of the multiple future rewards and their errors, respectively. More specifically, when monkeys learned the multistep choice task over the course of several weeks, the responses of dopamine neurons encoded the sum of the immediate and expected multiple future rewards. The dopamine responses were quantitatively predicted by theoretical descriptions of the value function with time discounting in reinforcement learning. These findings demonstrate that dopamine neurons learn to encode the long-term value of multiple future rewards with distant rewards discounted.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Sutton RS, Barto AG. Reinforcement Learning. Cambridge, MA: MIT Press; 1998.
-
- Fiorillo CD, Tobler PN, Schultz W. Discrete coding of reward probability and uncertainty by dopamine neurons. Science. 2003;299:1898–1902. - PubMed
-
- Morris G, Arkadir D, Nevet A, Vaadia E, Bergman H. Coincident but distinct messages of midbrain dopamine and striatal tonically active neurons. Neuron. 2004;43:133–143. - PubMed
-
- Morris G, Nevet A, Arkadir D, Vaadia E, Bergman H. Midbrain dopamine neurons encode decisions for future action. Nat Neurosci. 2006;9:1057–1063. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
