

Direct structural connections between voice- and face-recognition areas
- PMID: 21900569
- PMCID: PMC6623403
- DOI: 10.1523/JNEUROSCI.2091-11.2011
Direct structural connections between voice- and face-recognition areas
Abstract
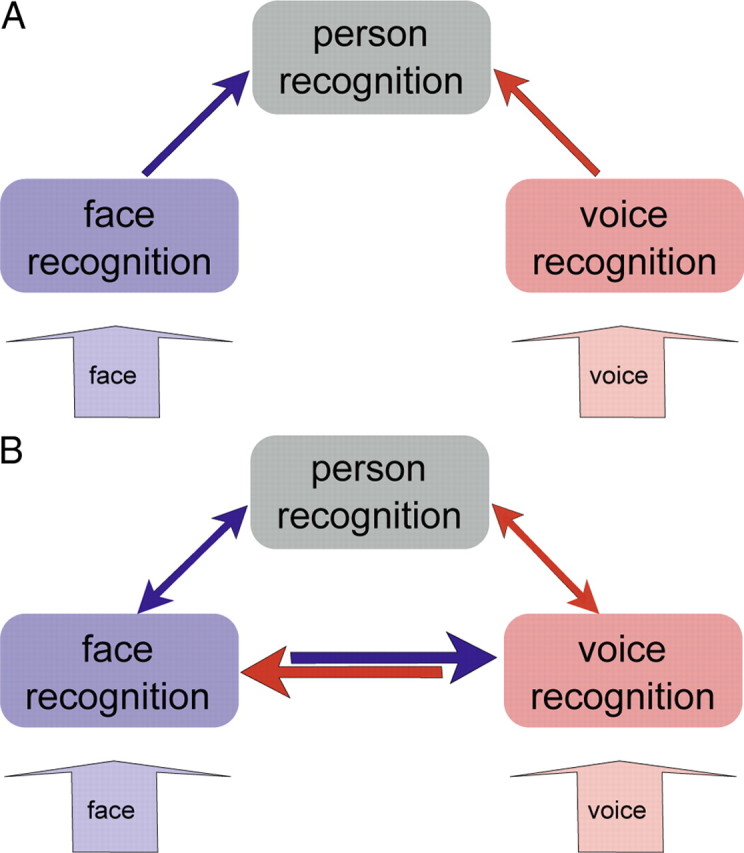
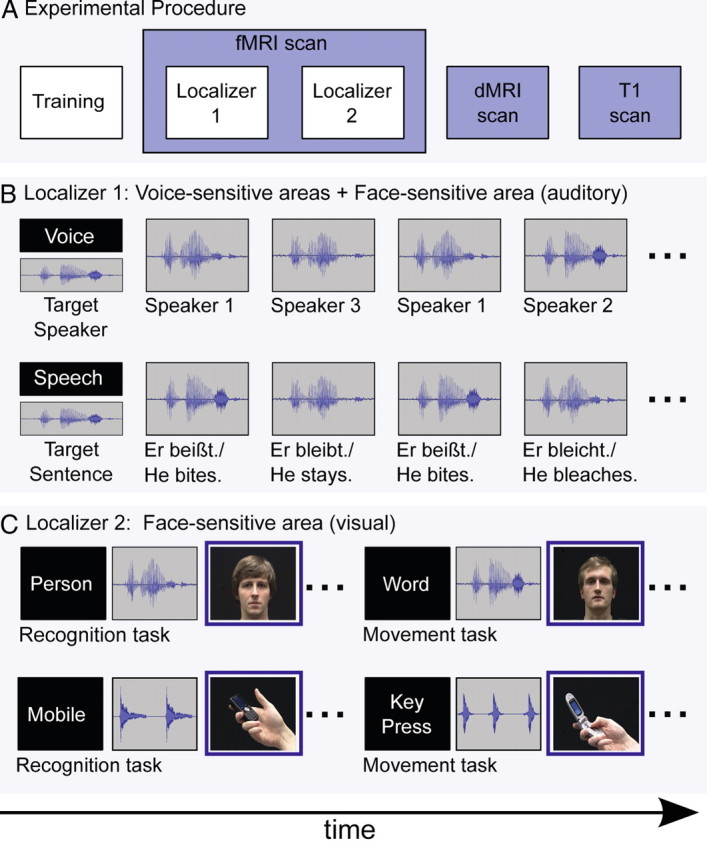
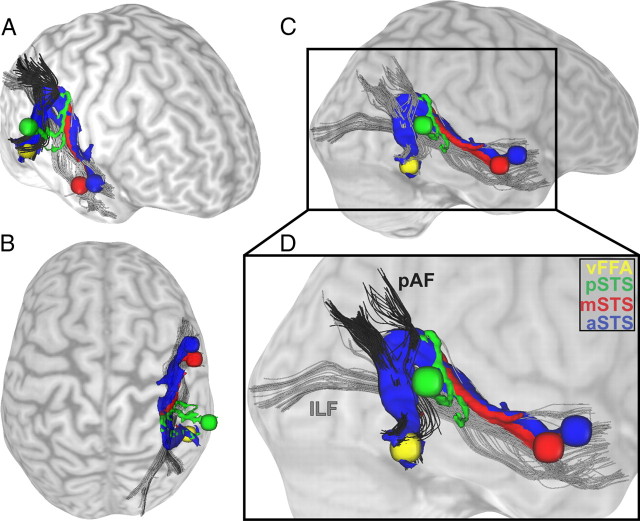
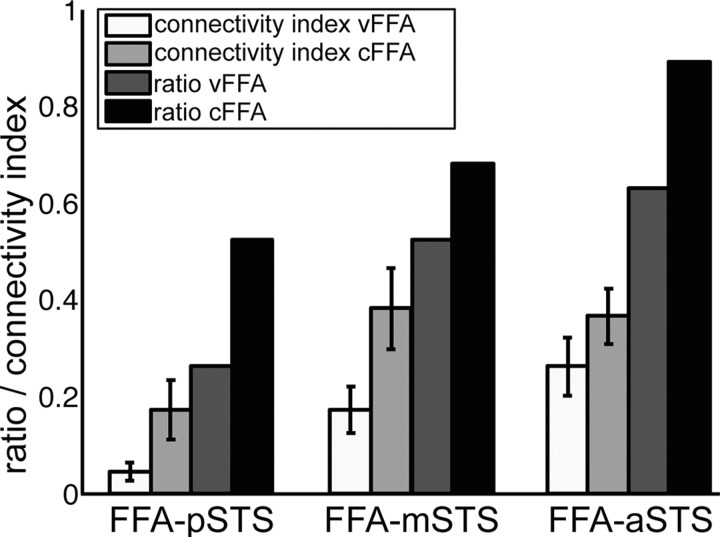
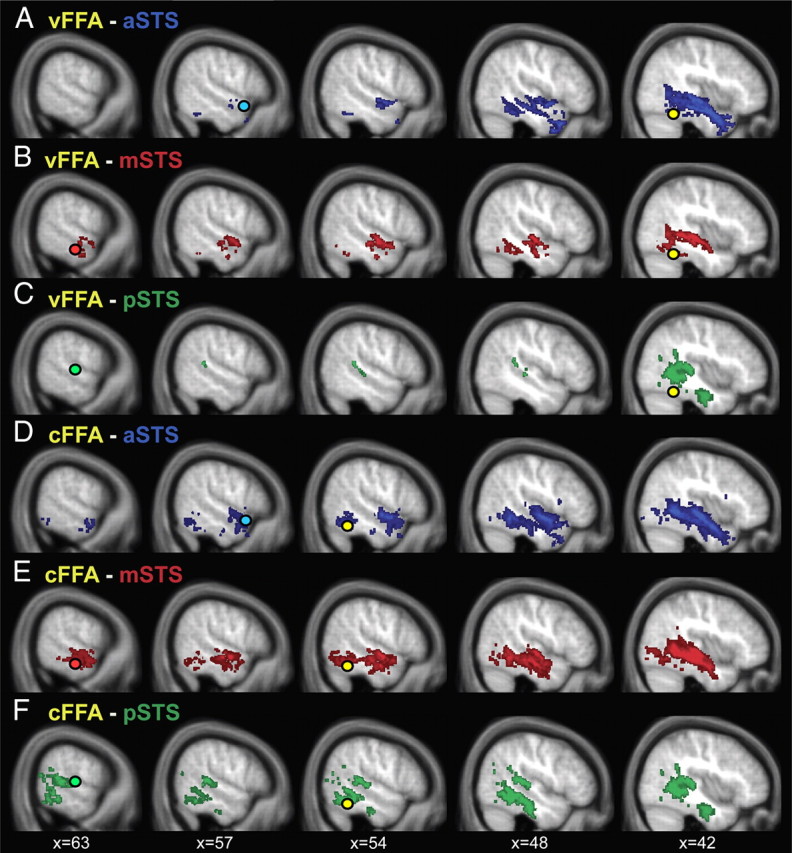
Currently, there are two opposing models for how voice and face information is integrated in the human brain to recognize person identity. The conventional model assumes that voice and face information is only combined at a supramodal stage (Bruce and Young, 1986; Burton et al., 1990; Ellis et al., 1997). An alternative model posits that areas encoding voice and face information also interact directly and that this direct interaction is behaviorally relevant for optimizing person recognition (von Kriegstein et al., 2005; von Kriegstein and Giraud, 2006). To disambiguate between the two different models, we tested for evidence of direct structural connections between voice- and face-processing cortical areas by combining functional and diffusion magnetic resonance imaging. We localized, at the individual subject level, three voice-sensitive areas in anterior, middle, and posterior superior temporal sulcus (STS) and face-sensitive areas in the fusiform gyrus [fusiform face area (FFA)]. Using probabilistic tractography, we show evidence that the FFA is structurally connected with voice-sensitive areas in STS. In particular, our results suggest that the FFA is more strongly connected to middle and anterior than to posterior areas of the voice-sensitive STS. This specific structural connectivity pattern indicates that direct links between face- and voice-recognition areas could be used to optimize human person recognition.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Andics A, McQueen JM, Petersson KM, Gál V, Rudas G, Vidnyánszky Z. Neural mechanisms for voice recognition. Neuroimage. 2010;52:1528–1540. - PubMed
-
- Anwander A, Tittgemeyer M, von Cramon DY, Friederici AD, Knösche TR. Connectivity-based parcellation of Broca's area. Cereb Cortex. 2007;17:816–825. - PubMed
-
- Basser PJ, Pierpaoli C. Microstructural and physiological features of tissues elucidated by quantitative-diffusion-tensor MRI. J Magn Reson B. 1996;111:209–219. - PubMed
-
- Basser PJ, Mattiello J, LeBihan D. Estimation of the effective self-diffusion tensor from the NMR spin-echo. J Magn Reson B. 1994;103:247–254. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources