

Visual feature-tolerance in the reading network
- PMID: 21903085
- PMCID: PMC3180962
- DOI: 10.1016/j.neuron.2011.06.036
Visual feature-tolerance in the reading network
Abstract
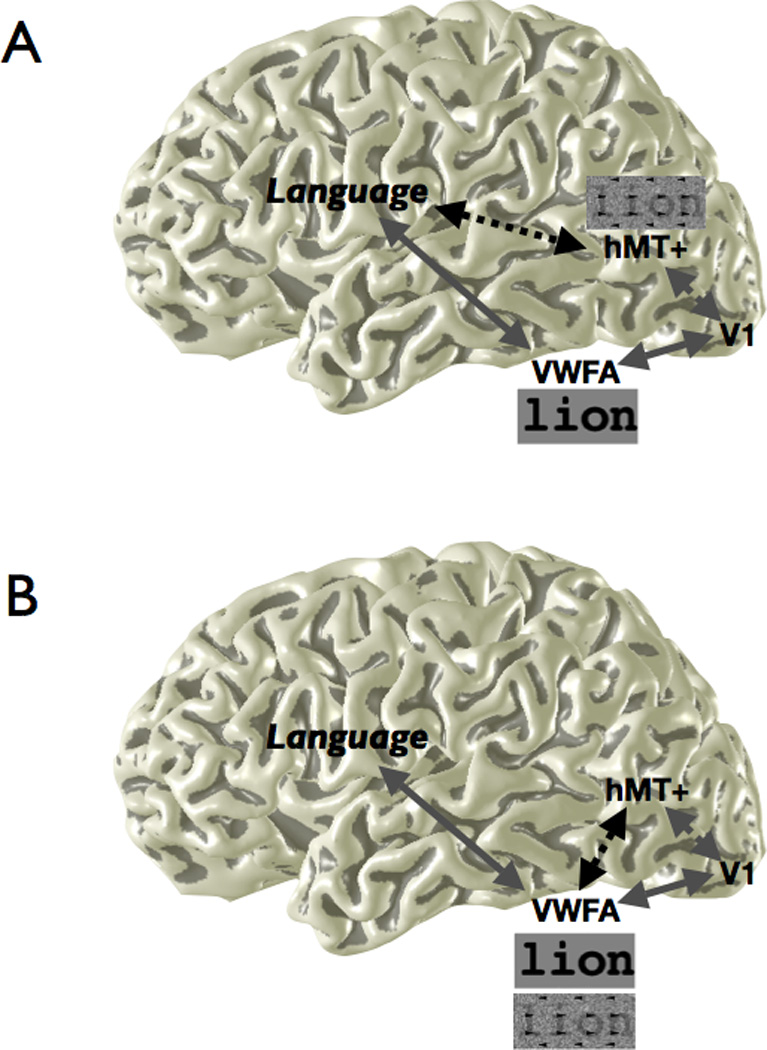
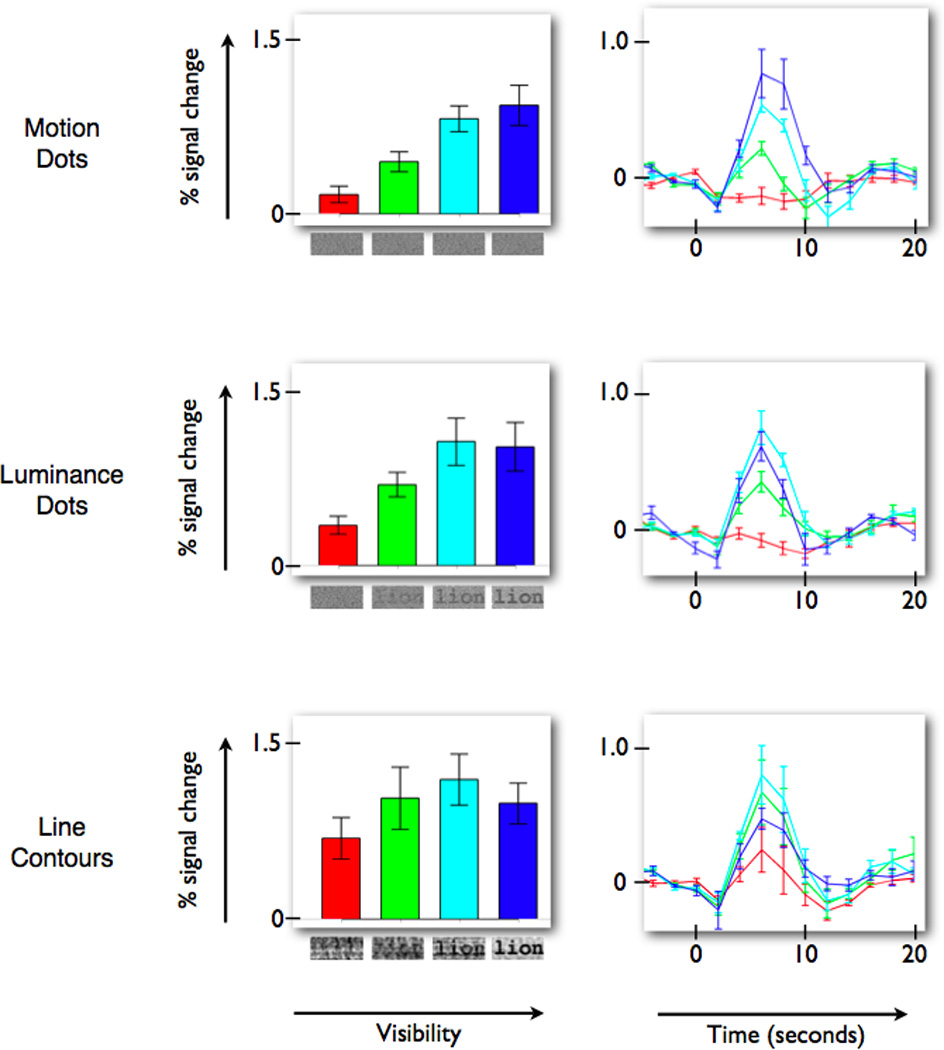
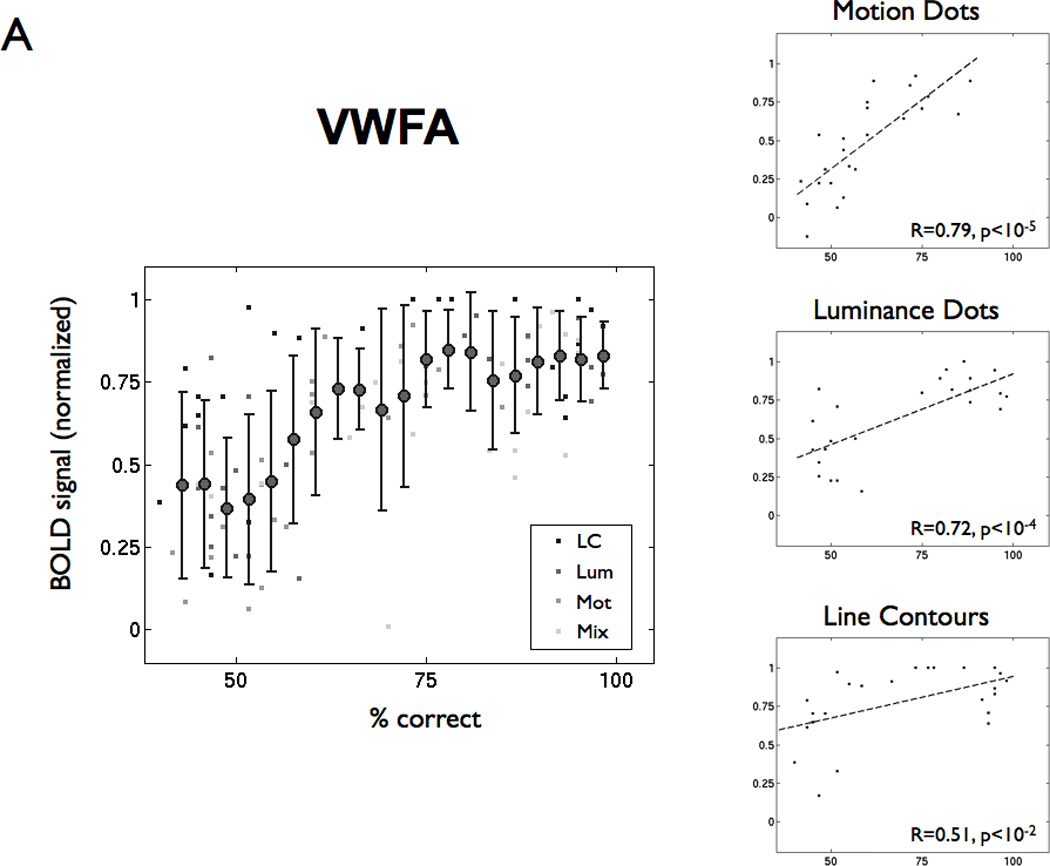
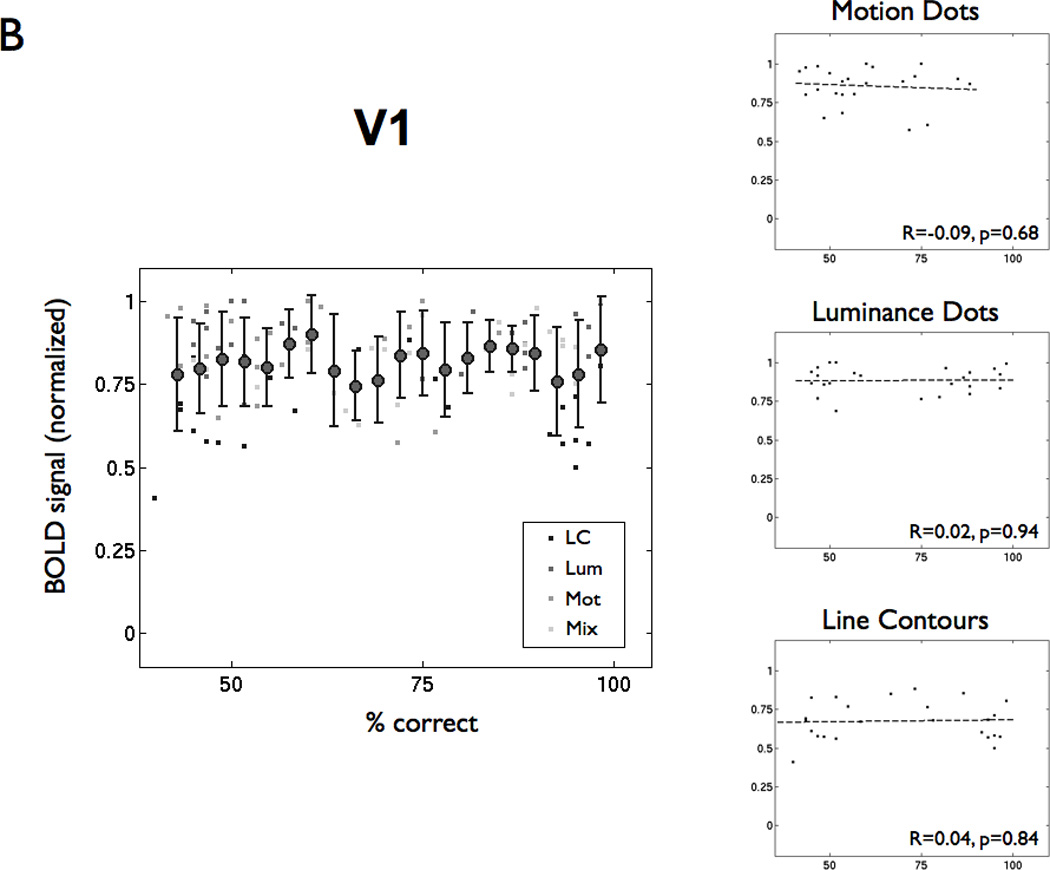
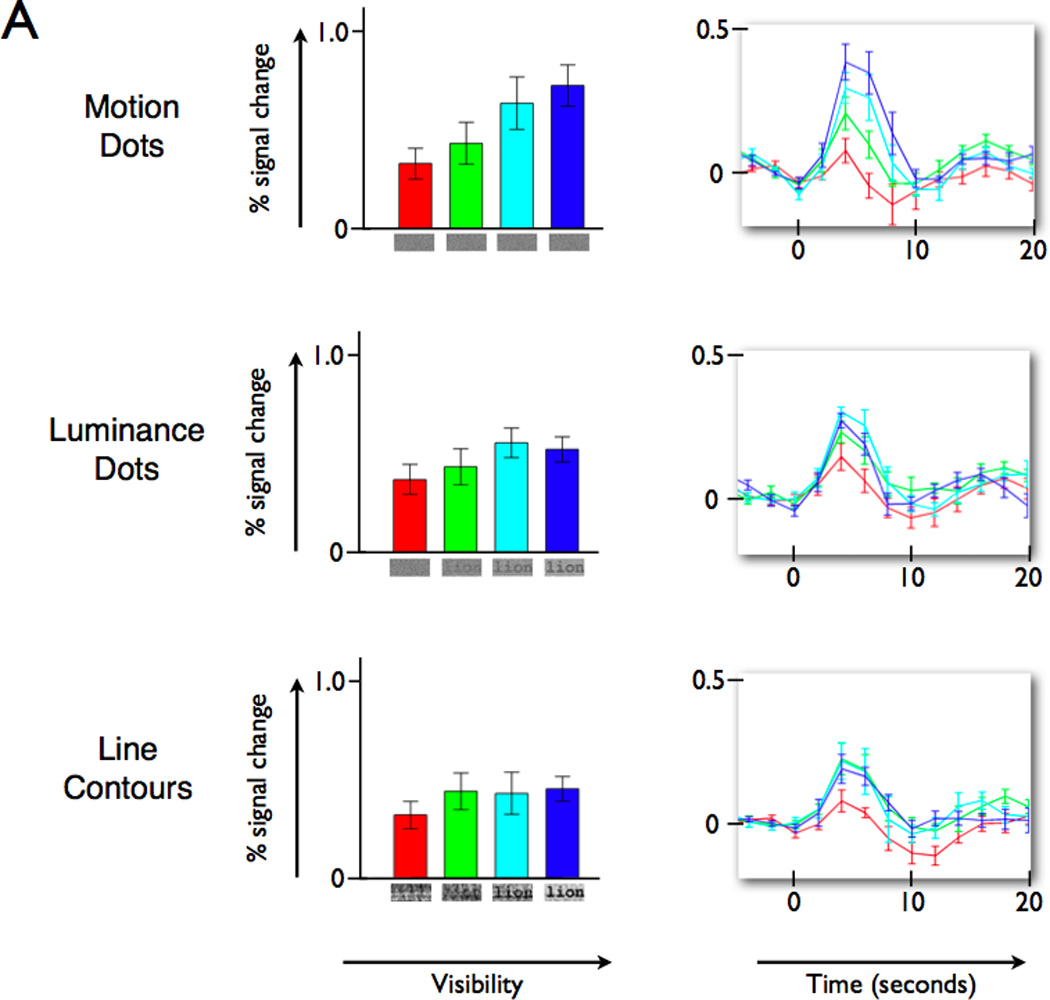
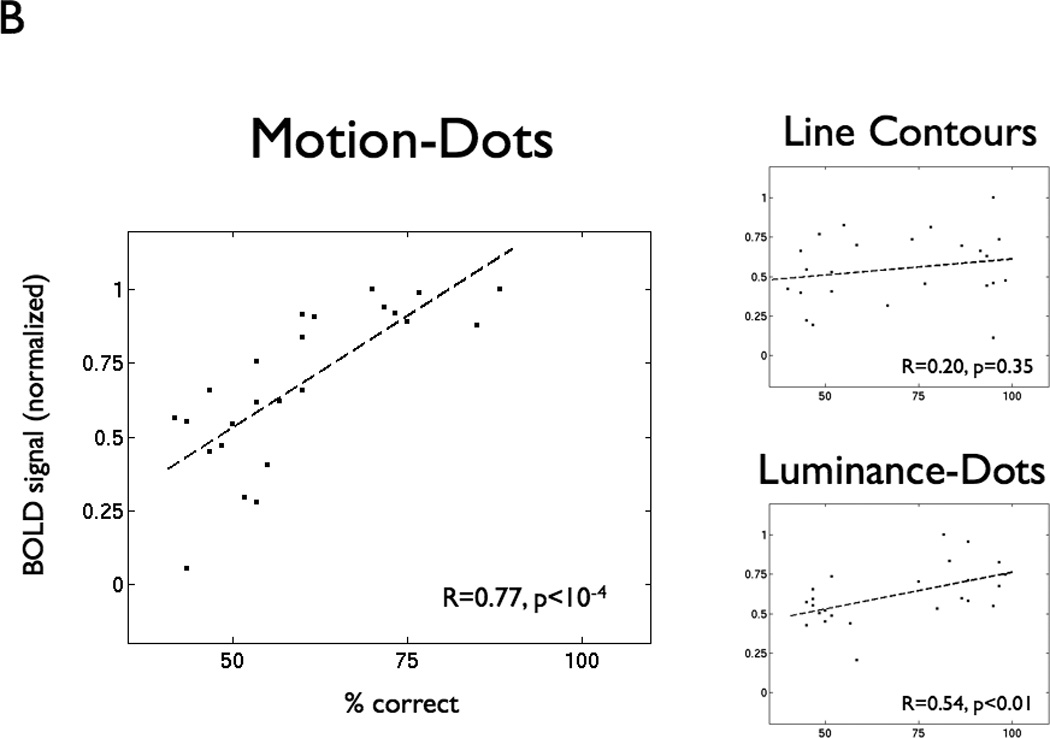
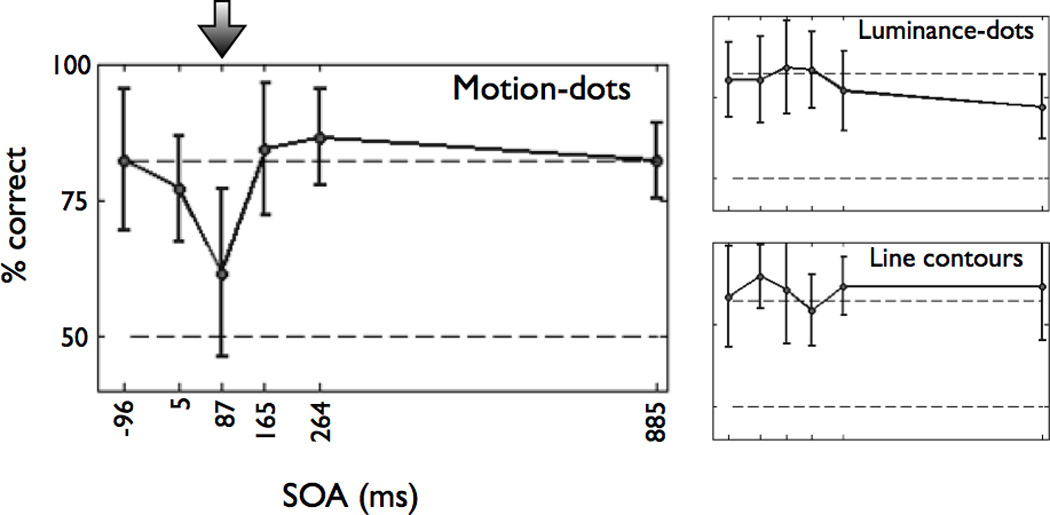
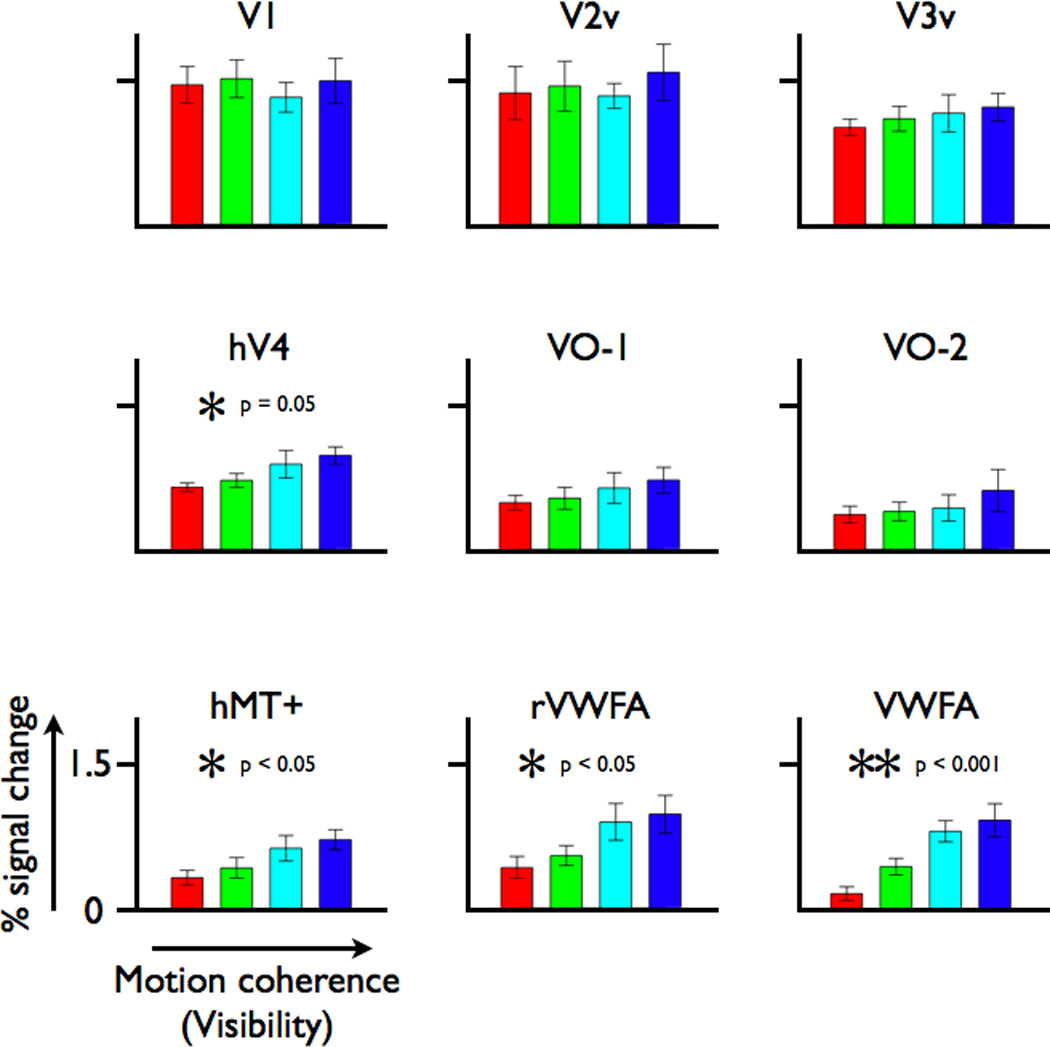
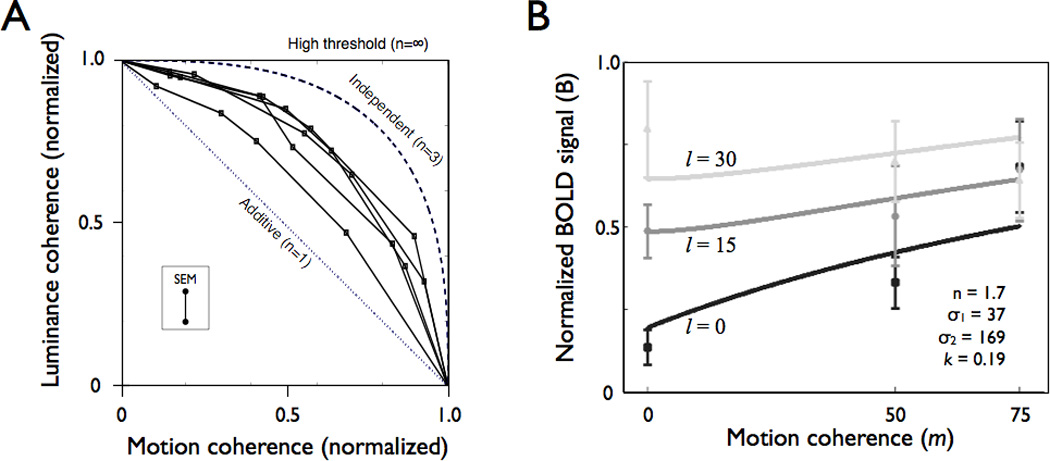
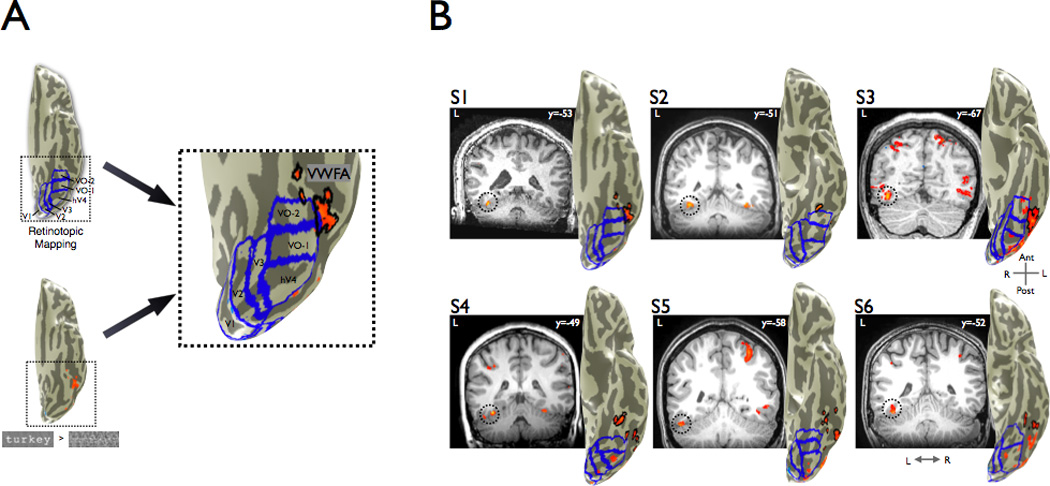
A century of neurology and neuroscience shows that seeing words depends on ventral occipital-temporal (VOT) circuitry. Typically, reading is learned using high-contrast line-contour words. We explored whether a specific VOT region, the visual word form area (VWFA), learns to see only these words or recognizes words independent of the specific shape-defining visual features. Word forms were created using atypical features (motion-dots, luminance-dots) whose statistical properties control word-visibility. We measured fMRI responses as word form visibility varied, and we used TMS to interfere with neural processing in specific cortical circuits, while subjects performed a lexical decision task. For all features, VWFA responses increased with word-visibility and correlated with performance. TMS applied to motion-specialized area hMT+ disrupted reading performance for motion-dots, but not line-contours or luminance-dots. A quantitative model describes feature-convergence in the VWFA and relates VWFA responses to behavioral performance. These findings suggest how visual feature-tolerance in the reading network arises through signal convergence from feature-specialized cortical areas.
Copyright © 2011 Elsevier Inc. All rights reserved.
Figures
Similar articles
-
Reading in the dark: neural correlates and cross-modal plasticity for learning to read entire words without visual experience.Neuropsychologia. 2016 Mar;83:149-160. doi: 10.1016/j.neuropsychologia.2015.11.009. Epub 2015 Nov 11. Neuropsychologia. 2016. PMID: 26577136
-
Structural connectivity patterns associated with the putative visual word form area and children's reading ability.Brain Res. 2014 Oct 24;1586:118-29. doi: 10.1016/j.brainres.2014.08.050. Epub 2014 Aug 22. Brain Res. 2014. PMID: 25152466 Free PMC article.
-
Word and non-word reading: what role for the Visual Word Form Area?Neuroimage. 2005 Sep;27(3):694-705. doi: 10.1016/j.neuroimage.2005.04.038. Neuroimage. 2005. PMID: 15961322 Clinical Trial.
-
The neurobiological basis of seeing words.Ann N Y Acad Sci. 2011 Apr;1224(1):63-80. doi: 10.1111/j.1749-6632.2010.05954.x. Ann N Y Acad Sci. 2011. PMID: 21486296 Free PMC article. Review.
-
Human cortical areas underlying the perception of optic flow: brain imaging studies.Int Rev Neurobiol. 2000;44:269-92. doi: 10.1016/s0074-7742(08)60746-1. Int Rev Neurobiol. 2000. PMID: 10605650 Review.
Cited by
-
Anatomy of the visual word form area: adjacent cortical circuits and long-range white matter connections.Brain Lang. 2013 May;125(2):146-55. doi: 10.1016/j.bandl.2012.04.010. Epub 2012 May 23. Brain Lang. 2013. PMID: 22632810 Free PMC article.
-
Selective visual representation of letters and words in the left ventral occipito-temporal cortex with intracerebral recordings.Proc Natl Acad Sci U S A. 2018 Aug 7;115(32):E7595-E7604. doi: 10.1073/pnas.1718987115. Epub 2018 Jul 23. Proc Natl Acad Sci U S A. 2018. PMID: 30038000 Free PMC article.
-
Brain network adaptability across task states.PLoS Comput Biol. 2015 Jan 8;11(1):e1004029. doi: 10.1371/journal.pcbi.1004029. eCollection 2015 Jan. PLoS Comput Biol. 2015. PMID: 25569227 Free PMC article.
-
The roles of occipitotemporal cortex in reading, spelling, and naming.Cogn Neuropsychol. 2014;31(5-6):511-28. doi: 10.1080/02643294.2014.884060. Epub 2014 Feb 17. Cogn Neuropsychol. 2014. PMID: 24527769 Free PMC article.
-
The vertical occipital fasciculus: a century of controversy resolved by in vivo measurements.Proc Natl Acad Sci U S A. 2014 Dec 2;111(48):E5214-23. doi: 10.1073/pnas.1418503111. Epub 2014 Nov 17. Proc Natl Acad Sci U S A. 2014. PMID: 25404310 Free PMC article.
References
-
- Ben-Shachar M, Dougherty RF, Deutsch GK, Wandell BA. Differential sensitivity to words and shapes in ventral occipito-temporal cortex. Cereb Cortex. 2007b;17:1604–1611. - PubMed
-
- Ben-Shachar M, Dougherty RF, Wandell BA. White matter pathways in reading. Curr Opin Neurobiol. 2007c;17:258–270. - PubMed
-
- Blanke O, Brooks A, Mercier M, Spinelli L, Adriani M, Lavanchy L, Safran AB, Landis T. Distinct mechanisms of form-from-motion perception in human extrastriate cortex. Neuropsychologia. 2007;45:644–653. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
