

The curation paradigm and application tool used for manual curation of the scientific literature at the Comparative Toxicogenomics Database
- PMID: 21933848
- PMCID: PMC3176677
- DOI: 10.1093/database/bar034
The curation paradigm and application tool used for manual curation of the scientific literature at the Comparative Toxicogenomics Database
Erratum in
- Database (Oxford). 2012;2012:bas012. Rosenstein, Michael C [added]
Abstract
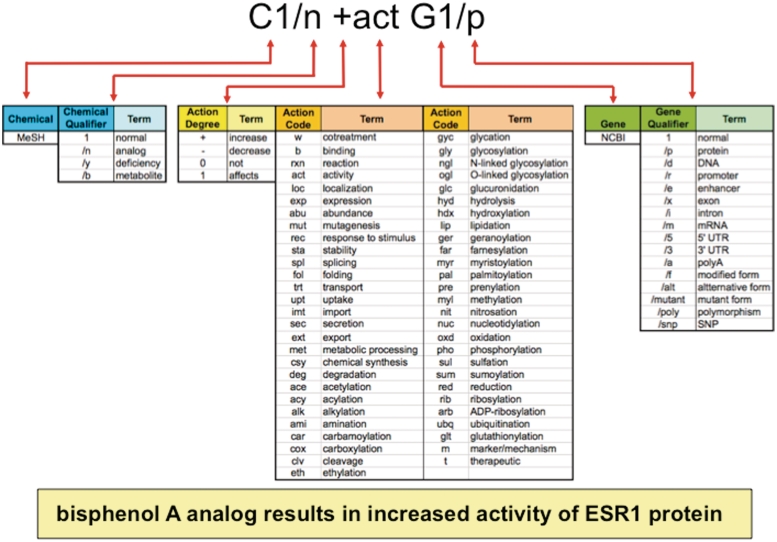
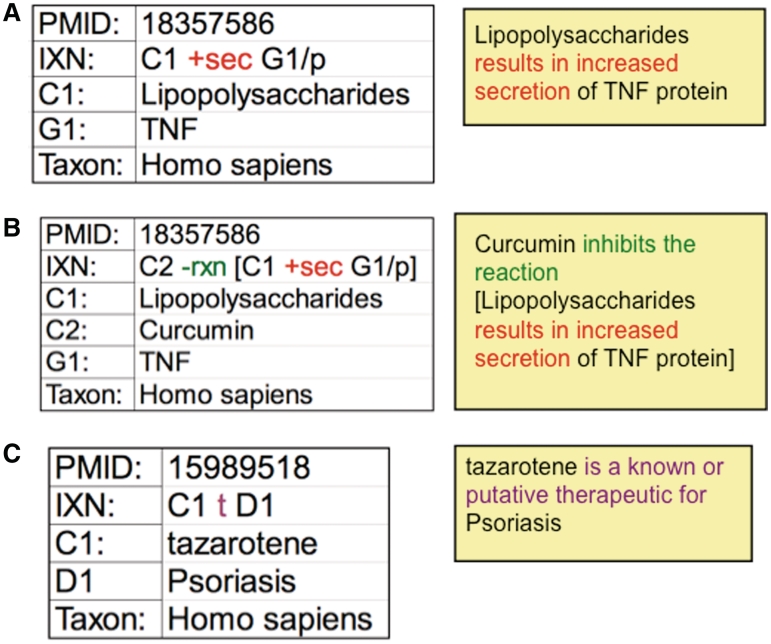
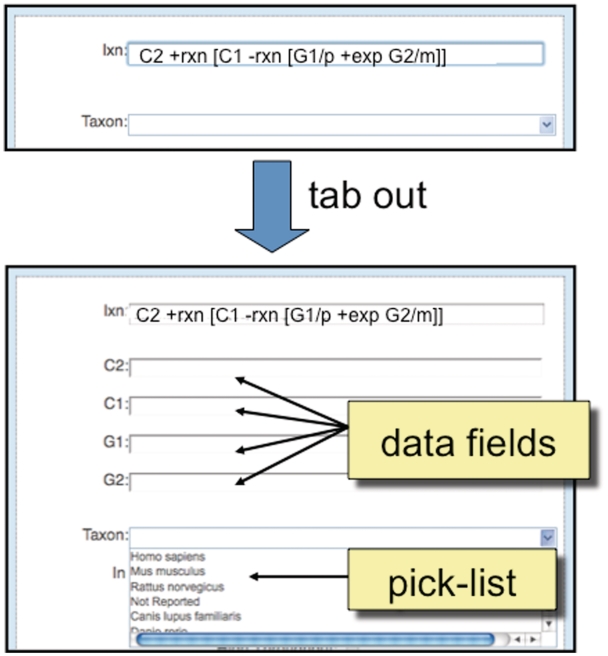
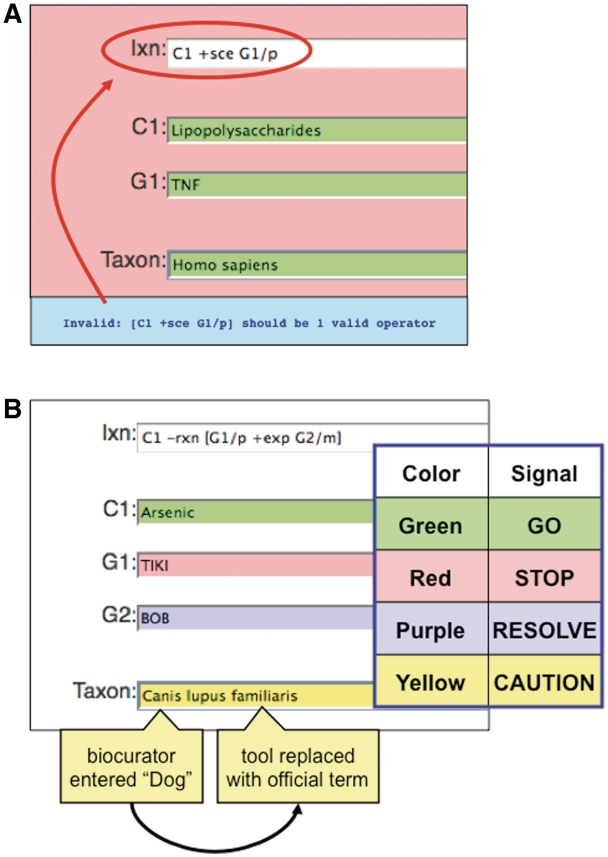
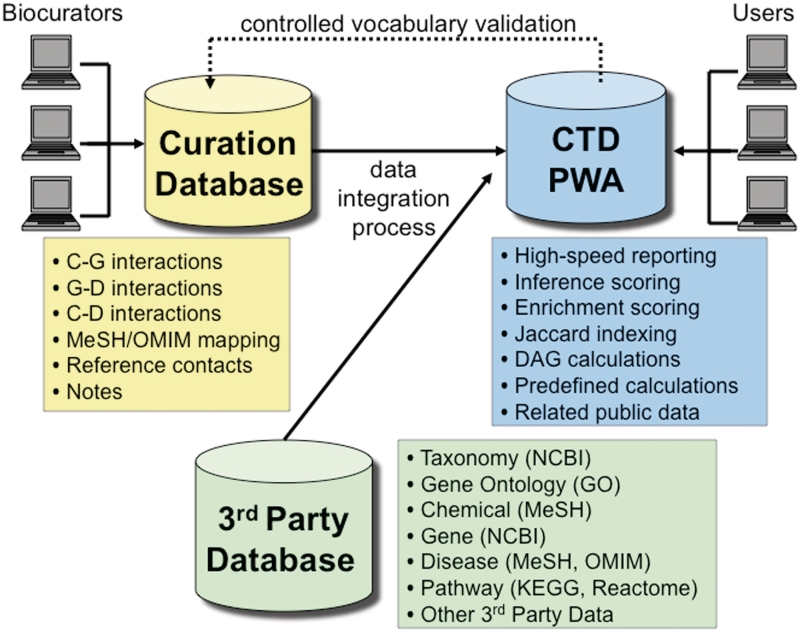
The Comparative Toxicogenomics Database (CTD) is a public resource that promotes understanding about the effects of environmental chemicals on human health. CTD biocurators read the scientific literature and convert free-text information into a structured format using official nomenclature, integrating third party controlled vocabularies for chemicals, genes, diseases and organisms, and a novel controlled vocabulary for molecular interactions. Manual curation produces a robust, richly annotated dataset of highly accurate and detailed information. Currently, CTD describes over 349,000 molecular interactions between 6800 chemicals, 20,900 genes (for 330 organisms) and 4300 diseases that have been manually curated from over 25,400 peer-reviewed articles. This manually curated data are further integrated with other third party data (e.g. Gene Ontology, KEGG and Reactome annotations) to generate a wealth of toxicogenomic relationships. Here, we describe our approach to manual curation that uses a powerful and efficient paradigm involving mnemonic codes. This strategy allows biocurators to quickly capture detailed information from articles by generating simple statements using codes to represent the relationships between data types. The paradigm is versatile, expandable, and able to accommodate new data challenges that arise. We have incorporated this strategy into a web-based curation tool to further increase efficiency and productivity, implement quality control in real-time and accommodate biocurators working remotely. Database URL: http://ctd.mdibl.org.
Figures


References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
