

Challenges in the association of human single nucleotide polymorphism mentions with unique database identifiers
- PMID: 21992066
- PMCID: PMC3194196
- DOI: 10.1186/1471-2105-12-S4-S4
Challenges in the association of human single nucleotide polymorphism mentions with unique database identifiers
Abstract
Background: Most information on genomic variations and their associations with phenotypes are covered exclusively in scientific publications rather than in structured databases. These texts commonly describe variations using natural language; database identifiers are seldom mentioned. This complicates the retrieval of variations, associated articles, as well as information extraction, e. g. the search for biological implications. To overcome these challenges, procedures to map textual mentions of variations to database identifiers need to be developed.
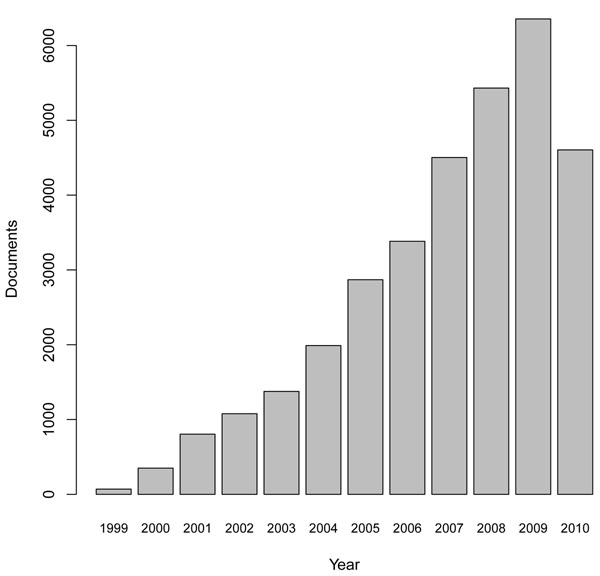
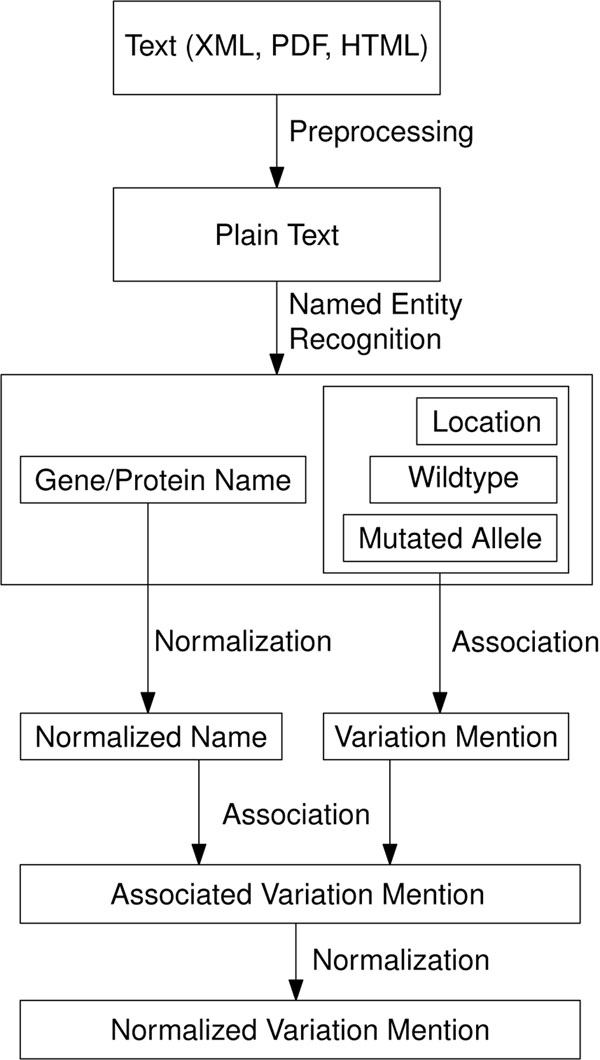
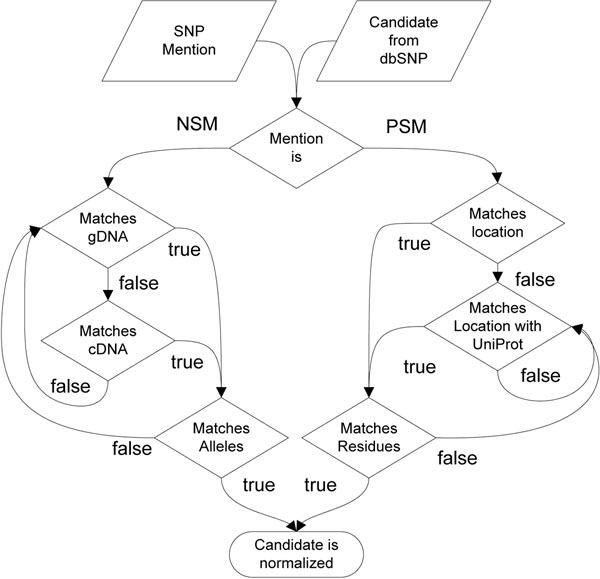
Results: This article describes a workflow for normalization of variation mentions, i.e. the association of them to unique database identifiers. Common pitfalls in the interpretation of single nucleotide polymorphism (SNP) mentions are highlighted and discussed. The developed normalization procedure achieves a precision of 98.1 % and a recall of 67.5% for unambiguous association of variation mentions with dbSNP identifiers on a text corpus based on 296 MEDLINE abstracts containing 527 mentions of SNPs. The annotated corpus is freely available at http://www.scai.fraunhofer.de/snp-normalization-corpus.html.
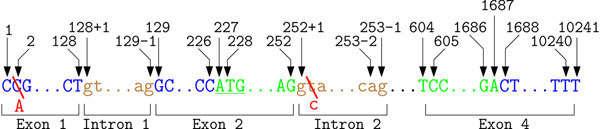
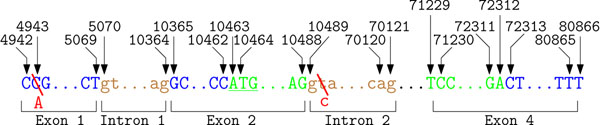
Conclusions: Comparable approaches usually focus on variations mentioned on the protein sequence and neglect problems for other SNP mentions. The results presented here indicate that normalizing SNPs described on DNA level is more difficult than the normalization of SNPs described on protein level. The challenges associated with normalization are exemplified with ambiguities and errors, which occur in this corpus.
Figures

References
-
- Collins FS, Brooks LD, Chakravarti A. A DNA polymorphism discovery resource for research on human genetic variation. Genome Research. 1998;8(12):1229–1231. - PubMed
-
- Rösler A, Bailey L, Jones S, Briggs J, Cuss S, Horsey I, Kenrick M, Kingsmore S, Kent L, Pickering J, Knott T, Shipstone E, Scozzafava G. Rolling circle amplification for scoring single nucleotide polymorphisms. Nucleosides Nucleotides Nucleic Acids. 2001;20(4-7):893–894. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
