

CASP9 results compared to those of previous CASP experiments
- PMID: 21997643
- PMCID: PMC4180080
- DOI: 10.1002/prot.23182
CASP9 results compared to those of previous CASP experiments
Abstract
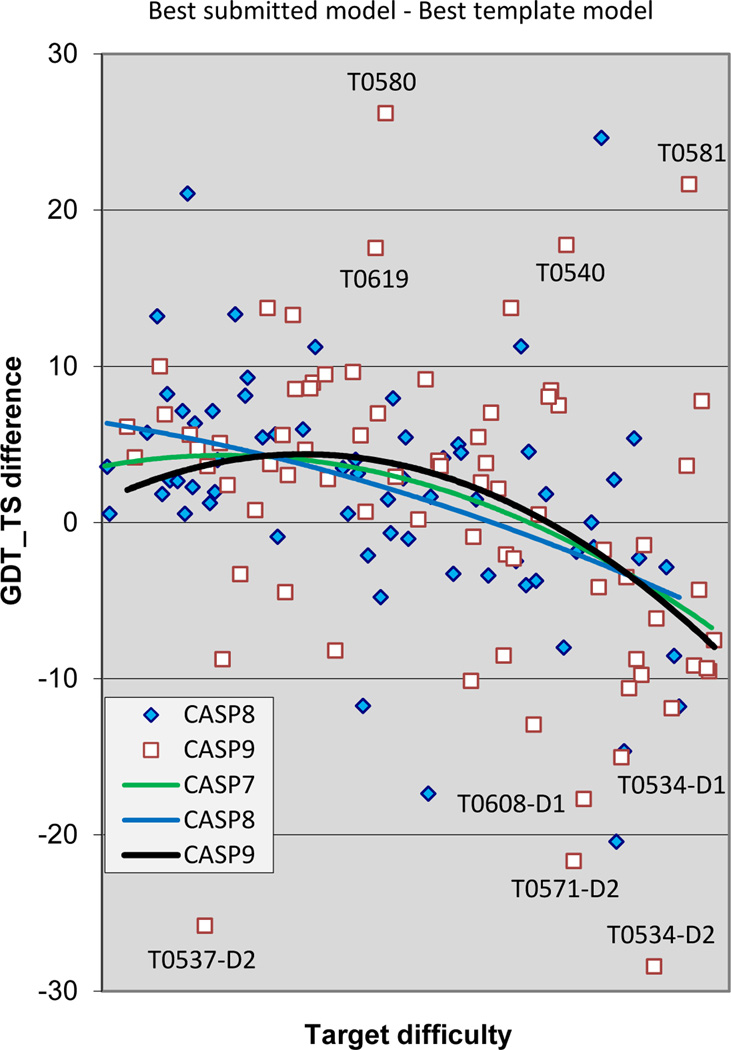
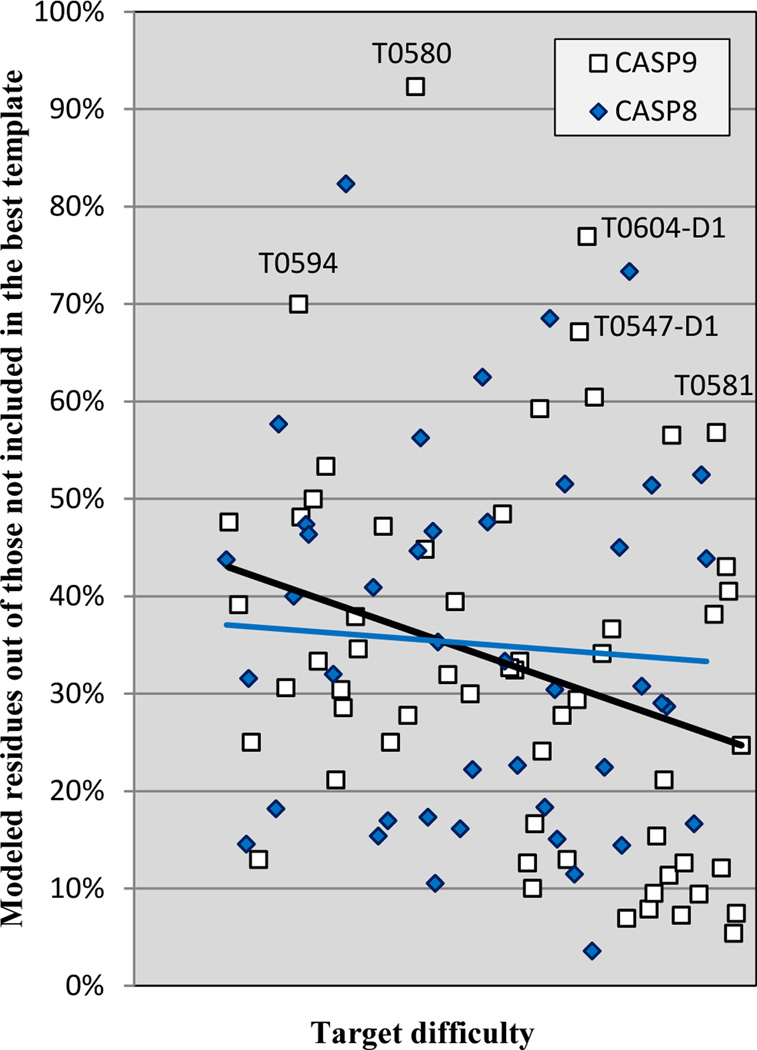
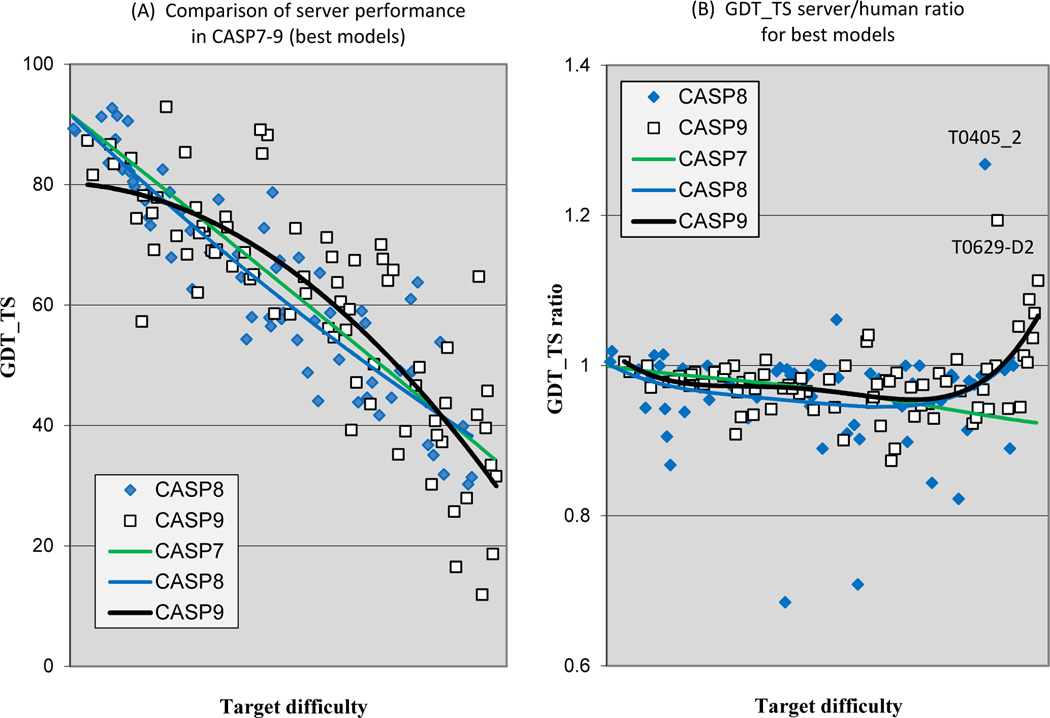
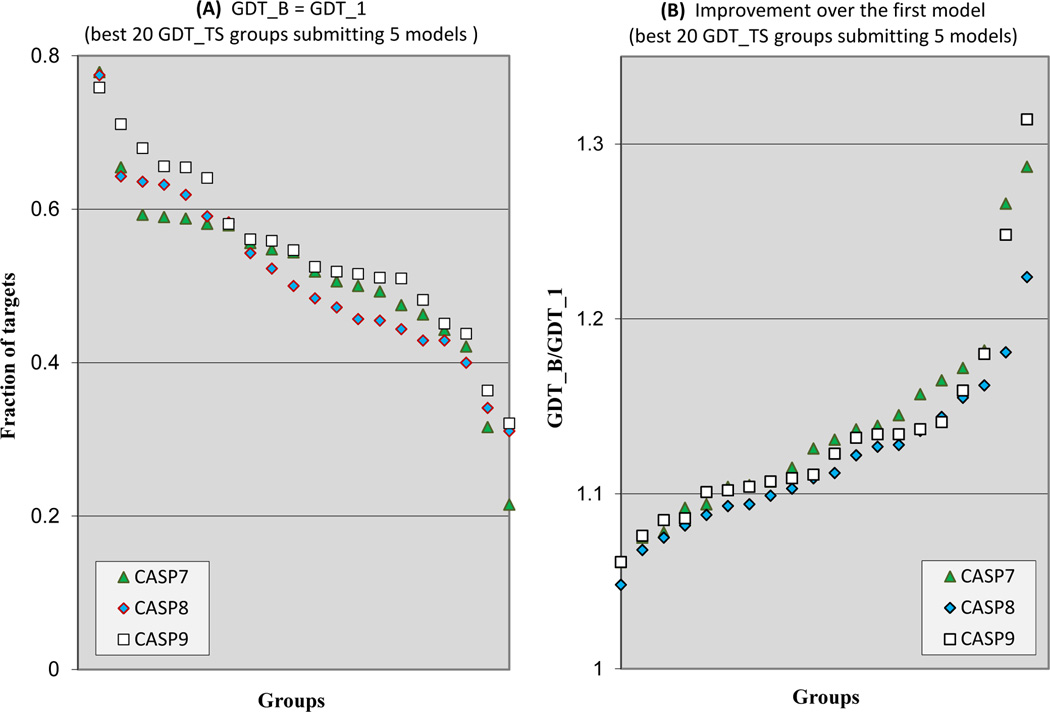
The quality of structure models submitted to CASP9 is analyzed in the context of previous CASPs. Comparison methods are similar to those used in previous articles in this series, with the addition of new methods looking at model quality in regions not covered by a single best structural template, alignment accuracy, and progress for template-free models. Progress in this CASP was again modest and statistically hard to validate. Nevertheless, there are several positive trends. There is an indication of improvement in overall model quality for the midrange of template-based modeling difficulty, methods for identifying the best model from a set generated have improved, and there are strong indications of progress in the quality of template-free models of short proteins. In addition, the new examination of a model quality in regions of model not covered by the best available template reveals better performance than had previously been apparent.
Copyright © 2011 Wiley-Liss, Inc.
Figures
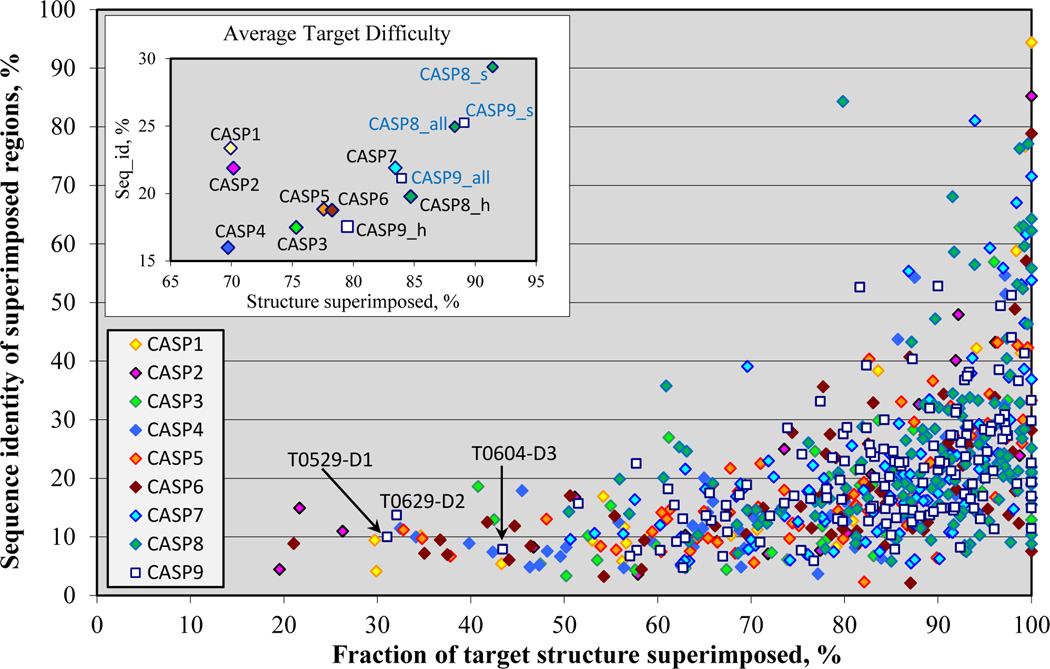
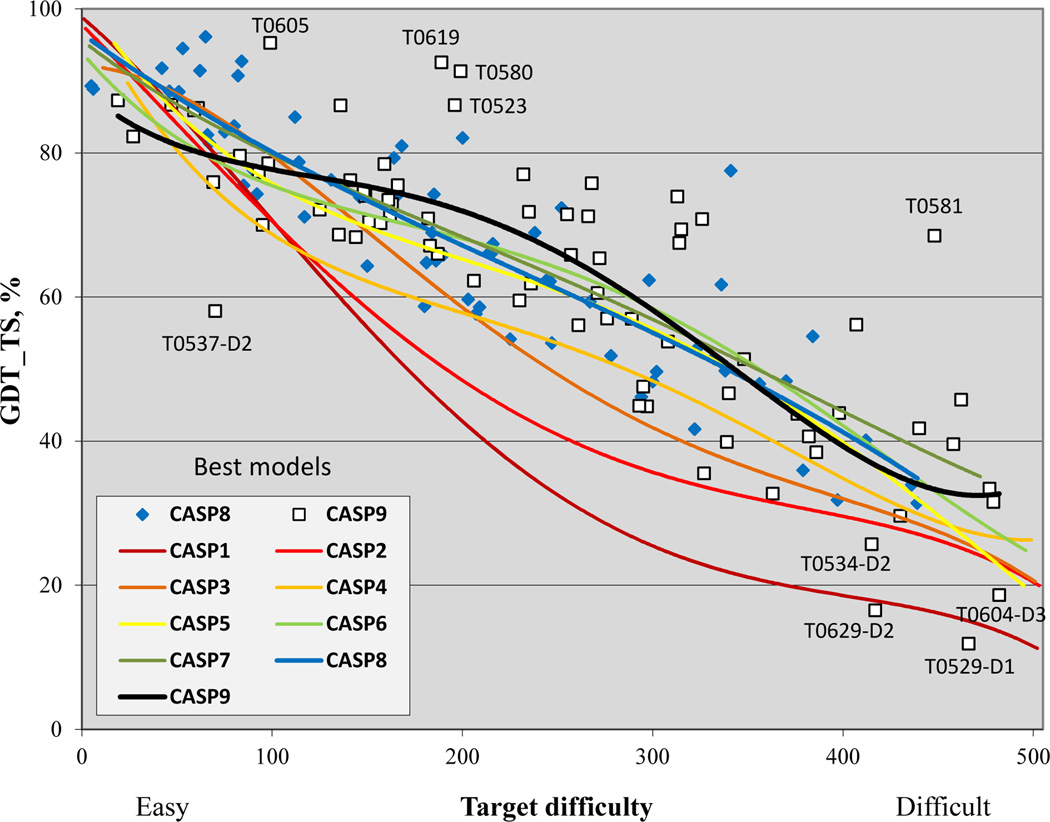
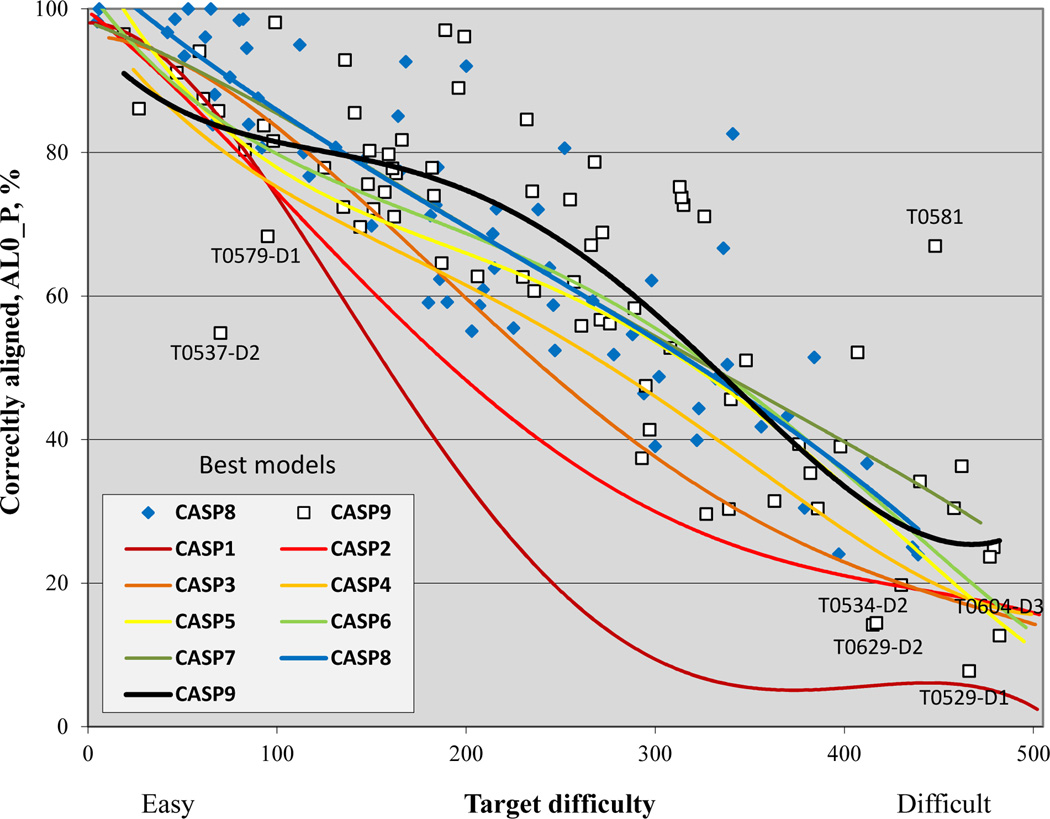
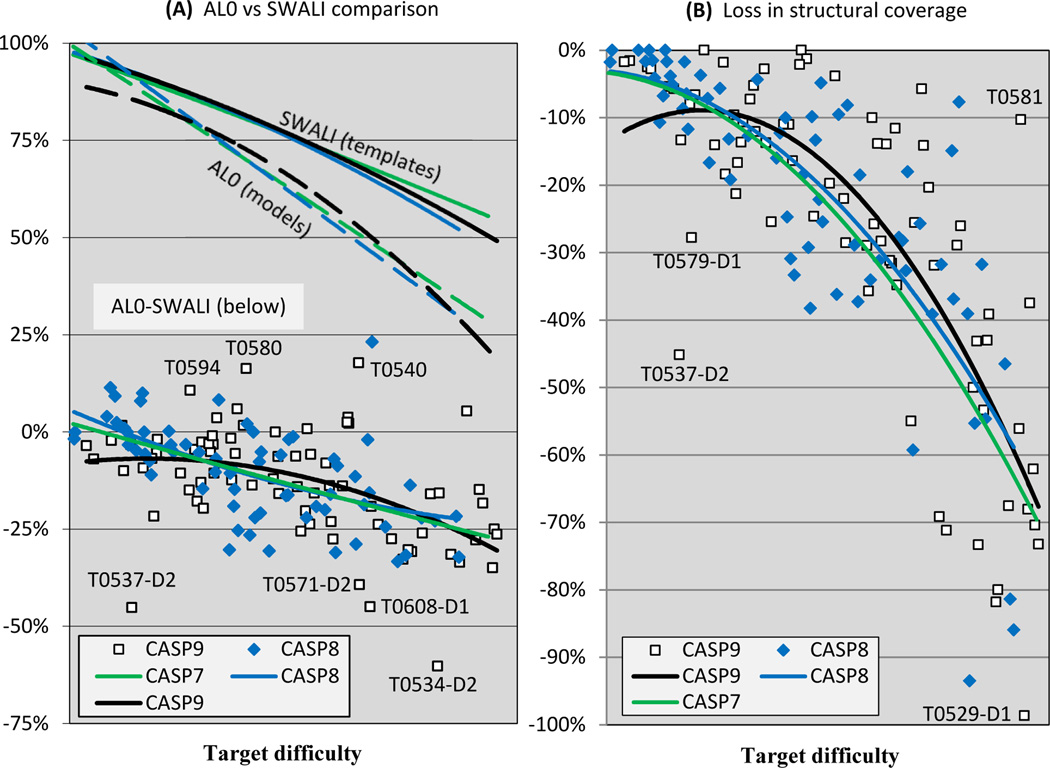
References
-
- Schwede T. CASP9 TBM assessment. Proteins. 2011 (Current).
-
- Kryshtafovych A, Fidelis K, Moult J. Progress from CASP6 to CASP7. Proteins. 2007;69(Suppl 8):194–207. - PubMed
-
- Kryshtafovych A, Venclovas C, Fidelis K, Moult J. Progress over the first decade of CASP experiments. Proteins. 2005;61(Suppl 7):225–236. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
