

Monkeys and humans share a common computation for face/voice integration
- PMID: 21998576
- PMCID: PMC3182859
- DOI: 10.1371/journal.pcbi.1002165
Monkeys and humans share a common computation for face/voice integration
Abstract
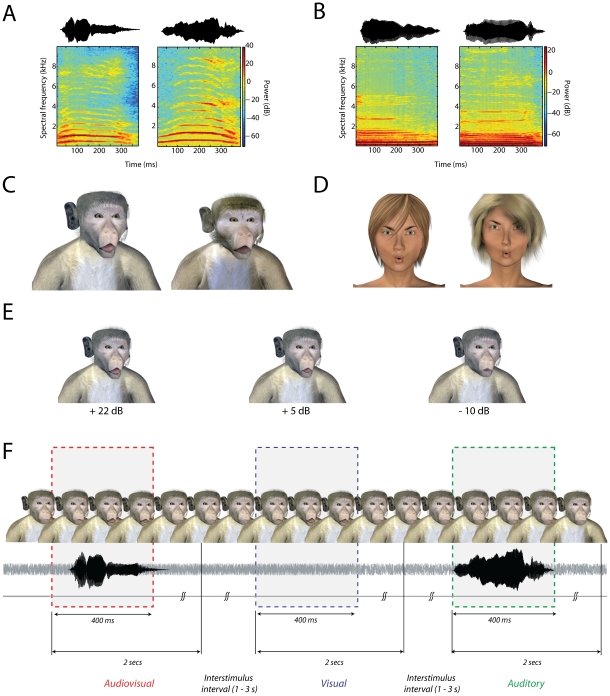
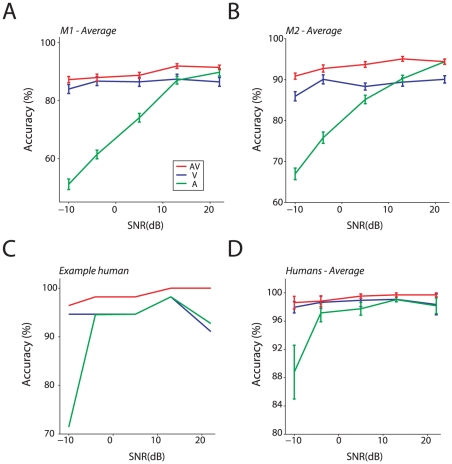
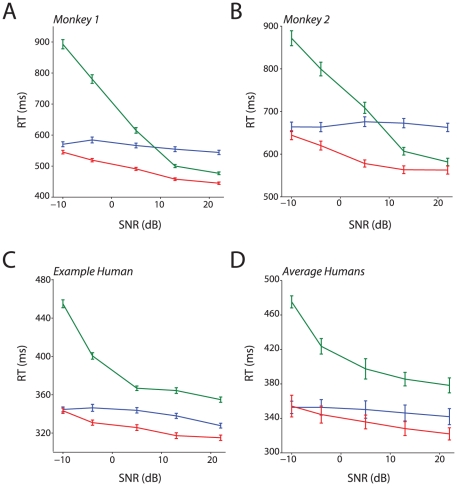
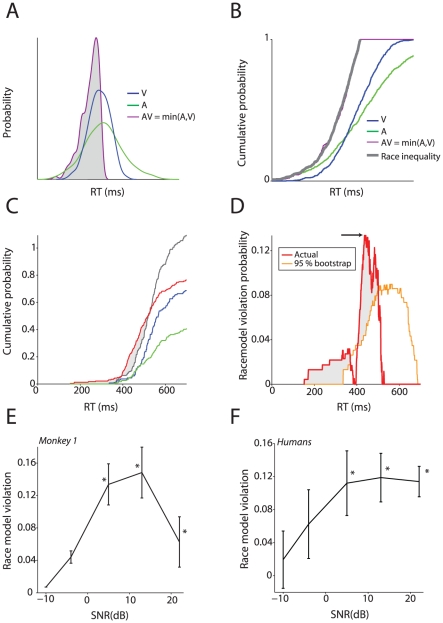
Speech production involves the movement of the mouth and other regions of the face resulting in visual motion cues. These visual cues enhance intelligibility and detection of auditory speech. As such, face-to-face speech is fundamentally a multisensory phenomenon. If speech is fundamentally multisensory, it should be reflected in the evolution of vocal communication: similar behavioral effects should be observed in other primates. Old World monkeys share with humans vocal production biomechanics and communicate face-to-face with vocalizations. It is unknown, however, if they, too, combine faces and voices to enhance their perception of vocalizations. We show that they do: monkeys combine faces and voices in noisy environments to enhance their detection of vocalizations. Their behavior parallels that of humans performing an identical task. We explored what common computational mechanism(s) could explain the pattern of results we observed across species. Standard explanations or models such as the principle of inverse effectiveness and a "race" model failed to account for their behavior patterns. Conversely, a "superposition model", positing the linear summation of activity patterns in response to visual and auditory components of vocalizations, served as a straightforward but powerful explanatory mechanism for the observed behaviors in both species. As such, it represents a putative homologous mechanism for integrating faces and voices across primates.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
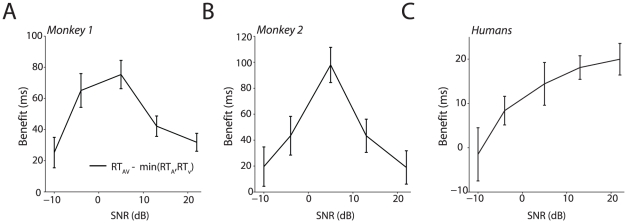
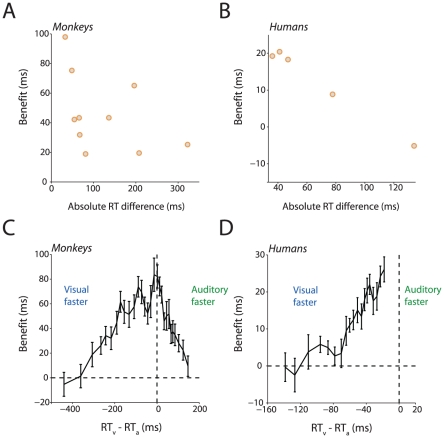
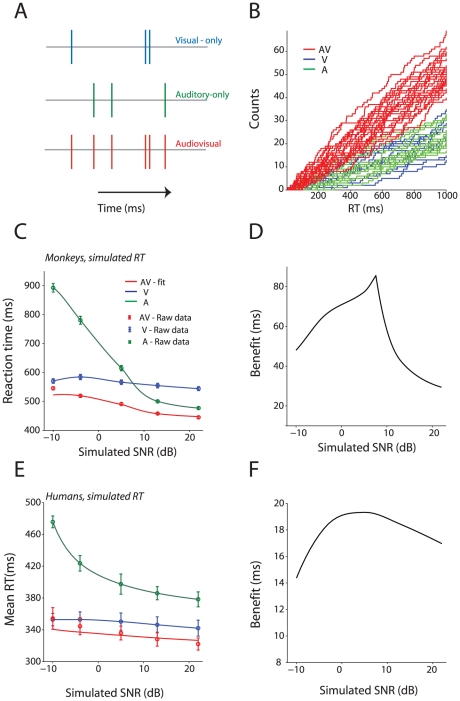
References
-
- Ohala J. Temporal Regulation of Speech. In: Fant G, Tatham MAA, editors. Auditory Analysis and Perception of Speech. London: Academic Press; 1975.
-
- Summerfield Q. Some preliminaries to a comprehensive account of audio-visual speech perception. In: Dodd B, Campbell R, editors. Hearing by Eye: The Psychology of Lipreading. Hillsdale, New Jersey: Lawrence Earlbaum; 1987. pp. 3–51.
-
- Summerfield Q. Lipreading and Audio-Visual Speech Perception. Philos Trans Roy Soc B. 1992;335:71–78. - PubMed
-
- Yehia H, Rubin P, Vatikiotis-Bateson E. Quantitative association of vocal-tract and facial behavior. Speech Comm. 1998;26:23–43.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
