

Word recognition reflects dimension-based statistical learning
- PMID: 22004192
- PMCID: PMC3285244
- DOI: 10.1037/a0025641
Word recognition reflects dimension-based statistical learning
Abstract
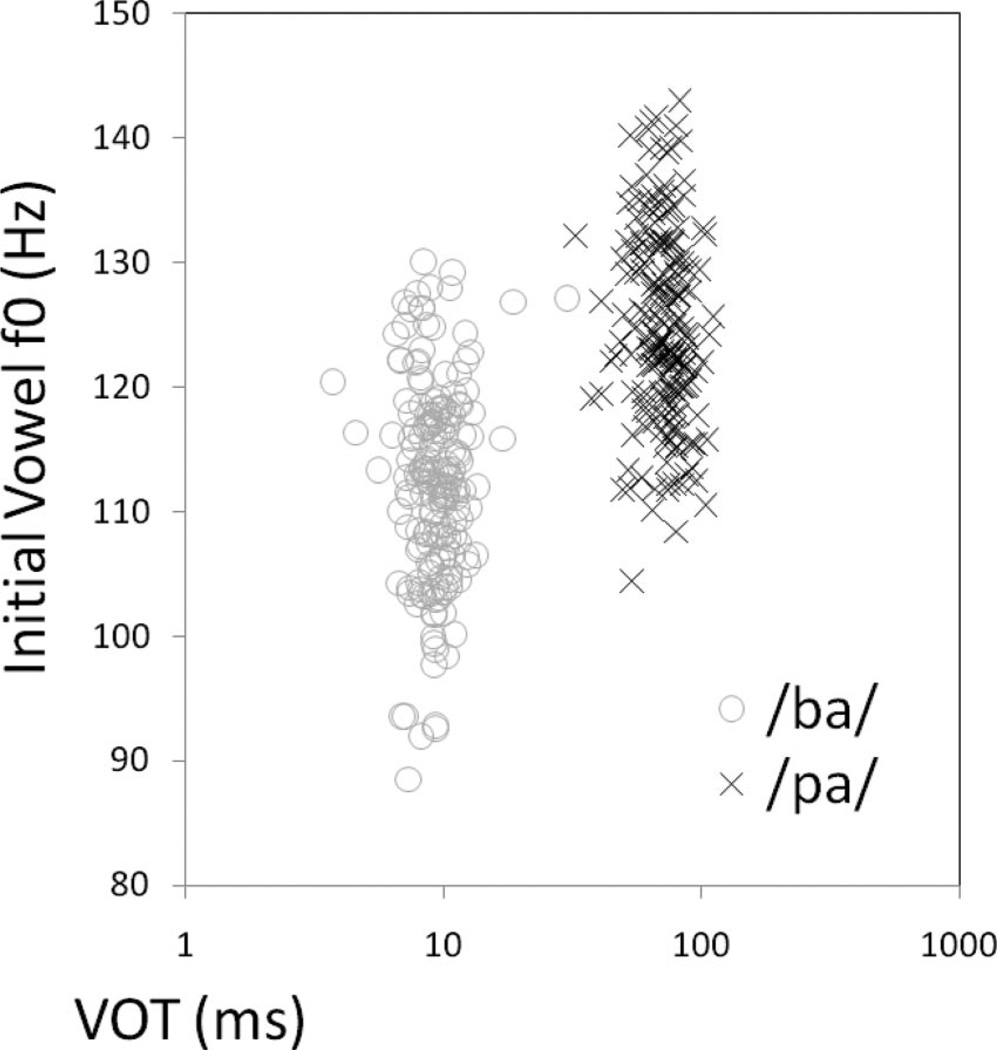
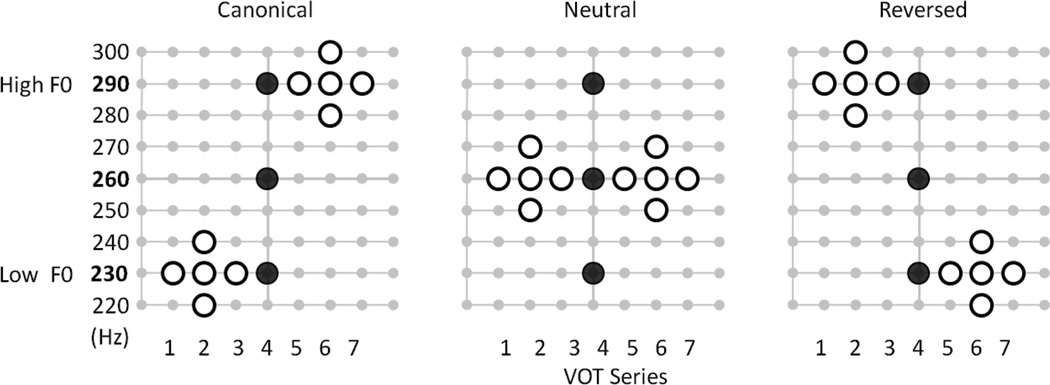
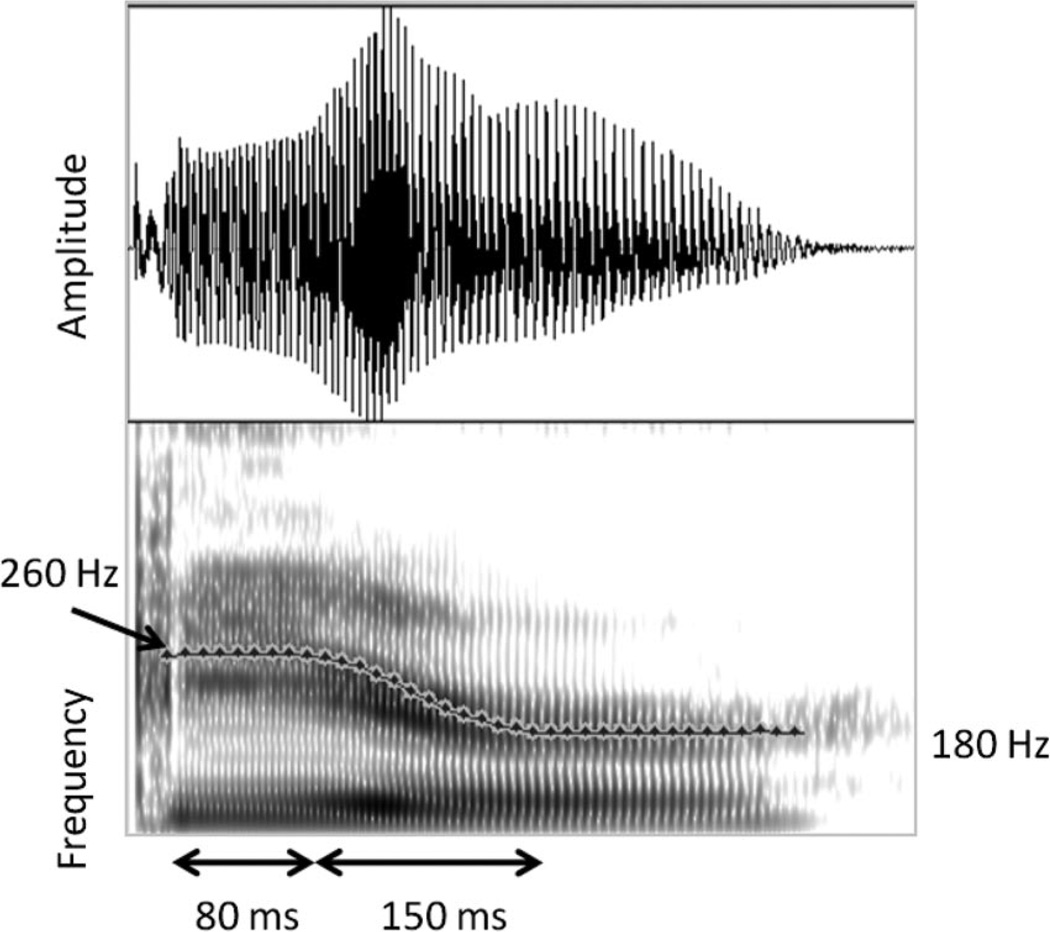
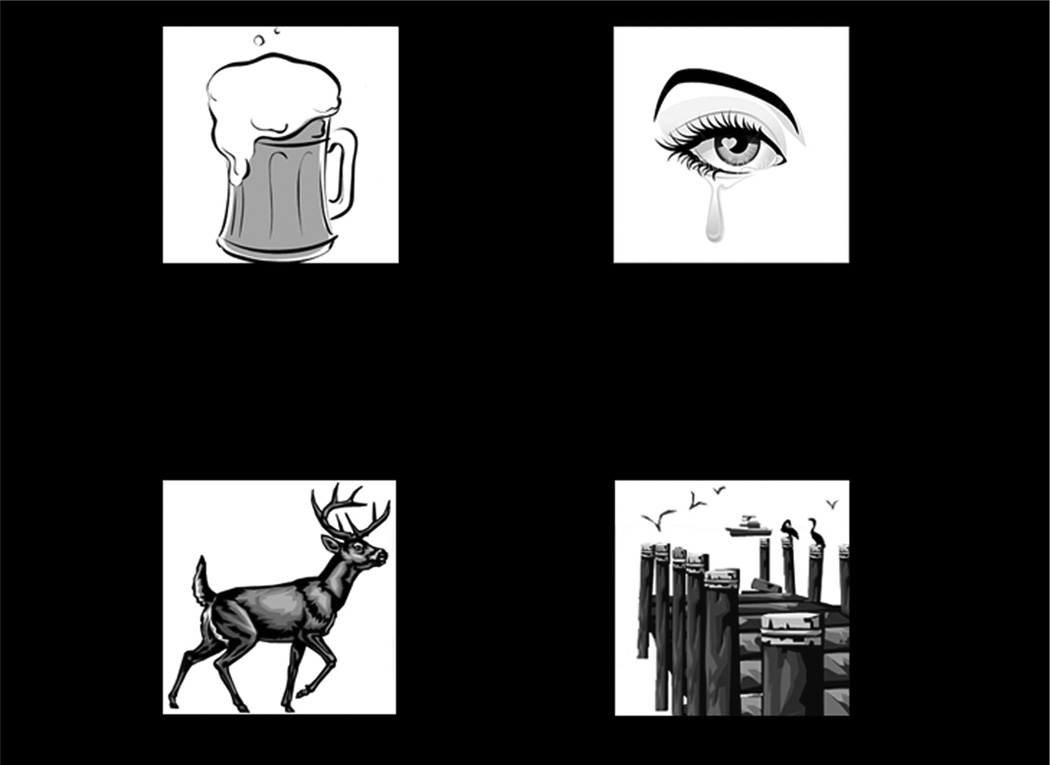
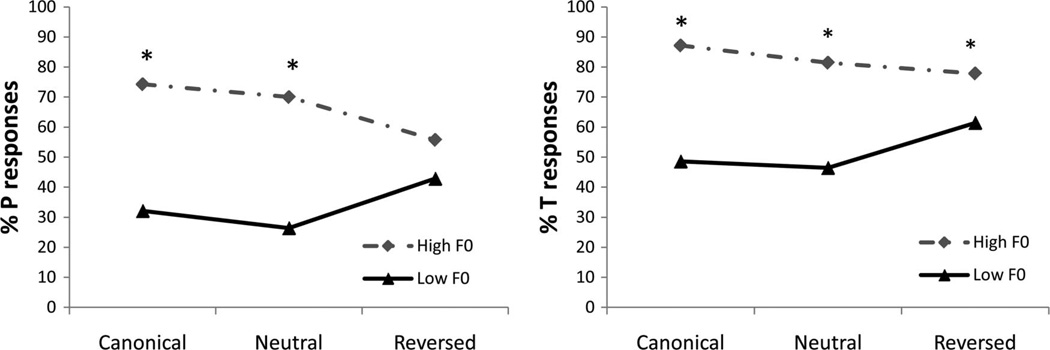
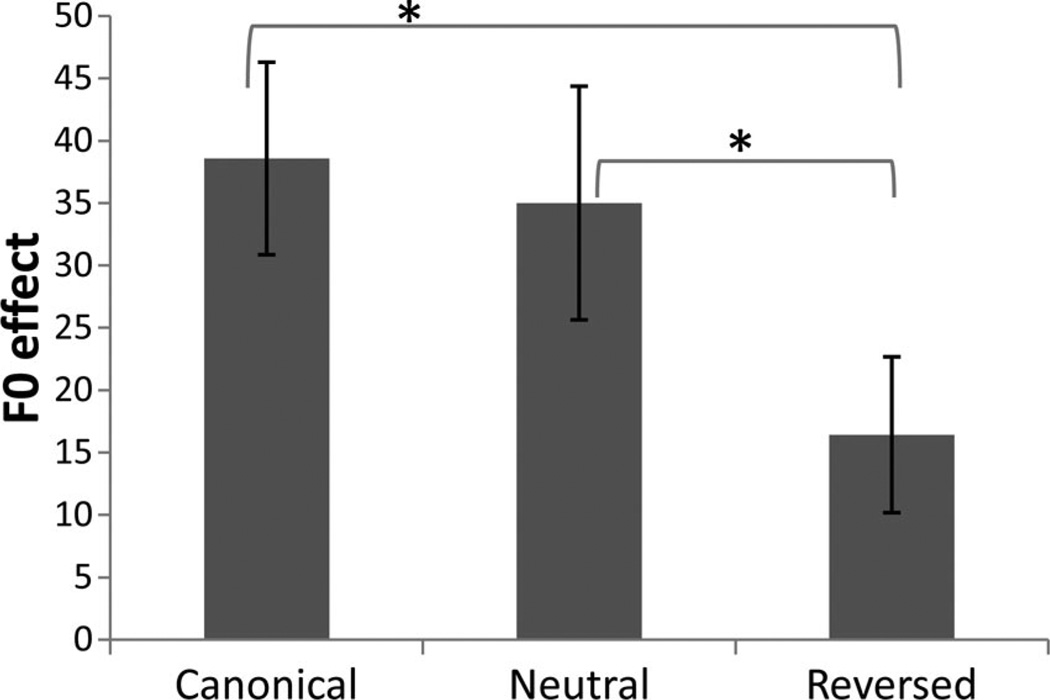
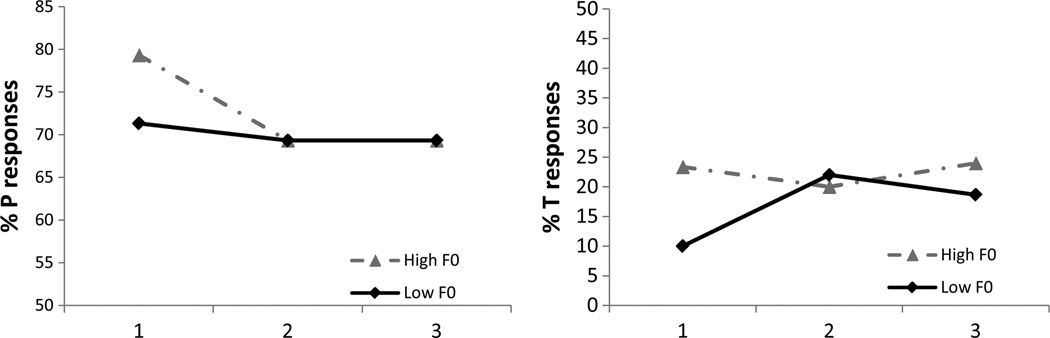
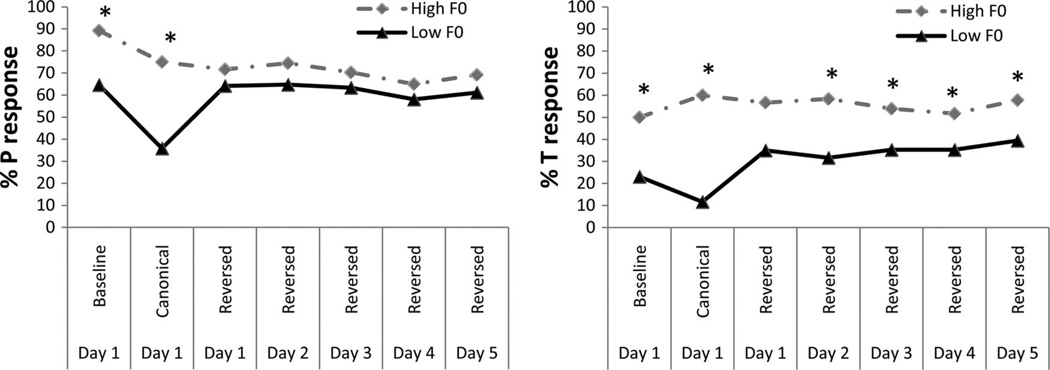
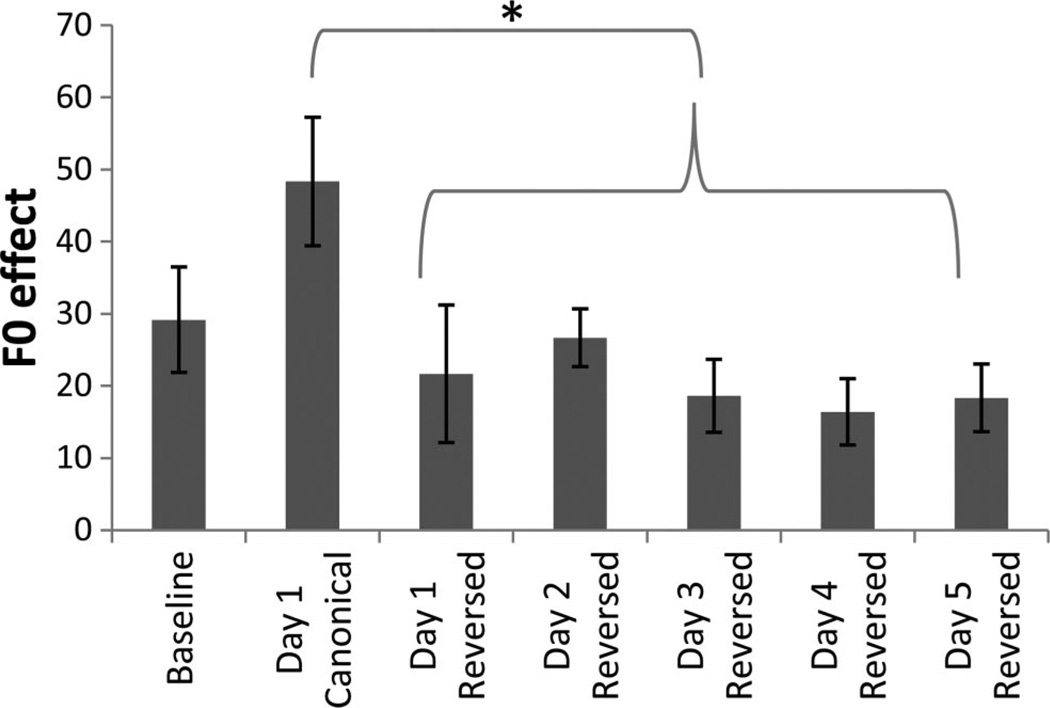
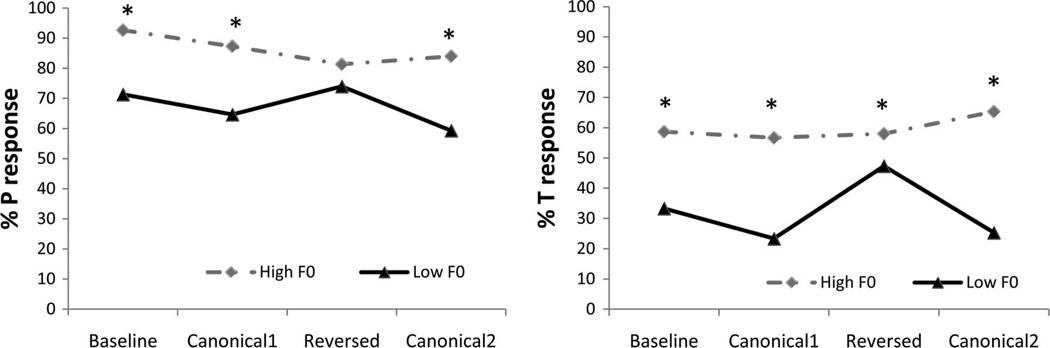
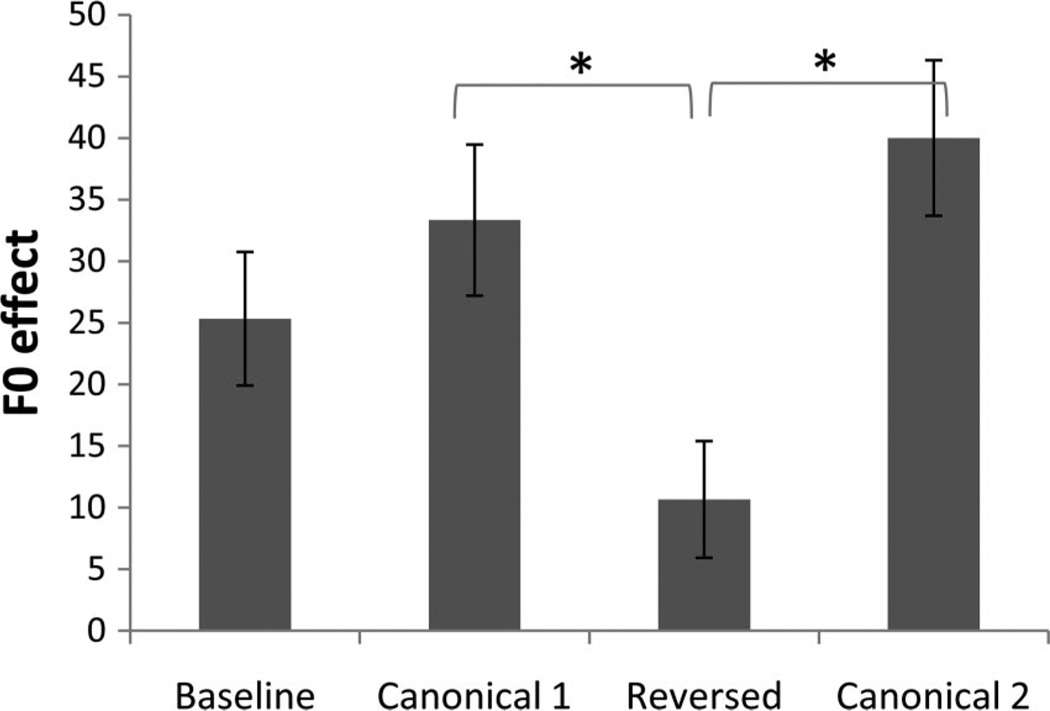
Speech processing requires sensitivity to long-term regularities of the native language yet demands listeners to flexibly adapt to perturbations that arise from talker idiosyncrasies such as nonnative accent. The present experiments investigate whether listeners exhibit dimension-based statistical learning of correlations between acoustic dimensions defining perceptual space for a given speech segment. While engaged in a word recognition task guided by a perceptually unambiguous voice-onset time (VOT) acoustics to signal beer, pier, deer, or tear, listeners were exposed incidentally to an artificial "accent" deviating from English norms in its correlation of the pitch onset of the following vowel (F0) to VOT. Results across four experiments are indicative of rapid, dimension-based statistical learning; reliance on the F0 dimension in word recognition was rapidly down-weighted in response to the perturbation of the correlation between F0 and VOT dimensions. However, listeners did not simply mirror the short-term input statistics. Instead, response patterns were consistent with a lingering influence of sensitivity to the long-term regularities of English. This suggests that the very acoustic dimensions defining perceptual space are not fixed and, rather, are dynamically and rapidly adjusted to the idiosyncrasies of local experience, such as might arise from nonnative-accent, dialect, or dysarthria. The current findings extend demonstrations of "object-based" statistical learning across speech segments to include incidental, online statistical learning of regularities residing within a speech segment.
Figures
References
-
- Abramson AS, Lisker L. Relative power of cues: F0 shift versus voice timing. In: Fromkin V, editor. Phonetic linguistics: Essays in honor of Peter Ladefoged. New York, NY: Academic; 1985. pp. 25–33.
-
- Bertelson P, Vroomen J, De Gelder B. Visual recalibration of auditory speech identification: A McGurk aftereffect. Psychological Science. 2003;14:592–597. - PubMed
-
- Boersma P, Weenink D. Praat: Doing phonetics by computer [Computer program]. Version 5.0. 2010 retrieved from http://www.praat.org/
-
- Castleman WA, Diehl RL. Effects of fundamental frequency on medial and final [voice] judgments. Journal of Phonetics. 1996;24:383–398.
-
- Chistovich LA. Variations of the fundamental voice pitch as a discriminatory cue for consonants. Soviet Physics-Acoustics. 1969;14
