

Inference of functional properties from large-scale analysis of enzyme superfamilies
- PMID: 22069325
- PMCID: PMC3249087
- DOI: 10.1074/jbc.R111.283408
Inference of functional properties from large-scale analysis of enzyme superfamilies
Abstract
As increasingly large amounts of data from genome and other sequencing projects become available, new approaches are needed to determine the functions of the proteins these genes encode. We show how large-scale computational analysis can help to address this challenge by linking functional information to sequence and structural similarities using protein similarity networks. Network analyses using three functionally diverse enzyme superfamilies illustrate the use of these approaches for facile updating and comparison of available structures for a large superfamily, for creation of functional hypotheses for metagenomic sequences, and to summarize the limits of our functional knowledge about even well studied superfamilies.
Figures
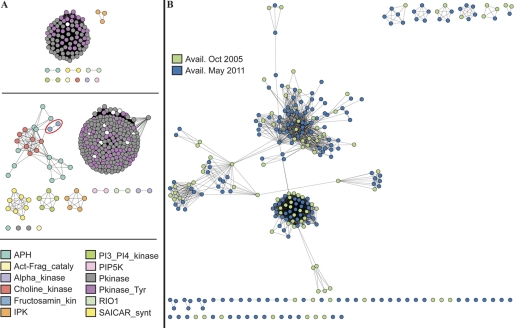
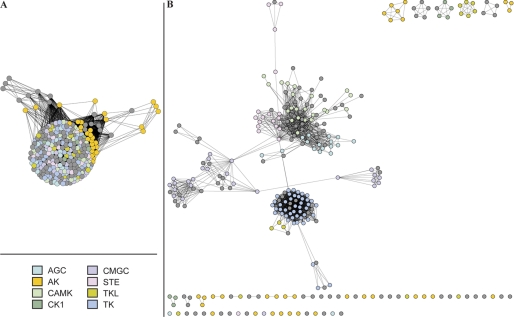
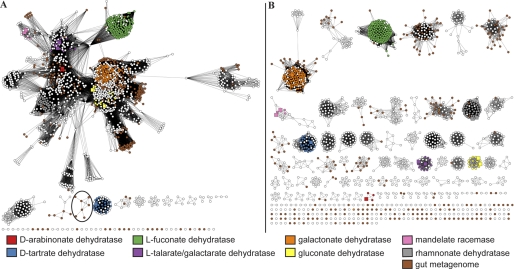
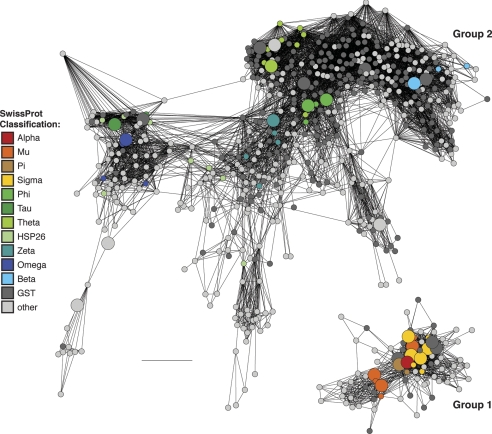
References
-
- Dutta S., Burkhardt K., Young J., Swaminathan G. J., Matsuura T., Henrick K., Nakamura H., Berman H. M. (2009) Mol. Biotechnol 42, 1–13 - PubMed
-
- Qin J., Li R., Raes J., Arumugam M., Burgdorf K. S., Manichanh C., Nielsen T., Pons N., Levenez F., Yamada T., Mende D. R., Li J., Xu J., Li S., Li D., Cao J., Wang B., Liang H., Zheng H., Xie Y., Tap J., Lepage P., Bertalan M., Batto J. M., Hansen T., Le Paslier D., Linneberg A., Nielsen H. B., Pelletier E., Renault P., Sicheritz-Ponten T., Turner K., Zhu H., Yu C., Li S., Jian M., Zhou Y., Li Y., Zhang X., Li S., Qin N., Yang H., Wang J., Brunak S., Doré J., Guarner F., Kristiansen K., Pedersen O., Parkhill J., Weissenbach J., Bork P., Ehrlich S. D., Wang J. (2010) Nature 464, 59–65 - PMC - PubMed
-
- Roberts R. J., Chang Y. C., Hu Z., Rachlin J. N., Anton B. P., Pokrzywa R. M., Choi H. P., Faller L. L., Guleria J., Housman G., Klitgord N., Mazumdar V., McGettrick M. G., Osmani L., Swaminathan R., Tao K. R., Letovsky S., Vitkup D., Segrè D., Salzberg S. L., Delisi C., Steffen M., Kasif S. (2011) Nucleic Acids Res. 39, D11–D14 - PMC - PubMed
-
- Bateman A. (2010) Bioinformatics 26, 991. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
