

BioCreative III interactive task: an overview
- PMID: 22151968
- PMCID: PMC3269939
- DOI: 10.1186/1471-2105-12-S8-S4
BioCreative III interactive task: an overview
Abstract
Background: The BioCreative challenge evaluation is a community-wide effort for evaluating text mining and information extraction systems applied to the biological domain. The biocurator community, as an active user of biomedical literature, provides a diverse and engaged end user group for text mining tools. Earlier BioCreative challenges involved many text mining teams in developing basic capabilities relevant to biological curation, but they did not address the issues of system usage, insertion into the workflow and adoption by curators. Thus in BioCreative III (BC-III), the InterActive Task (IAT) was introduced to address the utility and usability of text mining tools for real-life biocuration tasks. To support the aims of the IAT in BC-III, involvement of both developers and end users was solicited, and the development of a user interface to address the tasks interactively was requested.
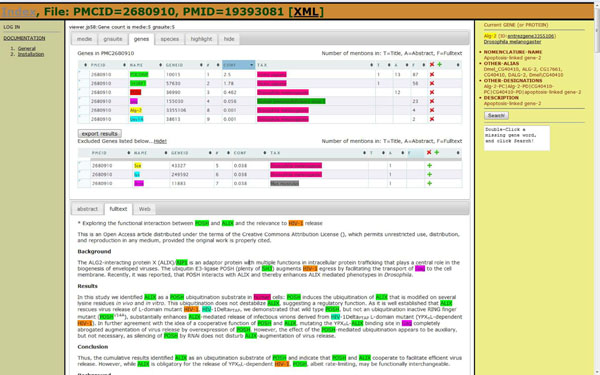
Results: A User Advisory Group (UAG) actively participated in the IAT design and assessment. The task focused on gene normalization (identifying gene mentions in the article and linking these genes to standard database identifiers), gene ranking based on the overall importance of each gene mentioned in the article, and gene-oriented document retrieval (identifying full text papers relevant to a selected gene). Six systems participated and all processed and displayed the same set of articles. The articles were selected based on content known to be problematic for curation, such as ambiguity of gene names, coverage of multiple genes and species, or introduction of a new gene name. Members of the UAG curated three articles for training and assessment purposes, and each member was assigned a system to review. A questionnaire related to the interface usability and task performance (as measured by precision and recall) was answered after systems were used to curate articles. Although the limited number of articles analyzed and users involved in the IAT experiment precluded rigorous quantitative analysis of the results, a qualitative analysis provided valuable insight into some of the problems encountered by users when using the systems. The overall assessment indicates that the system usability features appealed to most users, but the system performance was suboptimal (mainly due to low accuracy in gene normalization). Some of the issues included failure of species identification and gene name ambiguity in the gene normalization task leading to an extensive list of gene identifiers to review, which, in some cases, did not contain the relevant genes. The document retrieval suffered from the same shortfalls. The UAG favored achieving high performance (measured by precision and recall), but strongly recommended the addition of features that facilitate the identification of correct gene and its identifier, such as contextual information to assist in disambiguation.
Discussion: The IAT was an informative exercise that advanced the dialog between curators and developers and increased the appreciation of challenges faced by each group. A major conclusion was that the intended users should be actively involved in every phase of software development, and this will be strongly encouraged in future tasks. The IAT Task provides the first steps toward the definition of metrics and functional requirements that are necessary for designing a formal evaluation of interactive curation systems in the BioCreative IV challenge.
Figures

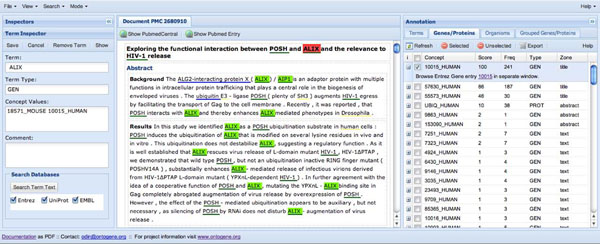
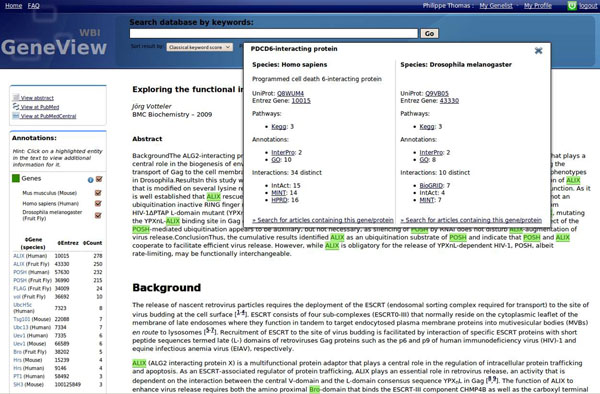
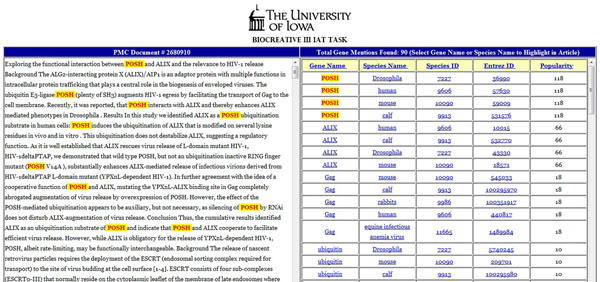
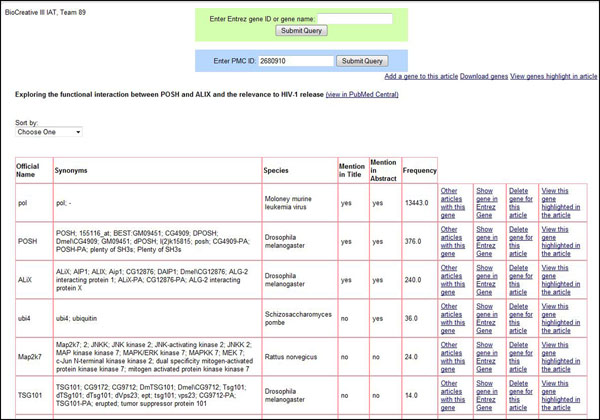

References
-
- Leitner F, Mardis SA, Krallinger M, Cesareni G, Hirschman LA, Valencia A. An Overview of BioCreative II.5. IEEE/ACM Trans Comput Biol Bioinform. 2010;7(3):385–399. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
