

Detecting novel associations in large data sets
- PMID: 22174245
- PMCID: PMC3325791
- DOI: 10.1126/science.1205438
Detecting novel associations in large data sets
Abstract
Identifying interesting relationships between pairs of variables in large data sets is increasingly important. Here, we present a measure of dependence for two-variable relationships: the maximal information coefficient (MIC). MIC captures a wide range of associations both functional and not, and for functional relationships provides a score that roughly equals the coefficient of determination (R(2)) of the data relative to the regression function. MIC belongs to a larger class of maximal information-based nonparametric exploration (MINE) statistics for identifying and classifying relationships. We apply MIC and MINE to data sets in global health, gene expression, major-league baseball, and the human gut microbiota and identify known and novel relationships.
Figures
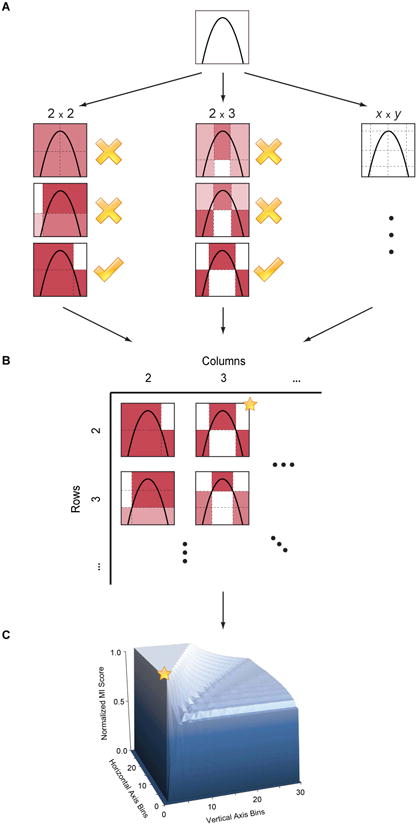


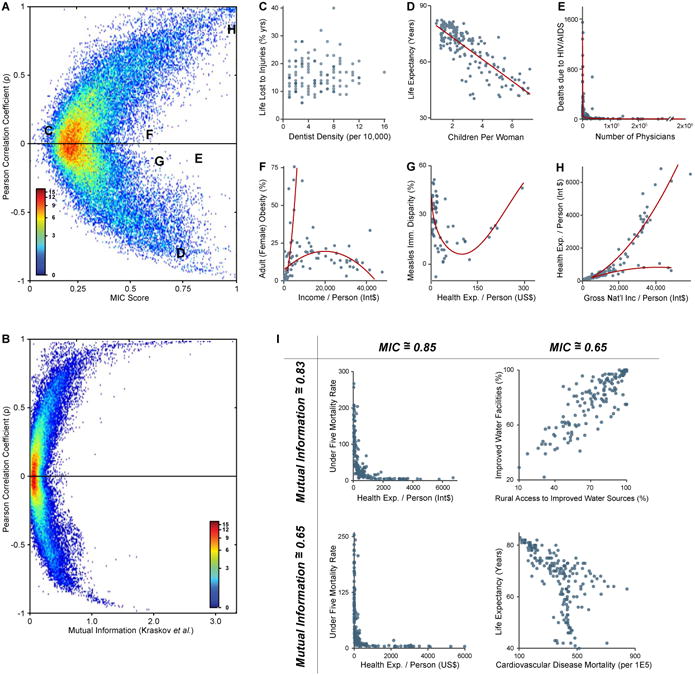


Comment in
-
Mathematics. A correlation for the 21st century.Science. 2011 Dec 16;334(6062):1502-3. doi: 10.1126/science.1215894. Science. 2011. PMID: 22174235 No abstract available.
References
-
- Hastie T, Tibshirani R, Friedman JH. The elements of statistical learning: data mining, inference, and prediction. Springer Verlag; 2009.
-
- Science Staff, Challenges and opportunities. Science. 2011;331:693. - PubMed
-
-
By ‘functional relationship’ we mean a distribution (X,Y) in which Y is a function of X, potentially with independent noise added.
-
-
- Caspi A, et al. Influence of life stress on depression: moderation by a polymorphism in the 5-HTT gene. Science. 2003;301:386. - PubMed
-
- Clayton RN, Mayeda TK. Oxygen isotope studies of achondrites. Geochimica et Cosmochimica Acta. 1996;60:1999.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
