

GC-content normalization for RNA-Seq data
- PMID: 22177264
- PMCID: PMC3315510
- DOI: 10.1186/1471-2105-12-480
GC-content normalization for RNA-Seq data
Abstract
Background: Transcriptome sequencing (RNA-Seq) has become the assay of choice for high-throughput studies of gene expression. However, as is the case with microarrays, major technology-related artifacts and biases affect the resulting expression measures. Normalization is therefore essential to ensure accurate inference of expression levels and subsequent analyses thereof.
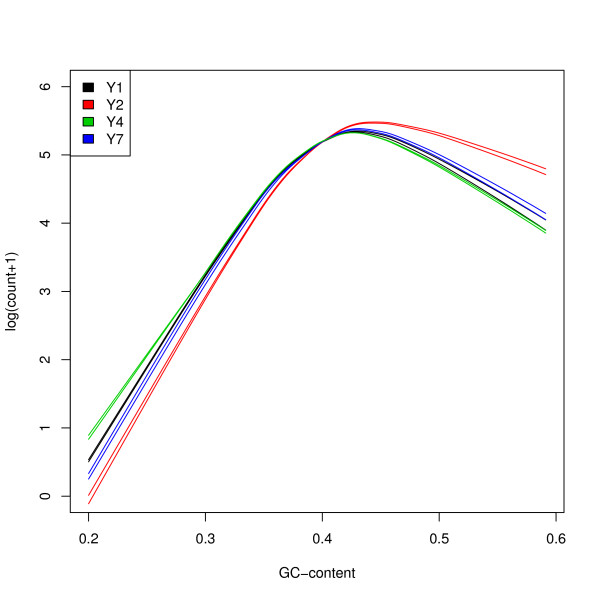
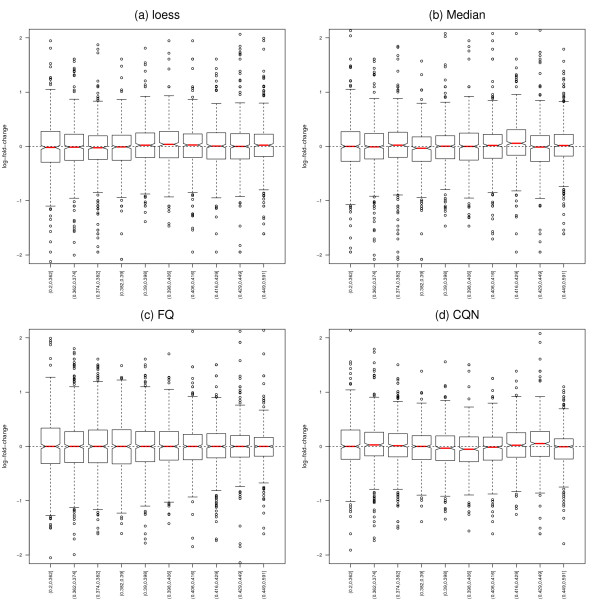
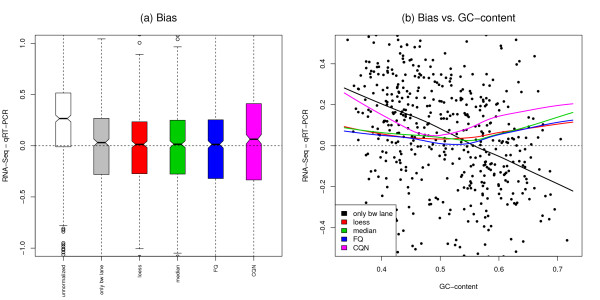
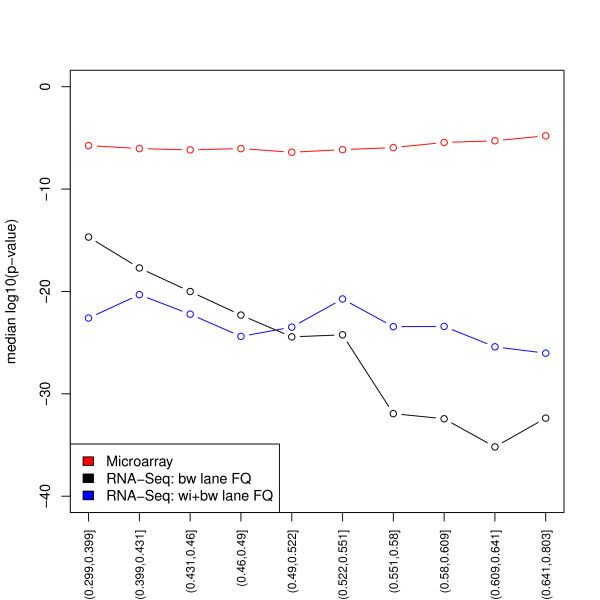
Results: We focus on biases related to GC-content and demonstrate the existence of strong sample-specific GC-content effects on RNA-Seq read counts, which can substantially bias differential expression analysis. We propose three simple within-lane gene-level GC-content normalization approaches and assess their performance on two different RNA-Seq datasets, involving different species and experimental designs. Our methods are compared to state-of-the-art normalization procedures in terms of bias and mean squared error for expression fold-change estimation and in terms of Type I error and p-value distributions for tests of differential expression. The exploratory data analysis and normalization methods proposed in this article are implemented in the open-source Bioconductor R package EDASeq.
Conclusions: Our within-lane normalization procedures, followed by between-lane normalization, reduce GC-content bias and lead to more accurate estimates of expression fold-changes and tests of differential expression. Such results are crucial for the biological interpretation of RNA-Seq experiments, where downstream analyses can be sensitive to the supplied lists of genes.
Figures



References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
