

Analyzing the heterogeneity and complexity of Electronic Health Record oriented phenotyping algorithms
- PMID: 22195079
- PMCID: PMC3243189
Analyzing the heterogeneity and complexity of Electronic Health Record oriented phenotyping algorithms
Abstract
The need for formal representations of eligibility criteria for clinical trials - and for phenotyping more generally - has been recognized for some time. Indeed, the availability of a formal computable representation that adequately reflects the types of data and logic evidenced in trial designs is a prerequisite for the automatic identification of study-eligible patients from Electronic Health Records. As part of the wider process of representation development, this paper reports on an analysis of fourteen Electronic Health Record oriented phenotyping algorithms (developed as part of the eMERGE project) in terms of their constituent data elements, types of logic used and temporal characteristics. We discovered that the majority of eMERGE algorithms analyzed include complex, nested boolean logic and negation, with several dependent on cardinality constraints and complex temporal logic. Insights gained from the study will be used to augment the CDISC Protocol Representation Model.
Figures
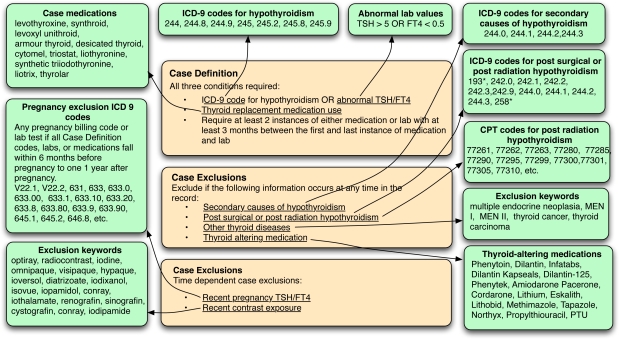

References
-
- Patel C, Gomadam K, Khan S, Vivek G. TrialX: Using semantic technologies to match patients to relevant clinical trials based on their Personal Health Records. Web Semantics: Science, Services and Agents on The World Wide Web. 2010;8:342–347.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials