

An overview of longitudinal data analysis methods for neurological research
- PMID: 22203825
- PMCID: PMC3243635
- DOI: 10.1159/000330228
An overview of longitudinal data analysis methods for neurological research
Abstract
The purpose of this article is to provide a concise, broad and readily accessible overview of longitudinal data analysis methods, aimed to be a practical guide for clinical investigators in neurology. In general, we advise that older, traditional methods, including (1) simple regression of the dependent variable on a time measure, (2) analyzing a single summary subject level number that indexes changes for each subject and (3) a general linear model approach with a fixed-subject effect, should be reserved for quick, simple or preliminary analyses. We advocate the general use of mixed-random and fixed-effect regression models for analyses of most longitudinal clinical studies. Under restrictive situations or to provide validation, we recommend: (1) repeated-measure analysis of covariance (ANCOVA), (2) ANCOVA for two time points, (3) generalized estimating equations and (4) latent growth curve/structural equation models.
Keywords: Analysis; Longitudinal studies; Methods; Neurology; Statistics.
Figures
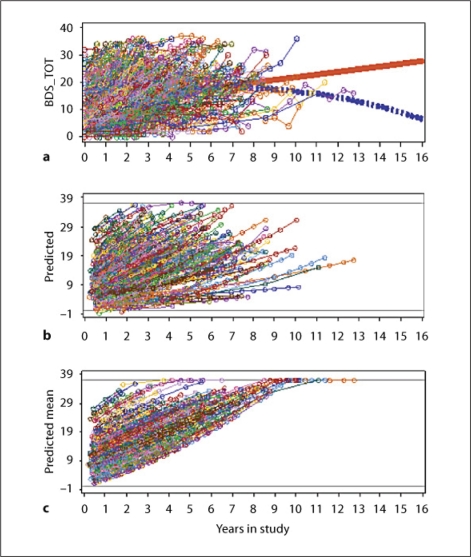
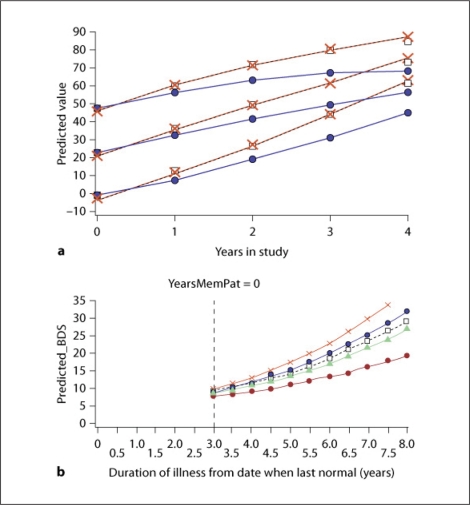
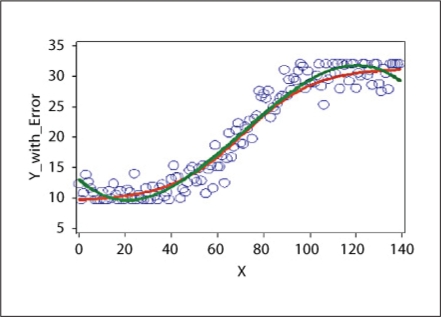
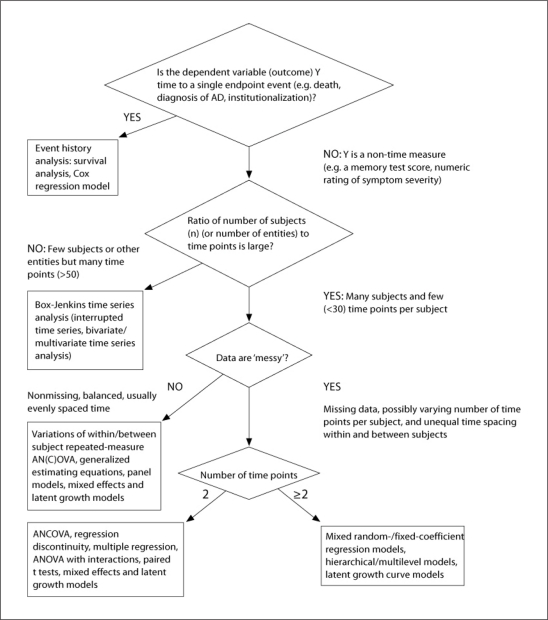
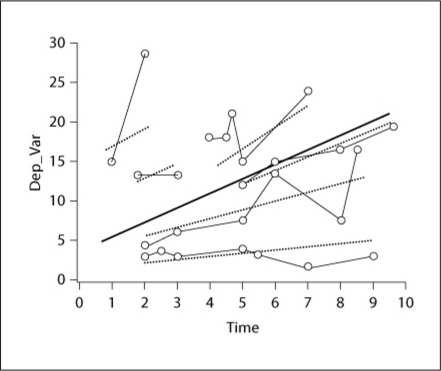
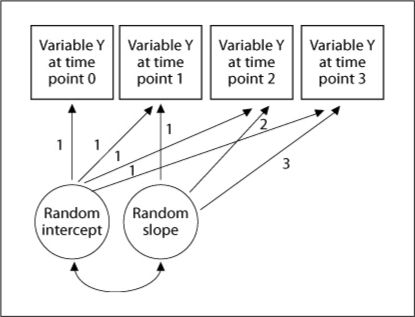
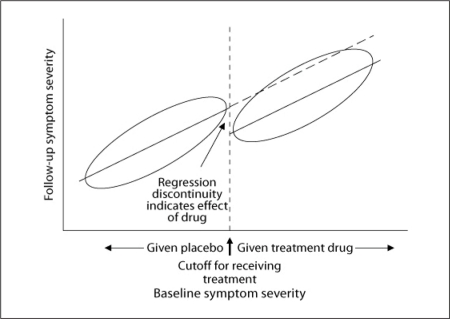
References
-
- SAS/Stat User's Guide, version 9.2. Cary: SAS Institute; 2011.
-
- Mplus Statistical Software. Los Angeles: Muthen & Muthen; 2011.
-
- SPSS Software. Chicago, Illinois: SPSS; 2011.
-
- JMP Software. Cary: SAS; 2011.
-
- Zeger SL, Liang KY. An overview of methods for the analysis of longitudinal data. Stat Med. 1992;11:1825–1839. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
