

Evolutionary dynamics of protein domain architecture in plants
- PMID: 22252370
- PMCID: PMC3310802
- DOI: 10.1186/1471-2148-12-6
Evolutionary dynamics of protein domain architecture in plants
Abstract
Background: Protein domains are the structural, functional and evolutionary units of the protein. Protein domain architectures are the linear arrangements of domain(s) in individual proteins. Although the evolutionary history of protein domain architecture has been extensively studied in microorganisms, the evolutionary dynamics of domain architecture in the plant kingdom remains largely undefined. To address this question, we analyzed the lineage-based protein domain architecture content in 14 completed green plant genomes.
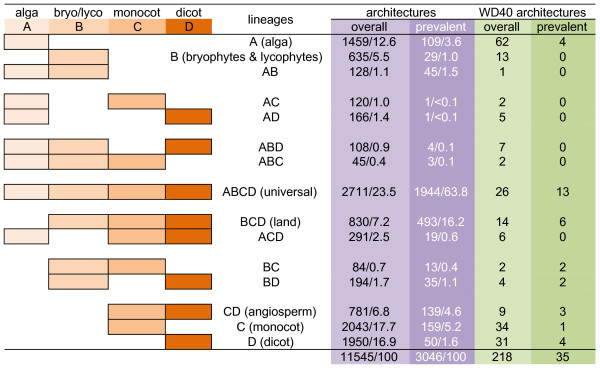
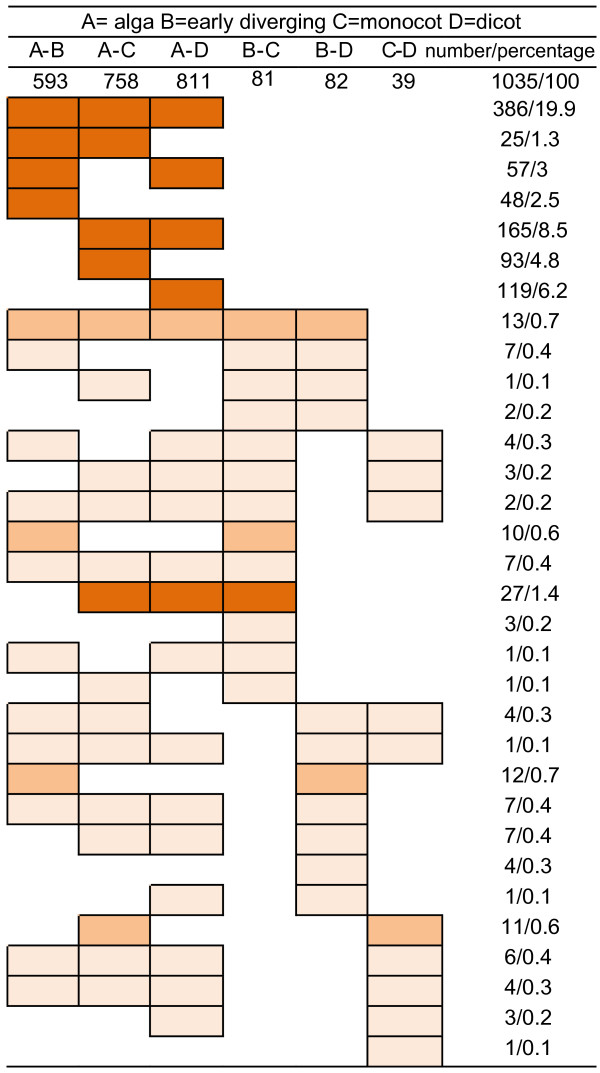
Results: Our analyses show that all 14 plant genomes maintain similar distributions of species-specific, single-domain, and multi-domain architectures. Approximately 65% of plant domain architectures are universally present in all plant lineages, while the remaining architectures are lineage-specific. Clear examples are seen of both the loss and gain of specific protein architectures in higher plants. There has been a dynamic, lineage-wise expansion of domain architectures during plant evolution. The data suggest that this expansion can be largely explained by changes in nuclear ploidy resulting from rounds of whole genome duplications. Indeed, there has been a decrease in the number of unique domain architectures when the genomes were normalized into a presumed ancestral genome that has not undergone whole genome duplications.
Conclusions: Our data show the conservation of universal domain architectures in all available plant genomes, indicating the presence of an evolutionarily conserved, core set of protein components. However, the occurrence of lineage-specific domain architectures indicates that domain architecture diversity has been maintained beyond these core components in plant genomes. Although several features of genome-wide domain architecture content are conserved in plants, the data clearly demonstrate lineage-wise, progressive changes and expansions of individual protein domain architectures, reinforcing the notion that plant genomes have undergone dynamic evolution.
Figures

References
-
- Cheng J, Sweredoski M, Baldi P. DOMpro: Protein Domain Prediction Using Profiles, Secondary Structure, Relative Solvent Accessibility, and Recursive Neural Networks. Data Mining and Knowledge Discovery. 2006;13(1):1–10. doi: 10.1007/s10618-005-0023-5. - DOI
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
