

A three-gene model to robustly identify breast cancer molecular subtypes
- PMID: 22262870
- PMCID: PMC3283537
- DOI: 10.1093/jnci/djr545
A three-gene model to robustly identify breast cancer molecular subtypes
Abstract
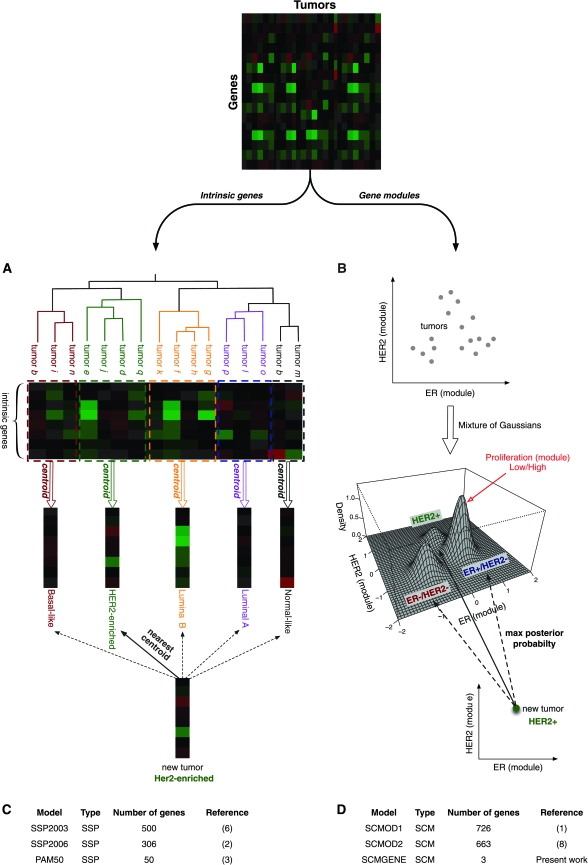
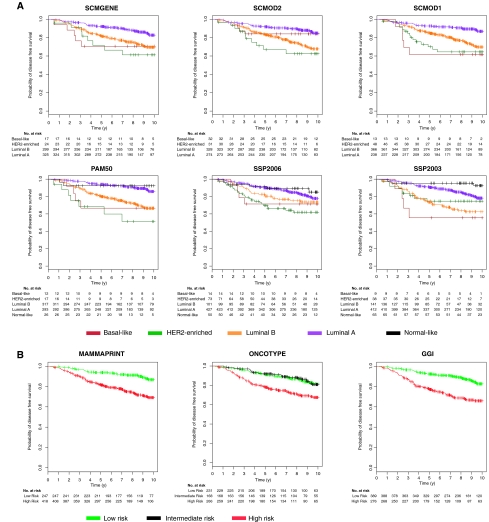
Background: Single sample predictors (SSPs) and Subtype classification models (SCMs) are gene expression-based classifiers used to identify the four primary molecular subtypes of breast cancer (basal-like, HER2-enriched, luminal A, and luminal B). SSPs use hierarchical clustering, followed by nearest centroid classification, based on large sets of tumor-intrinsic genes. SCMs use a mixture of Gaussian distributions based on sets of genes with expression specifically correlated with three key breast cancer genes (estrogen receptor [ER], HER2, and aurora kinase A [AURKA]). The aim of this study was to compare the robustness, classification concordance, and prognostic value of these classifiers with those of a simplified three-gene SCM in a large compendium of microarray datasets.
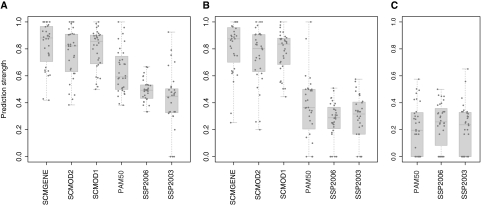
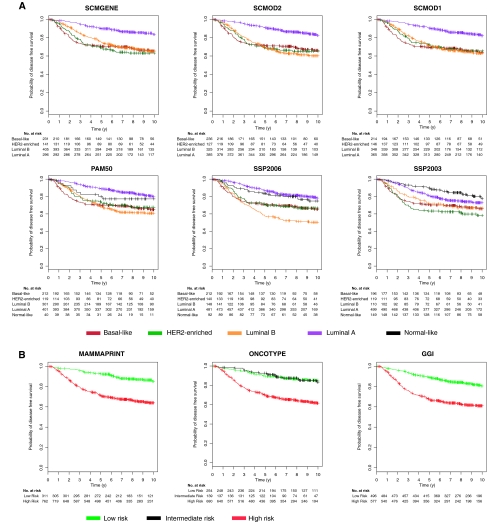
Methods: Thirty-six publicly available breast cancer datasets (n = 5715) were subjected to molecular subtyping using five published classifiers (three SSPs and two SCMs) and SCMGENE, the new three-gene (ER, HER2, and AURKA) SCM. We used the prediction strength statistic to estimate robustness of the classification models, defined as the capacity of a classifier to assign the same tumors to the same subtypes independently of the dataset used to fit it. We used Cohen κ and Cramer V coefficients to assess concordance between the subtype classifiers and association with clinical variables, respectively. We used Kaplan-Meier survival curves and cross-validated partial likelihood to compare prognostic value of the resulting classifications. All statistical tests were two-sided.
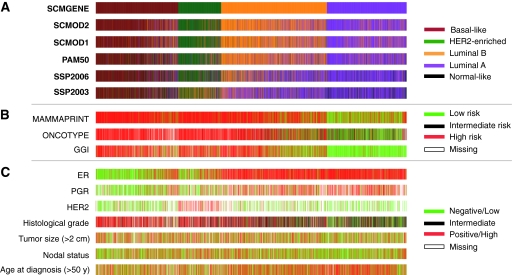
Results: SCMs were statistically significantly more robust than SSPs, with SCMGENE being the most robust because of its simplicity. SCMGENE was statistically significantly concordant with published SCMs (κ = 0.65-0.70) and SSPs (κ = 0.34-0.59), statistically significantly associated with ER (V = 0.64), HER2 (V = 0.52) status, and histological grade (V = 0.55), and yielded similar strong prognostic value.
Conclusion: Our results suggest that adequate classification of the major and clinically relevant molecular subtypes of breast cancer can be robustly achieved with quantitative measurements of three key genes.
Figures
Comment in
-
Gene signatures revisited.J Natl Cancer Inst. 2012 Feb 22;104(4):262-3. doi: 10.1093/jnci/djr557. Epub 2012 Jan 18. J Natl Cancer Inst. 2012. PMID: 22262869 Free PMC article. No abstract available.
References
-
- Desmedt C, Haibe-Kains B, Wirapati P, et al. Biological processes associated with breast cancer clinical outcome depend on the molecular subtypes. Clin Cancer Res. 2008;14(16):5158–5165. - PubMed
-
- Perou CM, Sorlie T, Eisen MB, et al. Molecular portraits of human breast tumours. Nature. 2000;406(6797):747–752. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Research Materials
Miscellaneous
