

Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC)
- PMID: 22309957
- PMCID: PMC3366160
- DOI: 10.1037/a0027127
Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC)
Abstract
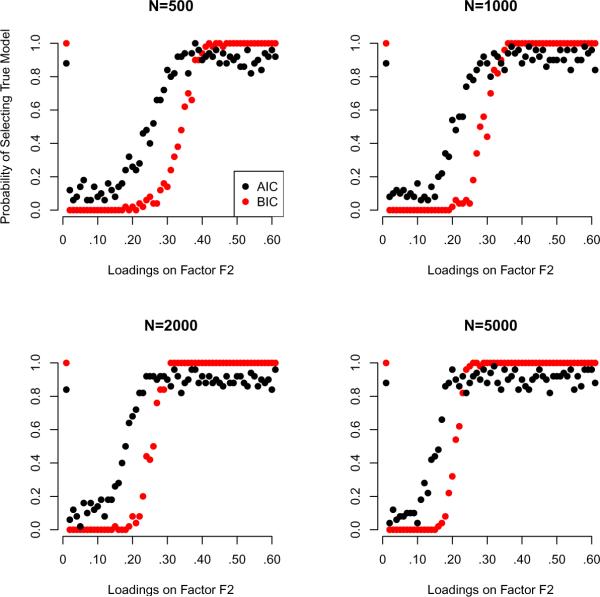
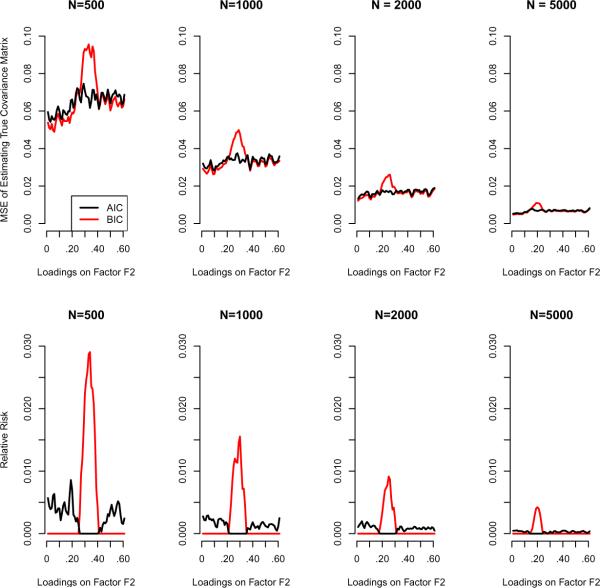
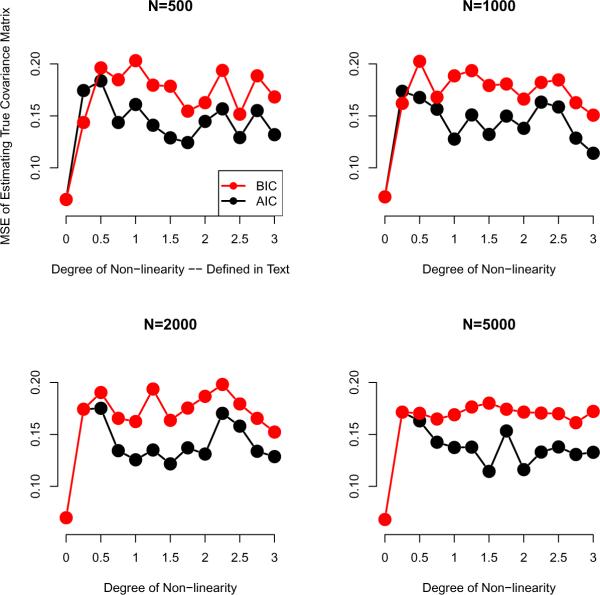
This article reviews the Akaike information criterion (AIC) and the Bayesian information criterion (BIC) in model selection and the appraisal of psychological theory. The focus is on latent variable models, given their growing use in theory testing and construction. Theoretical statistical results in regression are discussed, and more important issues are illustrated with novel simulations involving latent variable models including factor analysis, latent profile analysis, and factor mixture models. Asymptotically, the BIC is consistent, in that it will select the true model if, among other assumptions, the true model is among the candidate models considered. The AIC is not consistent under these circumstances. When the true model is not in the candidate model set the AIC is efficient, in that it will asymptotically choose whichever model minimizes the mean squared error of prediction/estimation. The BIC is not efficient under these circumstances. Unlike the BIC, the AIC also has a minimax property, in that it can minimize the maximum possible risk in finite sample sizes. In sum, the AIC and BIC have quite different properties that require different assumptions, and applied researchers and methodologists alike will benefit from improved understanding of the asymptotic and finite-sample behavior of these criteria. The ultimate decision to use the AIC or BIC depends on many factors, including the loss function employed, the study's methodological design, the substantive research question, and the notion of a true model and its applicability to the study at hand.
(c) 2012 APA, all rights reserved
Figures
References
-
- Akaike H. A new look at the statistical model identification. IEEE Transactions on Automatic Control. 1974;19:716–723.
-
- Anderson D, Burnham K. Avoiding pitfalls when using information-theoretic methods. Journal of Wildlife Management. 2002;66:912–918.
-
- Atkinson A. A note on the generalized information criterion for choice of a model. Biometrika. 1980;67:413–418.
-
- Atkinson A. Likelihood ratios, posterior odds, and information criteria. Journal of Econometrics. 1981;16:15–20.
-
- Barron A, Birgé L, Massart P. Risk bounds for model selection by penalization. Probability Theory and Related Fields. 1999;113:301–413.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
