

Rethinking the role of top-down attention in vision: effects attributable to a lossy representation in peripheral vision
- PMID: 22347200
- PMCID: PMC3272623
- DOI: 10.3389/fpsyg.2012.00013
Rethinking the role of top-down attention in vision: effects attributable to a lossy representation in peripheral vision
Abstract
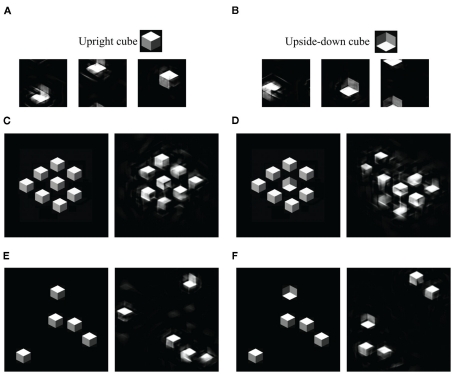
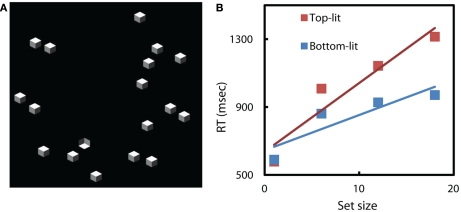
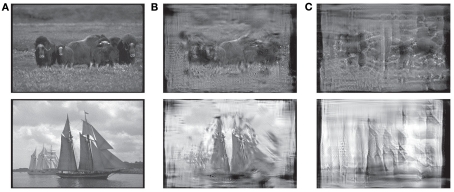
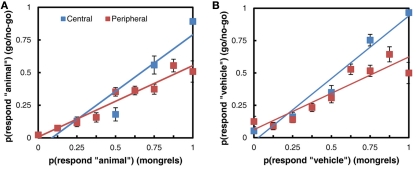
According to common wisdom in the field of visual perception, top-down selective attention is required in order to bind features into objects. In this view, even simple tasks, such as distinguishing a rotated T from a rotated L, require selective attention since they require feature binding. Selective attention, in turn, is commonly conceived as involving volition, intention, and at least implicitly, awareness. There is something non-intuitive about the notion that we might need so expensive (and possibly human) a resource as conscious awareness in order to perform so basic a function as perception. In fact, we can carry out complex sensorimotor tasks, seemingly in the near absence of awareness or volitional shifts of attention ("zombie behaviors"). More generally, the tight association between attention and awareness, and the presumed role of attention on perception, is problematic. We propose that under normal viewing conditions, the main processes of feature binding and perception proceed largely independently of top-down selective attention. Recent work suggests that there is a significant loss of information in early stages of visual processing, especially in the periphery. In particular, our texture tiling model (TTM) represents images in terms of a fixed set of "texture" statistics computed over local pooling regions that tile the visual input. We argue that this lossy representation produces the perceptual ambiguities that have previously been as ascribed to a lack of feature binding in the absence of selective attention. At the same time, the TTM representation is sufficiently rich to explain performance in such complex tasks as scene gist recognition, pop-out target search, and navigation. A number of phenomena that have previously been explained in terms of voluntary attention can be explained more parsimoniously with the TTM. In this model, peripheral vision introduces a specific kind of information loss, and the information available to an observer varies greatly depending upon shifts of the point of gaze (which usually occur without awareness). The available information, in turn, provides a key determinant of the visual system's capabilities and deficiencies. This scheme dissociates basic perceptual operations, such as feature binding, from both top-down attention and conscious awareness.
Keywords: compression; limited capacity; model; peripheral vision; scene perception; search; selective attention.
Figures







References
-
- Allport A. (1993). Attention and control: have we been asking the wrong question? Atten. Perform. 14, 183–219
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources