

Transcriptomic landscape of breast cancers through mRNA sequencing
- PMID: 22355776
- PMCID: PMC3278922
- DOI: 10.1038/srep00264
Transcriptomic landscape of breast cancers through mRNA sequencing
Abstract
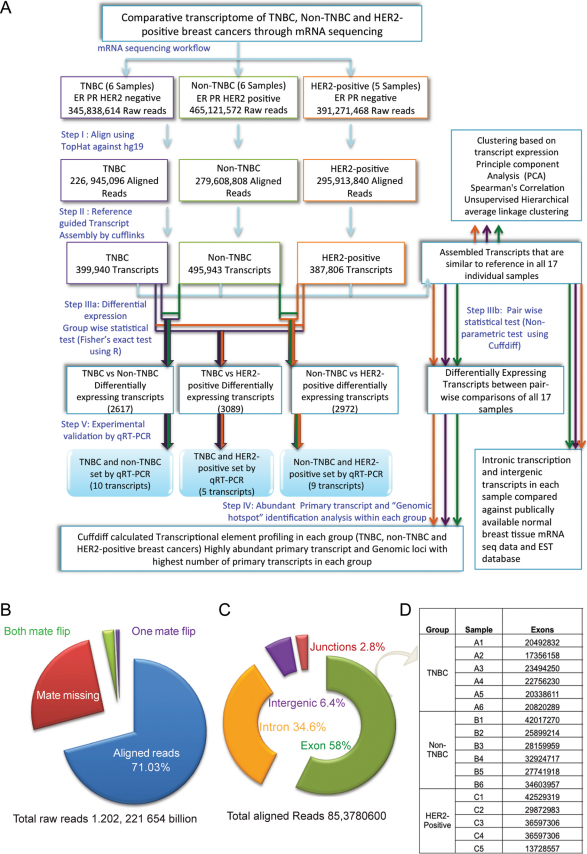
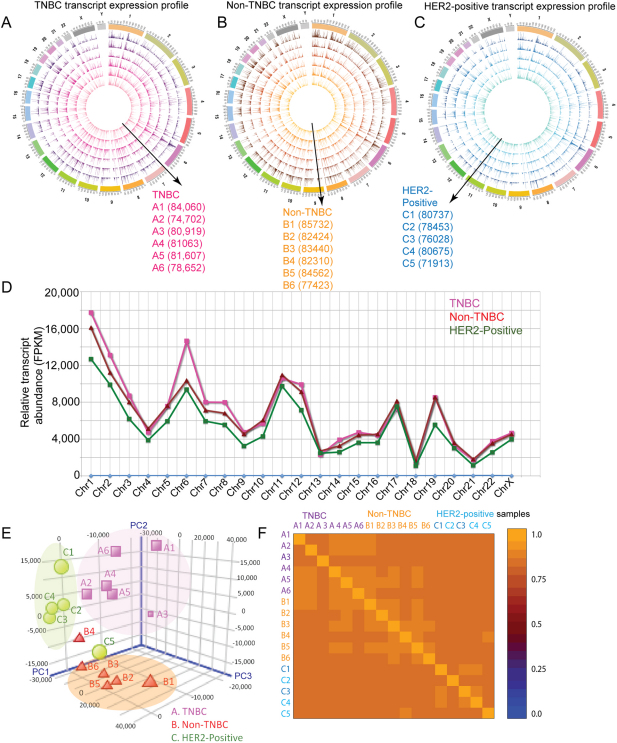
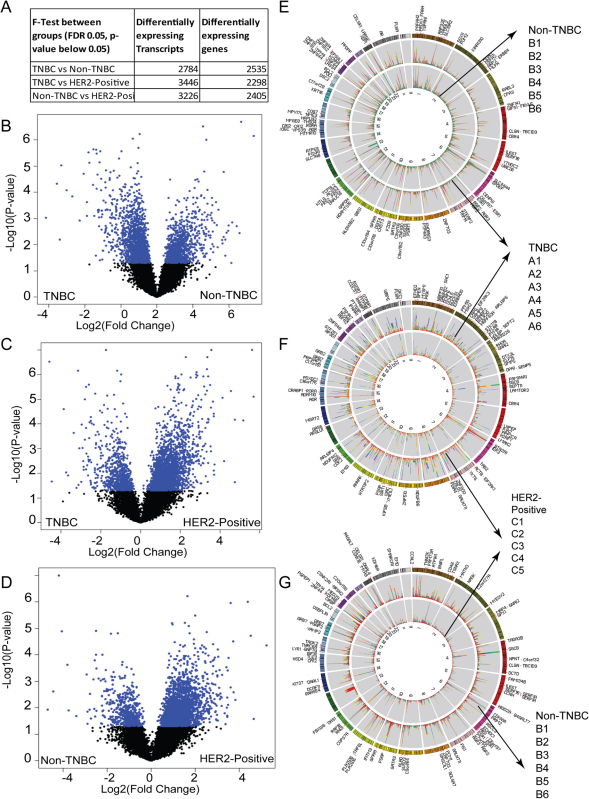
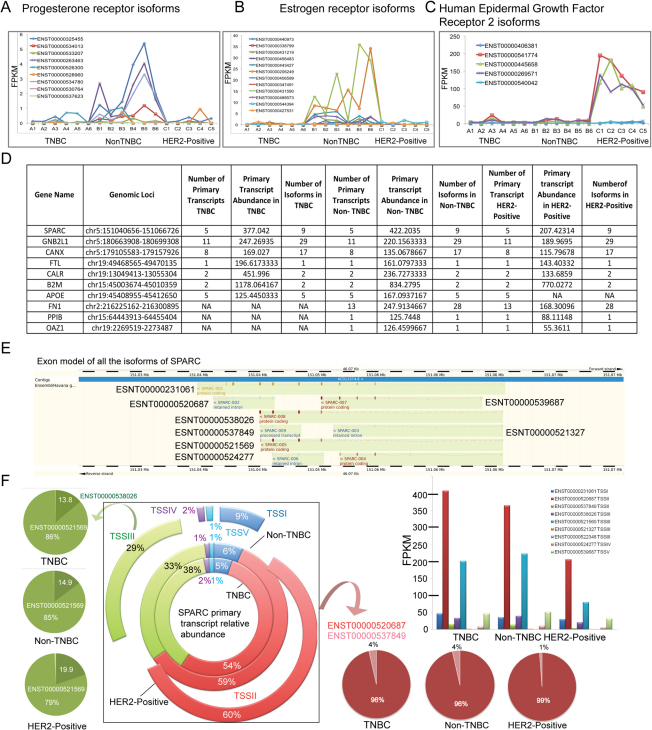
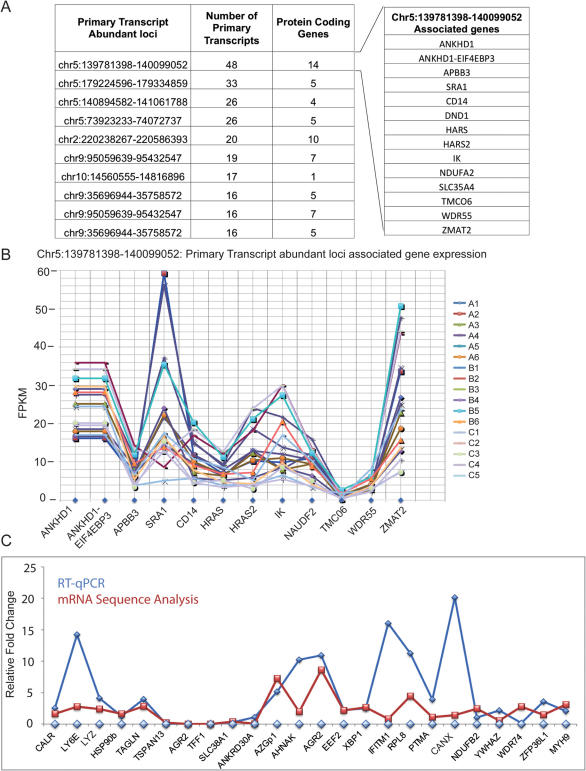
Breast cancer is a heterogeneous disease with a poorly defined genetic landscape, which poses a major challenge in diagnosis and treatment. By massively parallel mRNA sequencing, we obtained 1.2 billion reads from 17 individual human tissues belonging to TNBC, Non-TNBC, and HER2-positive breast cancers and defined their comprehensive digital transcriptome for the first time. Surprisingly, we identified a high number of novel and unannotated transcripts, revealing the global breast cancer transcriptomic adaptations. Comparative transcriptomic analyses elucidated differentially expressed transcripts between the three breast cancer groups, identifying several new modulators of breast cancer. Our study also identified common transcriptional regulatory elements, such as highly abundant primary transcripts, including osteonectin, RACK1, calnexin, calreticulin, FTL, and B2M, and "genomic hotspots" enriched in primary transcripts between the three groups. Thus, our study opens previously unexplored niches that could enable a better understanding of the disease and the development of potential intervention strategies.
Figures
References
-
- Jemal A. et al. Global cancer statistics. CA Cancer J Clin 61, 69–90 (2011). - PubMed
-
- Vargo-Gogola T. & Rosen J. M. Modelling breast cancer: one size does not fit all. Nat Rev Cancer 7, 659–672 (2007). - PubMed
-
- Reis-Filho J. S. & Lakhani S. R. Breast cancer special types: why bother? J Pathol 216, 394–398 (2008). - PubMed
-
- Geyer F. C., Marchio C. & Reis-Filho J. S. The role of molecular analysis in breast cancer. Pathology 41, 77–88 (2009). - PubMed
-
- Weigelt B. & Reis-Filho J. S. Histological and molecular types of breast cancer: is there a unifying taxonomy? Nat Rev Clin Oncol 6, 718–730 (2009). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
Research Materials
Miscellaneous
