

Tracking replicability as a method of post-publication open evaluation
- PMID: 22403538
- PMCID: PMC3293145
- DOI: 10.3389/fncom.2012.00008
Tracking replicability as a method of post-publication open evaluation
Abstract
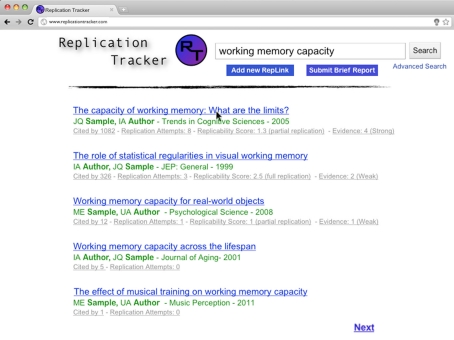
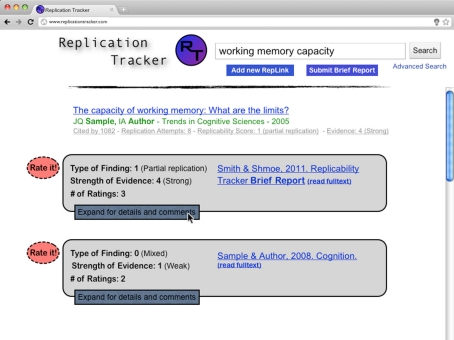
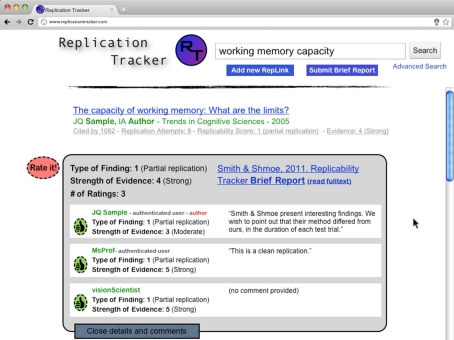
Recent reports have suggested that many published results are unreliable. To increase the reliability and accuracy of published papers, multiple changes have been proposed, such as changes in statistical methods. We support such reforms. However, we believe that the incentive structure of scientific publishing must change for such reforms to be successful. Under the current system, the quality of individual scientists is judged on the basis of their number of publications and citations, with journals similarly judged via numbers of citations. Neither of these measures takes into account the replicability of the published findings, as false or controversial results are often particularly widely cited. We propose tracking replications as a means of post-publication evaluation, both to help researchers identify reliable findings and to incentivize the publication of reliable results. Tracking replications requires a database linking published studies that replicate one another. As any such database is limited by the number of replication attempts published, we propose establishing an open-access journal dedicated to publishing replication attempts. Data quality of both the database and the affiliated journal would be ensured through a combination of crowd-sourcing and peer review. As reports in the database are aggregated, ultimately it will be possible to calculate replicability scores, which may be used alongside citation counts to evaluate the quality of work published in individual journals. In this paper, we lay out a detailed description of how this system could be implemented, including mechanisms for compiling the information, ensuring data quality, and incentivizing the research community to participate.
Keywords: open evaluation; post-publication evaluation; replicability; replication.
Figures
References
-
- Adamic L. A., Zhang J., Bakshy E., Ackerman M. S. (2008). “Knowledge sharing and yahoo answers: everyone knows something,” in Proceedings of the 17th International Conference on World Wide Web, Beijing
-
- Armitage P., McPherson C. K., Rowe B. C. (1969). Repeated significance tests on accumulating data. J. R. Stat. Soc. Ser. A Stat. Soc. 132, 235–244
-
- Baayen R. H., Davidson D. J., Bates D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412 10.1016/j.jml.2007.12.005 - DOI
-
- Bederson B. B., Hu C., Resnik P. (2010). “Translation by interactive collaboration between monolingual users,” in Proceedings of Graphics Interface, Ottawa, 39–46
LinkOut - more resources
Full Text Sources
Research Materials