

Different timescales for the neural coding of consonant and vowel sounds
- PMID: 22426334
- PMCID: PMC3563339
- DOI: 10.1093/cercor/bhs045
Different timescales for the neural coding of consonant and vowel sounds
Abstract
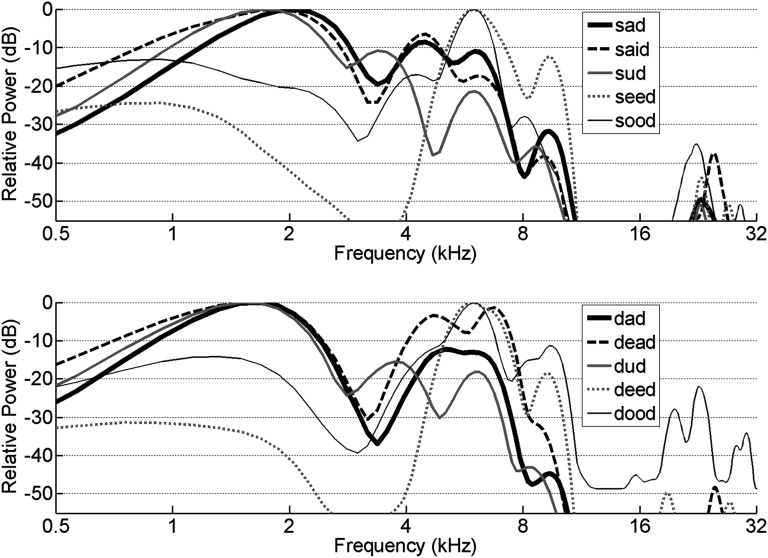
Psychophysical, clinical, and imaging evidence suggests that consonant and vowel sounds have distinct neural representations. This study tests the hypothesis that consonant and vowel sounds are represented on different timescales within the same population of neurons by comparing behavioral discrimination with neural discrimination based on activity recorded in rat inferior colliculus and primary auditory cortex. Performance on 9 vowel discrimination tasks was highly correlated with neural discrimination based on spike count and was not correlated when spike timing was preserved. In contrast, performance on 11 consonant discrimination tasks was highly correlated with neural discrimination when spike timing was preserved and not when spike timing was eliminated. These results suggest that in the early stages of auditory processing, spike count encodes vowel sounds and spike timing encodes consonant sounds. These distinct coding strategies likely contribute to the robust nature of speech sound representations and may help explain some aspects of developmental and acquired speech processing disorders.
Figures











References
-
- Anderson SE, Kilgard MP, Sloan AM, Rennaker RL. Response to broadband repetitive stimuli in auditory cortex of the unanesthetized rat. Hear Res. 2006;213:107–117. - PubMed
-
- Binder JR, Frost JA, Hammeke TA, Bellgowan PS, Springer JA, Kaufman JN, Possing ET. Human temporal lobe activation by speech and nonspeech sounds. Cereb Cortex. 2000;10:512–528. - PubMed
-
- Boatman D, Hall C, Goldstein MH, Lesser R, Gordon B. Neuroperceptual differences in consonant and vowel discrimination: as revealed by direct cortical electrical interference. Cortex. 1997;33:83–98. - PubMed
-
- Boatman D, Lesser R, Gordon B. Auditory speech processing in the left temporal lobe: an electrical interference study. Brain Lang. 1995;51:269–290. - PubMed
-
- Boatman D, Lesser R, Hall C, Gordon B. Auditory perception of segmental features: a functional neuroanatomic study. J Neurolinguistics. 1994;8:225–234.
