

A hybrid human and machine resource curation pipeline for the Neuroscience Information Framework
- PMID: 22434839
- PMCID: PMC3308161
- DOI: 10.1093/database/bas005
A hybrid human and machine resource curation pipeline for the Neuroscience Information Framework
Abstract
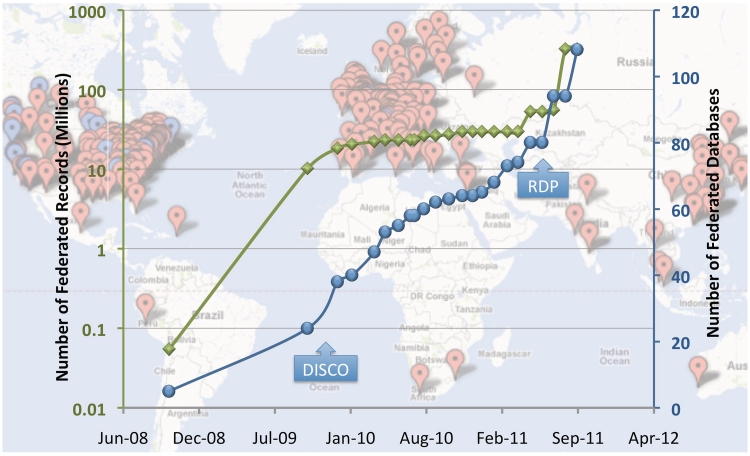
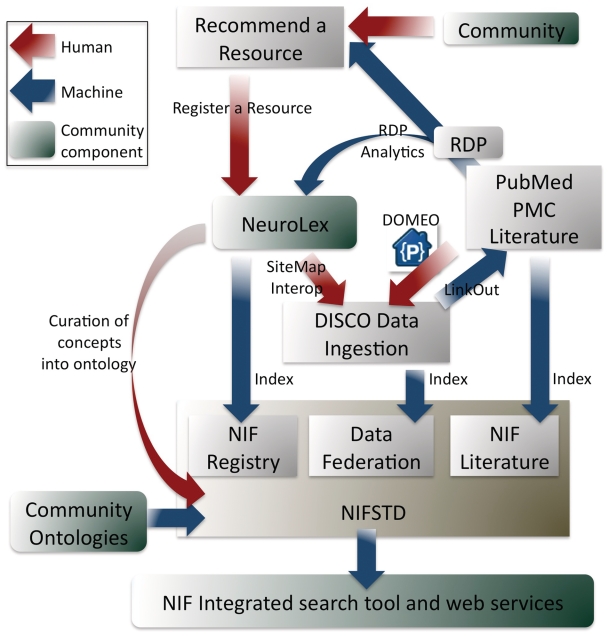
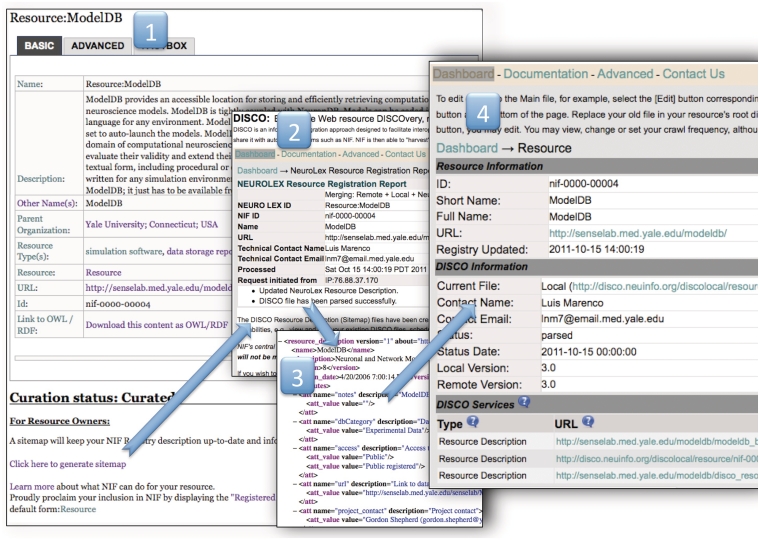
The breadth of information resources available to researchers on the Internet continues to expand, particularly in light of recently implemented data-sharing policies required by funding agencies. However, the nature of dense, multifaceted neuroscience data and the design of contemporary search engine systems makes efficient, reliable and relevant discovery of such information a significant challenge. This challenge is specifically pertinent for online databases, whose dynamic content is 'hidden' from search engines. The Neuroscience Information Framework (NIF; http://www.neuinfo.org) was funded by the NIH Blueprint for Neuroscience Research to address the problem of finding and utilizing neuroscience-relevant resources such as software tools, data sets, experimental animals and antibodies across the Internet. From the outset, NIF sought to provide an accounting of available resources, whereas developing technical solutions to finding, accessing and utilizing them. The curators therefore, are tasked with identifying and registering resources, examining data, writing configuration files to index and display data and keeping the contents current. In the initial phases of the project, all aspects of the registration and curation processes were manual. However, as the number of resources grew, manual curation became impractical. This report describes our experiences and successes with developing automated resource discovery and semiautomated type characterization with text-mining scripts that facilitate curation team efforts to discover, integrate and display new content. We also describe the DISCO framework, a suite of automated web services that significantly reduce manual curation efforts to periodically check for resource updates. Lastly, we discuss DOMEO, a semi-automated annotation tool that improves the discovery and curation of resources that are not necessarily website-based (i.e. reagents, software tools). Although the ultimate goal of automation was to reduce the workload of the curators, it has resulted in valuable analytic by-products that address accessibility, use and citation of resources that can now be shared with resource owners and the larger scientific community. DATABASE URL: http://neuinfo.org.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
