

Tracking and coordinating an international curation effort for the CCDS Project
- PMID: 22434842
- PMCID: PMC3308164
- DOI: 10.1093/database/bas008
Tracking and coordinating an international curation effort for the CCDS Project
Abstract
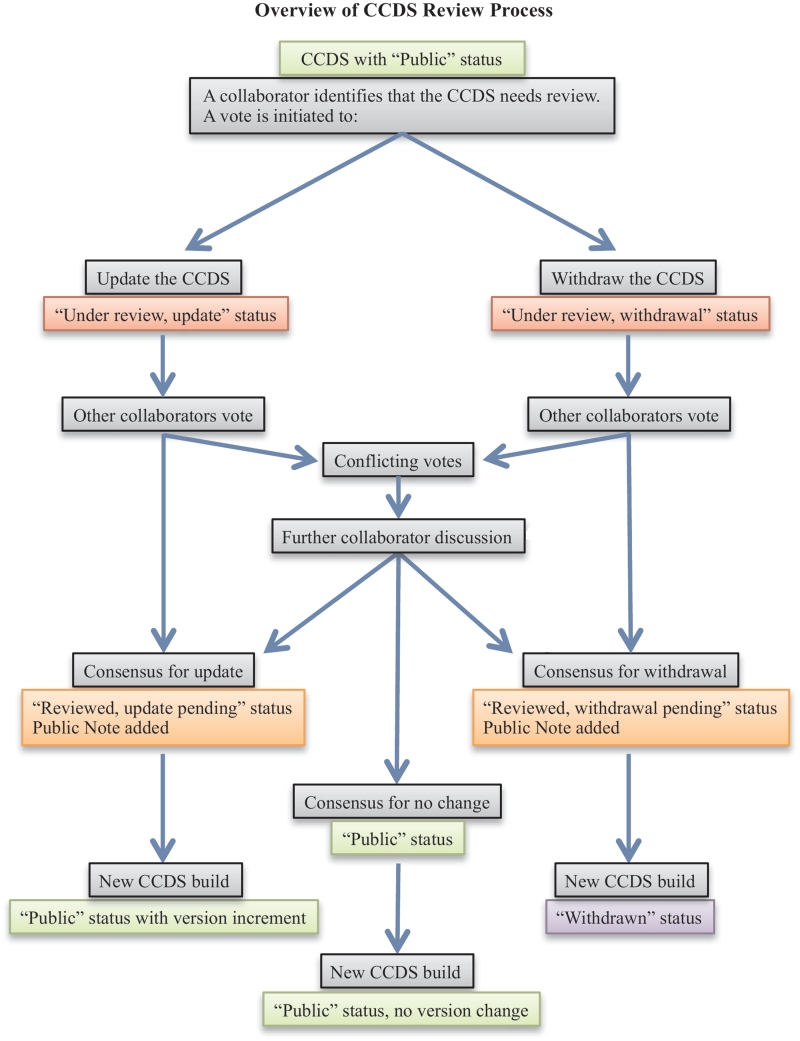
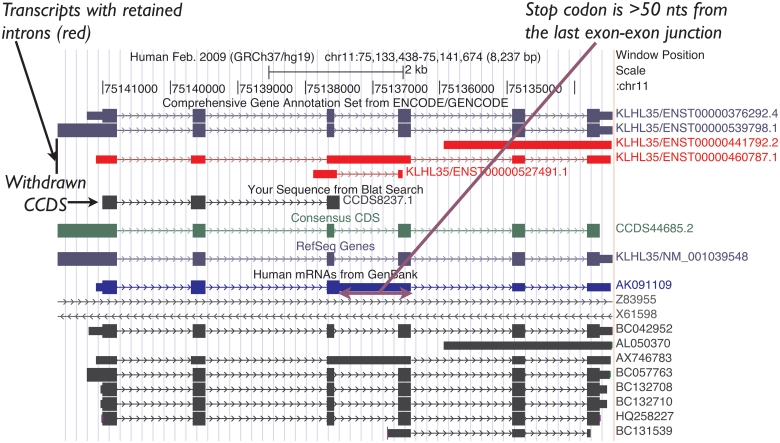
The Consensus Coding Sequence (CCDS) collaboration involves curators at multiple centers with a goal of producing a conservative set of high quality, protein-coding region annotations for the human and mouse reference genome assemblies. The CCDS data set reflects a 'gold standard' definition of best supported protein annotations, and corresponding genes, which pass a standard series of quality assurance checks and are supported by manual curation. This data set supports use of genome annotation information by human and mouse researchers for effective experimental design, analysis and interpretation. The CCDS project consists of analysis of automated whole-genome annotation builds to identify identical CDS annotations, quality assurance testing and manual curation support. Identical CDS annotations are tracked with a CCDS identifier (ID) and any future change to the annotated CDS structure must be agreed upon by the collaborating members. CCDS curation guidelines were developed to address some aspects of curation in order to improve initial annotation consistency and to reduce time spent in discussing proposed annotation updates. Here, we present the current status of the CCDS database and details on our procedures to track and coordinate our efforts. We also present the relevant background and reasoning behind the curation standards that we have developed for CCDS database treatment of transcripts that are nonsense-mediated decay (NMD) candidates, for transcripts containing upstream open reading frames, for identifying the most likely translation start codons and for the annotation of readthrough transcripts. Examples are provided to illustrate the application of these guidelines. DATABASE URL: http://www.ncbi.nlm.nih.gov/CCDS/CcdsBrowse.cgi.
Figures

References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
